Проблемите със забавянето на репликацията в PostgreSQL не са широко разпространен проблем за повечето настройки. Въпреки това, това може да се случи и когато се случи, може да повлияе на вашите производствени настройки. PostgreSQL е проектиран да обработва множество нишки, като паралелизъм на заявки или разгръщане на работни нишки за обработка на специфични задачи въз основа на присвоените стойности в конфигурацията. PostgreSQL е проектиран да се справя с тежки и натоварващи натоварвания, но понякога (поради лоша конфигурация) сървърът ви все пак може да отиде на юг.
Идентифицирането на забавянето на репликацията в PostgreSQL не е сложна задача, но има няколко различни подхода за разглеждане на проблема. В този блог ще разгледаме какви неща да гледаме, когато вашата PostgreSQL репликация изостава.
Типове репликация в PostgreSQL
Преди да се потопим в темата, нека първо да видим как се развива репликацията в PostgreSQL, тъй като има разнообразен набор от подходи и решения, когато се занимаваме с репликация.
Топъл режим на готовност за PostgreSQL беше внедрен във версия 8.2 (през 2006 г.) и се базираше на метода за доставка на регистрационни файлове. Това означава, че WAL записите се преместват директно от един сървър на база данни на друг, за да бъдат приложени, или просто аналогичен подход на PITR, или много подобно на това, което правите с rsync.
Този подход, дори стар, все още се използва днес и някои институции всъщност предпочитат този по-стар подход. Този подход реализира базирана на файлове доставка на регистрационни файлове чрез прехвърляне на WAL записи един файл (WAL сегмент) наведнъж. Въпреки че има недостатък; Голяма повреда на основните сървъри, транзакциите, които все още не са изпратени, ще бъдат загубени. Има прозорец за загуба на данни (можете да настроите това, като използвате параметъра archive_timeout, който може да бъде настроен на само няколко секунди, но такава ниска настройка значително ще увеличи честотната лента, необходима за изпращане на файлове).
В PostgreSQL версия 9.0 беше въведена поточно репликация. Тази функция ни позволи да останем по-актуални в сравнение с доставката на дневници, базирана на файлове. Неговият подход е чрез прехвърляне на WAL записи (WAL файлът се състои от WAL записи) в движение (само доставка на дневник, базирана на записи), между главен сървър и един или няколко резервни сървъра. Този протокол не трябва да чака за попълване на WAL файла, за разлика от доставката на дневници, базирана на файлове. На практика процес, наречен WAL приемник, изпълняващ се на сървъра в режим на готовност, ще се свърже с основния сървър чрез TCP/IP връзка. В основния сървър съществува друг процес с име WAL изпращач. Ролята му отговаря за изпращането на WAL регистрите до резервния(ите) сървър(и), когато се случват.
Настройките на асинхронната репликация при поточно репликация могат да създадат проблеми като загуба на данни или забавяне на подчинените, така че версия 9.1 въвежда синхронна репликация. При синхронна репликация, всяко записване на транзакция за запис ще изчака, докато бъде получено потвърждение, че записването е било записано в регистъра за предварителна запис на диска както на първичния, така и на резервния сървър. Този метод минимизира възможността от загуба на данни, тъй като за да се случи това, ще трябва да се повредят едновременно и главният, и резервният.
Очевидният недостатък на тази конфигурация е, че времето за отговор за всяка транзакция на запис се увеличава, тъй като трябва да изчакаме, докато всички страни отговорят. За разлика от MySQL, няма поддръжка, като например в полусинхронна среда на MySQL, тя ще се върне към асинхронна, ако е настъпило изчакване. Така че в PostgreSQL времето за комит е (най-малкото) двупосочното пътуване между първичния и резервния. Транзакциите само за четене няма да бъдат засегнати от това.
С развитието си PostgreSQL непрекъснато се подобрява и въпреки това репликацията му е разнообразна. Например, можете да използвате асинхронна репликация на физическо поточно предаване или да използвате логическа поточно репликация. И двете се наблюдават по различен начин, въпреки че използват един и същ подход при изпращане на данни през репликация, която все още е поточно репликация. За повече подробности проверете в ръководството за различни типове решения в PostgreSQL, когато се занимавате с репликация.
Причини за забавяне на репликацията на PostgreSQL
Както е дефинирано в предишния ни блог, забавянето на репликацията е цената на закъснението за транзакция(и) или операция(и), изчислена от нейната времева разлика на изпълнение между първичния/главния спрямо резервния/подчинения възел.
