Същността на въпроса не е "защо редът има значение за LINQ?". LINQ просто превежда буквално без пренареждане. Истинският въпрос е "защо двете SQL заявки имат различна производителност?".
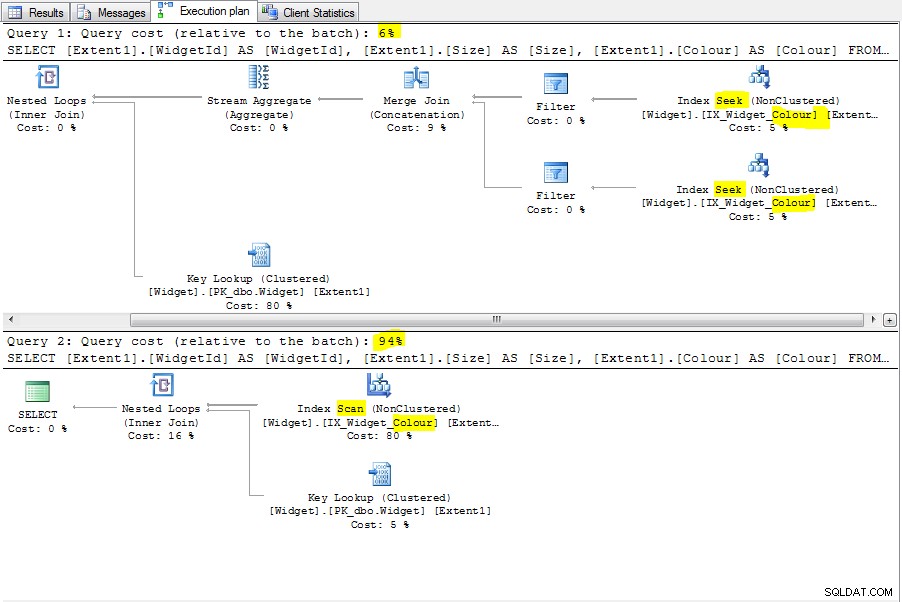
Успях да възпроизведа проблема, като вмъкнах само 100k реда. В този случай се задейства слабост в оптимизатора:той не разпознава, че може да извърши търсене на Colour поради сложното състояние. В първата заявка оптимизаторът разпознава шаблона и създава търсене в индекс.
Няма семантична причина защо това трябва да бъде. Търсене в индекс е възможно дори когато се търси в NULL . Това е слабост/бъг в оптимизатора. Ето двата плана:
EF се опитва да бъде полезен тук, защото предполага, че както колоната, така и филтърната променлива могат да бъдат нула. В този случай той се опитва да ви даде съвпадение (което според семантиката на C# е правилното нещо).
Опитах се да отменя това, като добавих следния филтър:
Colour IS NOT NULL AND @p__linq__0 IS NOT NULL
AND Size IS NOT NULL AND @p__linq__1 IS NOT NULL
Надявайки се, че оптимизаторът сега използва това знание, за да опрости сложния израз на EF филтъра. Не успя да го направи. Ако това беше проработило, същият филтър можеше да бъде добавен към EF заявката, осигурявайки лесно решение.
Ето поправките, които препоръчвам в реда, в който трябва да ги изпробвате:
- Направете колоните на базата данни ненулеви в базата данни
- Направете колоните ненулеви в EF модела на данни, като се надявате, че това ще попречи на EF да създаде сложното филтърно условие
- Създаване на индекси:
Colour, Sizeи/илиSize, Colour. Те също премахват проблема им. - Уверете се, че филтрирането е извършено в правилния ред и оставете коментар за кода
- Опитайте да използвате
INTERSECT/Queryable.Intersectза комбиниране на филтрите. Това често води до различни форми на план. - Създайте вградена таблична функция, която извършва филтрирането. EF може да използва такава функция като част от по-голяма заявка
- Падане до необработен SQL
- Използвайте ръководство за план, за да промените плана
Всичко това са заобиколни решения, а не корекции на първопричината.
В крайна сметка не съм доволен както от SQL Server, така и от EF тук. И двата продукта трябва да бъдат коригирани. Уви, те вероятно няма да бъдат и вие също нямате търпение за това.
Ето скриптовете за индексиране:
CREATE NONCLUSTERED INDEX IX_Widget_Colour_Size ON dbo.Widget
(
Colour, Size
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
CREATE NONCLUSTERED INDEX IX_Widget_Size_Colour ON dbo.Widget
(
Size, Colour
) WITH( STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]