Предполагам, че причината е, че те просто не са сметнали това за приоритетна функция, която си струва да бъде внедрена. Изглежда, че Postgres прави поддържайте и двете
UNION и UNION ALL .
Ако имате основания за тази функция, можете да предоставите обратна връзка на Connect (или какъвто и да е URL адресът на неговата замяна).
Предотвратяването на добавянето на дубликати може да бъде полезно, тъй като дублиран ред, добавен в по-късна стъпка към предишен, почти винаги ще доведе до безкраен цикъл или надвишаване на ограничението за максимална рекурсия.
Има доста места в SQL стандартите
където се използва код, демонстриращ UNION като например по-долу
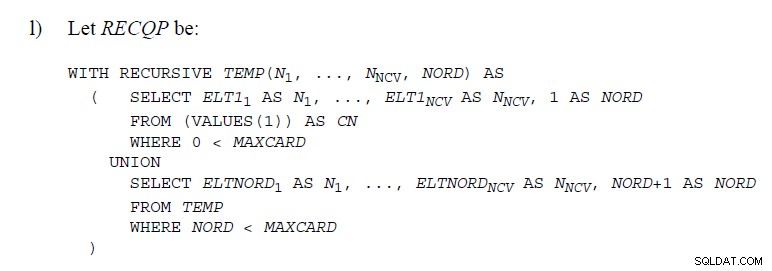
Тази статия обяснява как те са внедрени в SQL Server . Те не правят нищо подобно "под капака". Макарата на стека изтрива редове, докато върви, така че не би било възможно да се знае дали по-късен ред е дубликат на изтрит. Поддържа UNION ще се нуждае от малко по-различен подход.
Междувременно можете доста лесно да постигнете същото в TVF с множество изявления.
Да вземем глупав пример по-долу (Postgres Fiddle )
WITH R
AS (SELECT 0 AS N
UNION
SELECT ( N + 1 )%10
FROM R)
SELECT N
FROM R
Промяна на UNION към UNION ALL и добавяне на DISTINCT в края няма да ви спаси от безкрайната рекурсия.
Но можете да приложите това като
CREATE FUNCTION dbo.F ()
RETURNS @R TABLE(n INT PRIMARY KEY WITH (IGNORE_DUP_KEY = ON))
AS
BEGIN
INSERT INTO @R
VALUES (0); --anchor
WHILE @@ROWCOUNT > 0
BEGIN
INSERT INTO @R
SELECT ( N + 1 )%10
FROM @R
END
RETURN
END
GO
SELECT *
FROM dbo.F ()
Горното използва IGNORE_DUP_KEY за изхвърляне на дубликати. Ако списъкът с колони е твърде широк, за да бъде индексиран, ще ви трябва DISTINCT и NOT EXISTS вместо. Вероятно бихте искали също параметър за задаване на максималния брой рекурсии и избягване на безкрайни цикли.