Операторите ROLLUP и CUBE се използват за връщане на резултати, обобщени от колоните в клаузата GROUP BY.
Функциите GROUPING и GROUPING_ID се използват, за да се идентифицира дали колоните в списъка GROUP BY са агрегирани (с помощта на операторите ROLLUP или CUBE) или не.
Има две основни разлики между функциите GROUPING и GROUPING_ID.
Те са както следва:
- Функцията GROUPING е приложима за една колона, докато списъкът с колони за функцията GROUPING_ID трябва да съвпада със списъка с колони в клаузата GROUP BY.
- Функцията GROUPING показва дали колона в списъка GROUP BY е обобщена или не. Връща 1, ако наборът от резултати е обобщен и 0, ако наборът от резултати не е агрегиран.
От друга страна, функцията GROUPING_ID също връща цяло число. Въпреки това, той извършва преобразуване в двоично в десетично число след обединяване на резултата от всички функции GROUPING.
В тази статия ще видим функциите GROUPING и GROUPING_ID в действие с помощта на примери.
Подготовка на някои фиктивни данни
Както винаги, нека създадем някои фиктивни данни, които ще използваме за примера, с който ще работим в тази статия.
Изпълнете следния скрипт:
CREATE Database company;
USE company;
CREATE TABLE employee
(
id INT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
gender VARCHAR(50) NOT NULL,
salary INT NOT NULL,
department VARCHAR(50) NOT NULL
)
INSERT INTO employee
VALUES
(1, 'David', 'Male', 5000, 'Sales'),
(2, 'Jim', 'Female', 6000, 'HR'),
(3, 'Kate', 'Female', 7500, 'IT'),
(4, 'Will', 'Male', 6500, 'Marketing'),
(5, 'Shane', 'Female', 5500, 'Finance'),
(6, 'Shed', 'Male', 8000, 'Sales'),
(7, 'Vik', 'Male', 7200, 'HR'),
(8, 'Vince', 'Female', 6600, 'IT'),
(9, 'Jane', 'Female', 5400, 'Marketing'),
(10, 'Laura', 'Female', 6300, 'Finance'),
(11, 'Mac', 'Male', 5700, 'Sales'),
(12, 'Pat', 'Male', 7000, 'HR'),
(13, 'Julie', 'Female', 7100, 'IT'),
(14, 'Elice', 'Female', 6800,'Marketing'),
(15, 'Wayne', 'Male', 5000, 'Finance')
В скрипта по-горе създадохме база данни с име „Компания“. След това създадохме таблица „Служител“ в базата данни на компанията. И накрая, вмъкнахме някои фиктивни записи в таблицата на служителите.
Функция ГРУПИРАНЕ
Както бе споменато по-горе, функцията GROUPING връща 1, ако наборът от резултати е агрегиран, и 0, ако наборът от резултати не е агрегиран.
Разгледайте следния скрипт, за да видите функцията GROUPING в действие.
SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, GROUPING(department) as GP_Department, GROUPING(gender) as GP_Gender FROM employee GROUP BY ROLLUP (department, gender)
Скриптът по-горе отчита сбора на заплатите на всички служители мъже и жени, които са групирани първо в колоната Отдел и след това в колоната Пол. Добавени са още две колони, за да се покаже резултатът от функцията ГРУПИРАНЕ, приложена към колоните Отдел и Пол.
Операторът ROLLUP се използва за показване на сумата на заплатите под формата на общи и междинни суми.
Резултатът от скрипта по-горе изглежда така.
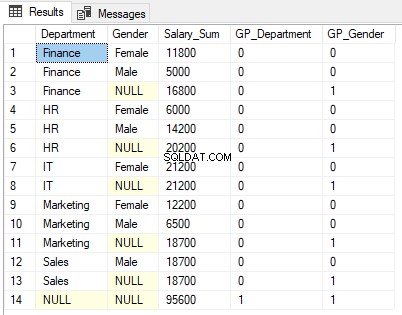
Погледнете внимателно изхода. Сумата на заплатите се показва по пол по пол на отдели (редове 1, 2, 4, 5, 7, 9, 10 и 12). След това също се обобщава само по пол (редове 3, 6, 8, 11 и 13). И накрая, общата сума на заплатите, обобщена както по отдел, така и по пол, се показва на ред 14.
1 се показва в колоната на функцията GROUPING GP_Gender за редове, където резултатите са обобщени по пол, т.е. редове 3, 6, 8, 11 и 13. Това е така, защото колоната GP_Gender съдържа резултата от функцията GROUPING, приложена към колоната Gender.