Тъй като PostgreSQL използва поточно репликация, той е проектиран да бъде бърз, тъй като промените се записват като набор от последователност от записи в дневника (байт по байт), както са прихванати от WAL приемника, след което записва тези регистрационни записи към WAL файла. След това процесът на стартиране от PostgreSQL възпроизвежда данните от този сегмент на WAL и започва стрийминг репликацията. В PostgreSQL забавянето на репликацията може да възникне поради следните фактори:
- Проблеми с мрежата
- Не мога да намеря сегмента WAL от основния. Обикновено това се дължи на поведението на контролни точки, при което WAL сегментите се завъртат или рециклират.
- Заети възли (основни и в готовност(и)). Може да бъде причинено от външни процеси или някои лоши заявки, причинени от интензивно използване на ресурси
- Лош хардуер или хардуерни проблеми, причиняващи известно забавяне
- Лоша конфигурация в PostgreSQL, като например малък брой max_wal_senders, които се задават по време на обработка на тонове заявки за транзакции (или голям обем промени).
Какво да търсите при забавяне на репликацията на PostgreSQL
Репликацията на PostgreSQL е все още разнообразна, но наблюдението на здравето на репликацията е фино, но не е сложно. В този подход ще покажем, че се базират на настройка в първичен режим на готовност с асинхронна стрийминг репликация. Логическата репликация не може да е от полза за повечето случаи, които обсъждаме тук, но изгледът pg_stat_subscription може да ви помогне да събирате информация. В този блог обаче няма да се фокусираме върху това.
Използване на pg_stat_replication View
Най-често срещаният подход е да се изпълни заявка, препращаща към този изглед в основния възел. Не забравяйте, че можете да събирате информация само от основния възел, като използвате този изглед. Този изглед съдържа следната дефиниция на таблица, базирана на PostgreSQL 11, както е показано по-долу:
postgres=# \d pg_stat_replication
View "pg_catalog.pg_stat_replication"
Column | Type | Collation | Nullable | Default
------------------+--------------------------+-----------+----------+---------
pid | integer | | |
usesysid | oid | | |
usename | name | | |
application_name | text | | |
client_addr | inet | | |
client_hostname | text | | |
client_port | integer | | |
backend_start | timestamp with time zone | | |
backend_xmin | xid | | |
state | text | | |
sent_lsn | pg_lsn | | |
write_lsn | pg_lsn | | |
flush_lsn | pg_lsn | | |
replay_lsn | pg_lsn | | |
write_lag | interval | | |
flush_lag | interval | | |
replay_lag | interval | | |
sync_priority | integer | | |
sync_state | text | | | Където полетата са дефинирани като (включва PG <10 версия),
- pid :Идентификатор на процес на walsender процес
- usesysid :OID на потребителя, който се използва за поточно репликация.
- потребителско име :Име на потребител, който се използва за поточно репликация
- име_на_приложение :Име на приложението, свързано с главен
- адрес_клиент :Адрес на репликация в режим на готовност/поточно предаване
- име на_хост на клиента :Име на хост в режим на готовност.
- пристанище_клиент :Номер на TCP порт, на който в режим на готовност комуникира с подателя на WAL
- backend_start :Начален час, когато SR се свърже към главен.
- backend_xmin :Xmin хоризонт на готовност, докладван от hot_standby_feedback.
- състояние :Текущо състояние на изпращача на WAL, т.е. поточно предаване
- sent_lsn /изпратено_местоположение :Местоположението на последната транзакция е изпратено в режим на готовност.
- write_lsn /местоположение_за_писване :Последна транзакция, записана на диск в режим на готовност
- flush_lsn /flush_location :Последна транзакция изтриване на диска в режим на готовност.
- replay_lsn /replay_location :Последна транзакция изтриване на диска в режим на готовност.
- write_lag :Изминало време по време на ангажирани WAL от първичен до режим на готовност (но все още не е ангажиран в режим на готовност)
- flush_lag :Изминало време по време на ангажирани WAL от първичния към режим на готовност (WAL вече е прочистен, но все още не е приложен)
- replay_lag :Изминало време по време на ангажирани WAL-и от първичния към режим на готовност (напълно ангажиран в възел в режим на готовност)
- sync_priority :Приоритетът на сървъра в режим на готовност е избран като синхронен режим на готовност
- sync_state :Състояние на синхронизиране на готовност (асинхронно ли е или синхронно).