По същия начин, ред 14 съдържа обобщената сума на всички отдели и всички колони. Следователно 1 се връща както за колоните GP_Department, така и за GP_Gender.
Можете да видите, че NULL се показва в колоните Отдел и Пол в изхода, където резултатите се обобщават. Например в ред 3, NULL се показва в колоната Пол, тъй като резултатите са обобщени по колона за пол и така няма стойност на колоната за показване. Не искаме нашите потребители да виждат NULL, по-добра дума тук може да бъде „Всички полове“.
За да направим това, трябва да модифицираме нашия скрипт, както следва:
SELECT CASE WHEN GROUPING(department) = 1 THEN 'All Departments' ELSE ISNULL(department, 'Unknown') END as Department, CASE WHEN GROUPING(gender) = 1 THEN 'All Genders' ELSE ISNULL(gender, 'Unknown') END as Gender, sum(salary) as Salary_Sum FROM employee GROUP BY ROLLUP (department, gender)
В скрипта по-горе, ако функцията ГРУПИРАНЕ, приложена към колоната Отдел, връща 1 и „Всички отдели“ се показва в колоната Отдел. В противен случай, ако колоната Отдел съдържа стойност NULL, тогава тя ще покаже „Неизвестно“. Колоната за пол е променена по същия начин.
Изпълнението на скрипта по-горе връща следните резултати:
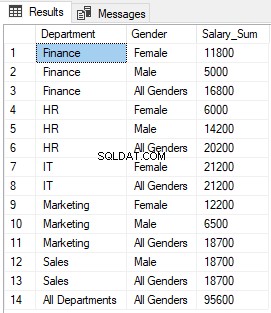
Можете да видите, че NULL в колоните Department и Gender, където функцията GROUPING връща 1, е заменено с „Всички отдели“ и „Всички полове“ съответно.
Функция GROUPING_ID
Функцията GROUPING_ID конкатенира изхода на функциите GROUPING, приложени към всички колони, посочени в клаузата GROUP BY. След това извършва двоично преобразуване в десетично число, преди да върне крайния изход.
Нека първо да конкатенираме изхода, върнат от функцията GROUPING, приложена към колоните Department и Gender. Разгледайте следния скрипт:
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping FROM employee GROUP BY ROLLUP (department, gender)
В изхода ще видите 0s и 1s, върнати от функцията GROUPING, свързани заедно. Резултатът изглежда така:
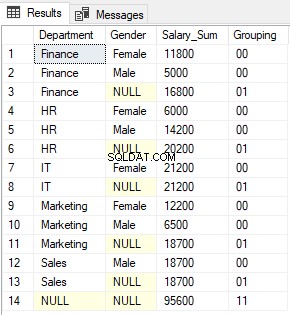
Функцията GROUPING_ID просто връща десетичния еквивалент на двоичната стойност, образувана в резултат на конкатенацията на стойностите, върнати от функциите GROUPING.
Изпълнете следния скрипт, за да видите функцията GROUPING ID в действие:
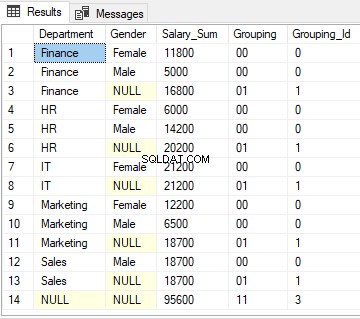
USE company SELECT department AS Department, gender AS Gender, sum(salary) as Salary_Sum, CAST(GROUPING(department) AS VARCHAR(1)) + CAST(GROUPING(gender) AS VARCHAR (1)) as Grouping, GROUPING_ID(department, gender) as Grouping_Id FROM employee GROUP BY ROLLUP (department, gender)
За ред 1 функцията GROUPING ID ще върне 0, тъй като десетичният еквивалент на „00“ е нула.
За редове 3, 6, 8, 11 и 13 функцията GROUPING_ID връща 1, тъй като десетичният еквивалент на „01“ е 1.
И накрая, за ред 14, функцията GROUPIND_ID връща 3, тъй като двоичният еквивалент на „11“ е 3.
Резултатът от скрипта по-горе изглежда така:
Вижте също:
Microsoft:Общ преглед на Grouping_ID
Microsoft:Общ преглед на групирането
YouTube:Групиране и групиране_ID