Примерна заявка ще изглежда по следния начин в PostgreSQL 9.6,
paultest=# select * from pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 7174
usesysid | 16385
usename | cmon_replication
application_name | pgsql_1_node_1
client_addr | 192.168.30.30
client_hostname |
client_port | 10580
backend_start | 2020-02-20 18:45:52.892062+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | async
-[ RECORD 2 ]----+------------------------------
pid | 7175
usesysid | 16385
usename | cmon_replication
application_name | pgsql_80_node_2
client_addr | 192.168.30.20
client_hostname |
client_port | 60686
backend_start | 2020-02-20 18:45:52.899446+00
backend_xmin |
state | streaming
sent_location | 1/9FD5D78
write_location | 1/9FD5D78
flush_location | 1/9FD5D78
replay_location | 1/9FD5D78
sync_priority | 0
sync_state | asyncТова основно ви казва какви блокове от местоположение в сегментите на WAL, които са били записани, прочистени или приложени. Той ви предоставя детайлен преглед на състоянието на репликация.
Запитвания за използване в възела на готовност
В възела в режим на готовност има поддържани функции, за които можете да смекчите това в заявка и да ви предоставите преглед на състоянието на вашата репликация в режим на готовност. За да направите това, можете да изпълните следната заявка по-долу (заявката е базирана на PG версия> 10),
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00В по-старите версии можете да използвате следната заявка:
postgres=# select pg_is_in_recovery(),pg_last_xlog_receive_location(), pg_last_xlog_replay_location(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_last_xlog_receive_location | 1/9FD6490
pg_last_xlog_replay_location | 1/9FD6490
pg_last_xact_replay_timestamp | 2020-02-21 08:32:40.485958-06Какво казва заявката? Функциите са дефинирани съответно тук,
- pg_is_in_recovery ():(логично) Вярно, ако възстановяването все още е в ход.
- pg_last_wal_receive_lsn ()/pg_last_xlog_receive_location(): (pg_lsn) Местоположението на дневника за предварителна запис, получено и синхронизирано с диска чрез поточно репликация.
- pg_last_wal_replay_lsn ()/pg_last_xlog_replay_location(): (pg_lsn) Последното местоположение на регистрационния файл с предварителна запис, възпроизведено по време на възстановяването. Ако възстановяването все още е в ход, това ще се увеличи монотонно.
- pg_last_xact_replay_timestamp (): (клеймо за време с часова зона) Получаване на клеймо за дата на последната транзакция, възпроизведена по време на възстановяване.
Използвайки някои основни математики, можете да комбинирате тези функции. Най-често използваната функция, която се използва от DBA, е,
SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
или във версии PG <10,
SELECT CASE WHEN pg_last_xlog_receive_location() = pg_last_xlog_replay_location()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;Въпреки че тази заявка е била на практика и се използва от DBA. Все пак не ви предоставя точна представа за изоставането. Защо? Нека обсъдим това в следващия раздел.
Идентифициране на изоставане, причинено от отсъствието на сегмента WAL
Режимните възли на PostgreSQL, които са в режим на възстановяване, не ви съобщават точното състояние на случващото се с вашата репликация. Не, освен ако не прегледате дневника на PG, можете да събирате информация за това какво се случва. Няма заявка, която можете да изпълните, за да определите това. В повечето случаи организациите и дори малките институции предлагат софтуер на трети страни, който им позволява да бъдат предупредени при вдигане на аларма.
Един от тях е ClusterControl, който ви предлага наблюдаемост, изпраща сигнали при повдигане на аларми или възстановява вашия възел в случай на бедствие или катастрофа. Да вземем този сценарий, моят първичен резервен асинхронен стрийминг репликационен клъстер се провали. Как ще разберете дали нещо не е наред? Нека комбинираме следното:
Стъпка 1:Определете дали има забавяне
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
-[ RECORD 1 ]
log_delay | 0Стъпка 2:Определете сегментите на WAL, получени от първичния и сравнете с възел в режим на готовност
## Get the master's current LSN. Run the query below in the master
postgres=# SELECT pg_current_wal_lsn();
-[ RECORD 1 ]------+-----------
pg_current_wal_lsn | 0/925D7E70За по-стари версии на PG <10, използвайте pg_current_xlog_location.
## Get the current WAL segments received (flushed or applied/replayed)
postgres=# select pg_is_in_recovery(),pg_is_wal_replay_paused(), pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), pg_last_xact_replay_timestamp();
-[ RECORD 1 ]-----------------+------------------------------
pg_is_in_recovery | t
pg_is_wal_replay_paused | f
pg_last_wal_receive_lsn | 0/2705BDA0
pg_last_wal_replay_lsn | 0/2705BDA0
pg_last_xact_replay_timestamp | 2020-02-21 02:18:54.603677+00Изглежда зле.
Стъпка 3:Определете колко лошо може да бъде
Сега нека смесим формулата от стъпка #1 и стъпка #2 и да получим разликата. Как да направите това, PostgreSQL има функция, наречена pg_wal_lsn_diff, която се дефинира като,
pg_wal_lsn_diff(lsn pg_lsn, lsn pg_lsn) / pg_xlog_location_diff (местоположение pg_lsn, местоположение pg_lsn): (числово) Изчислете разликата между две местоположения на регистрационния файл с предварителна запис
Сега нека да го използваме, за да определим изоставането. Можете да го стартирате във всеки PG възел, тъй като ние просто ще предоставим статичните стойности:
postgres=# select pg_wal_lsn_diff('0/925D7E70','0/2705BDA0'); -[ RECORD 1 ]---+-----------
pg_wal_lsn_diff | 1800913104Нека да изчислим колко е 1800913104, което изглежда е около 1,6GiB може да е отсъствало в възела на готовност,
postgres=# select round(1800913104/pow(1024,3.0),2) missing_lsn_GiB;
-[ RECORD 1 ]---+-----
missing_lsn_gib | 1.68Накрая, можете да продължите или дори преди заявката да разгледате регистрационните файлове, като да използвате tail -5f, за да следвате и да проверите какво се случва. Направете това и за двата основни/готови възела. В този пример ще видим, че има проблем,
## Primary
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_033512.log
2020-02-21 16:44:33.574 UTC [25023] ERROR: requested WAL segment 000000030000000000000027 has already been removed
...
## Standby
example@sqldat.com:/var/lib/postgresql/11/main# tail -5f log/postgresql-2020-02-21_014137.log
2020-02-21 16:45:23.599 UTC [26976] LOG: started streaming WAL from primary at 0/27000000 on timeline 3
2020-02-21 16:45:23.599 UTC [26976] FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000030000000000000027 has already been removed
...Когато се сблъскате с този проблем, по-добре е да възстановите своите възли в режим на готовност. В ClusterControl това е лесно с едно щракване. Просто отидете в секцията Възли/Топология и възстановете възела точно както по-долу:
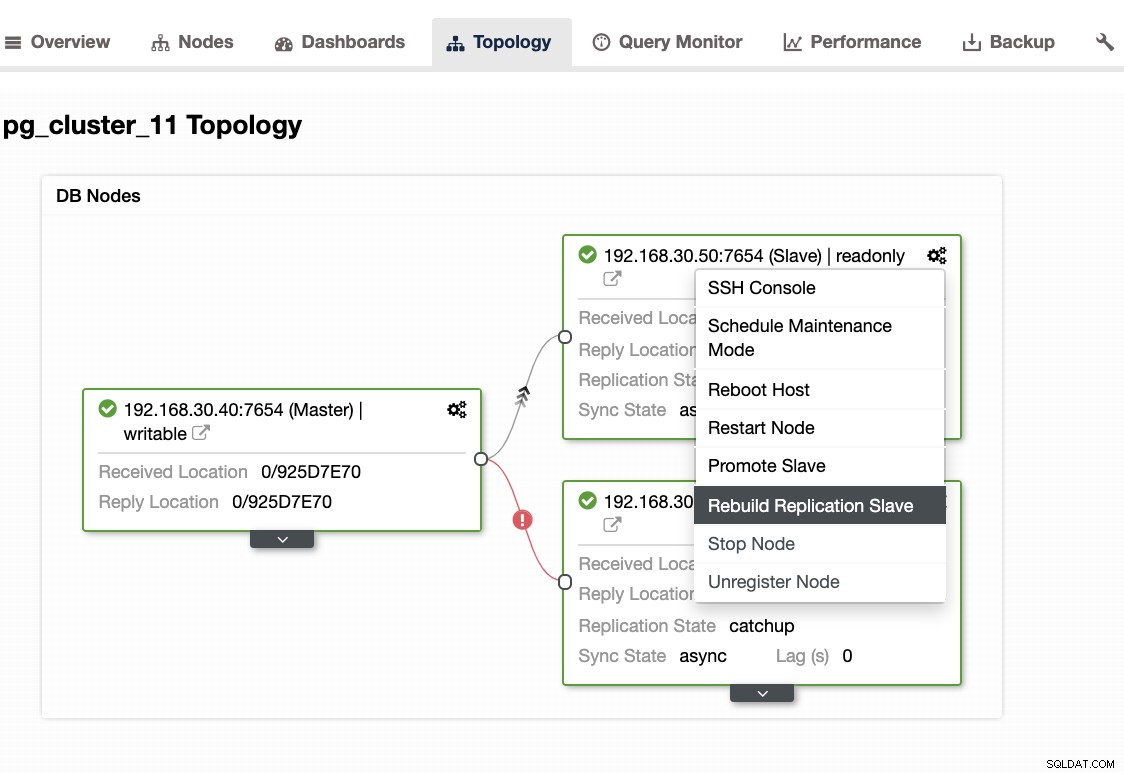
Други неща за проверка
Можете да използвате същия подход в предишния ни блог (в MySQL), като използвате системни инструменти като комбинация от ps, top, iostat, netstat. Например, можете също да получите текущия възстановен WAL сегмент от възел в режим на готовност,
example@sqldat.com:/var/lib/postgresql/11/main# ps axufwww|egrep "postgre[s].*startup"
postgres 8065 0.0 8.3 715820 170872 ? Ss 01:41 0:03 \_ postgres: 11/main: startup recovering 000000030000000000000027Как може да помогне ClusterControl?
ClusterControl предлага ефективен начин за наблюдение на възлите на вашата база данни от първични към подчинени възли. Когато отидете в раздела Преглед, вече имате изглед за здравето на вашата репликация:
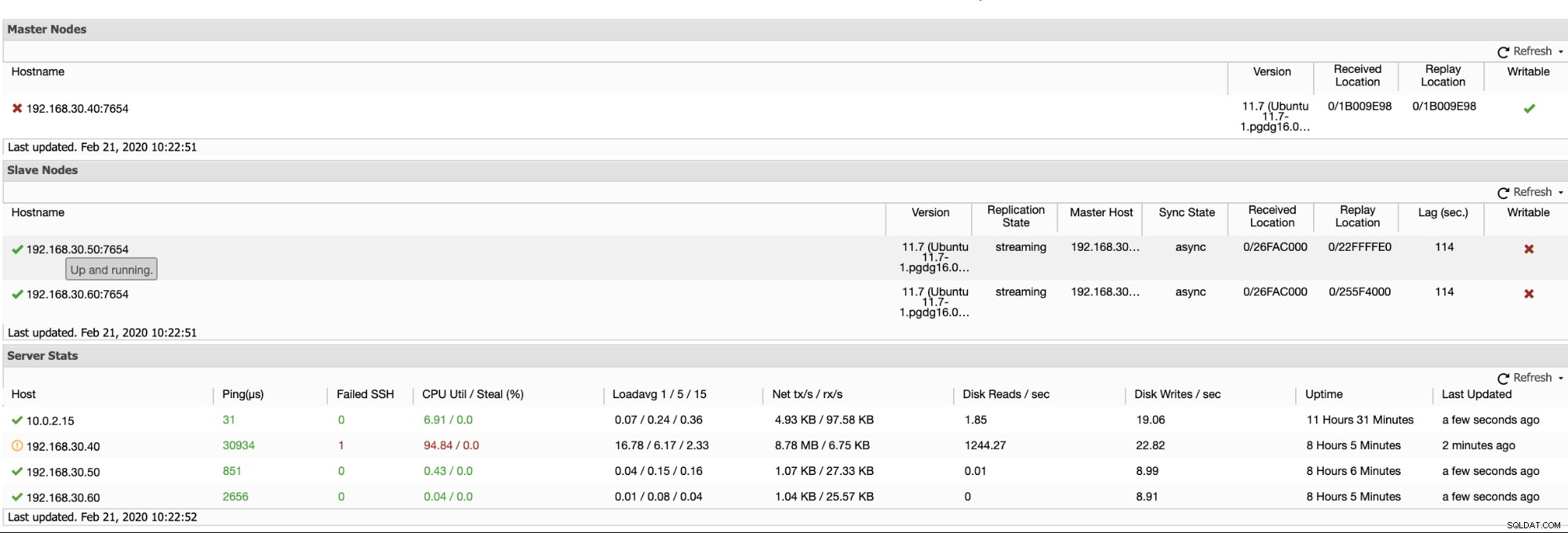
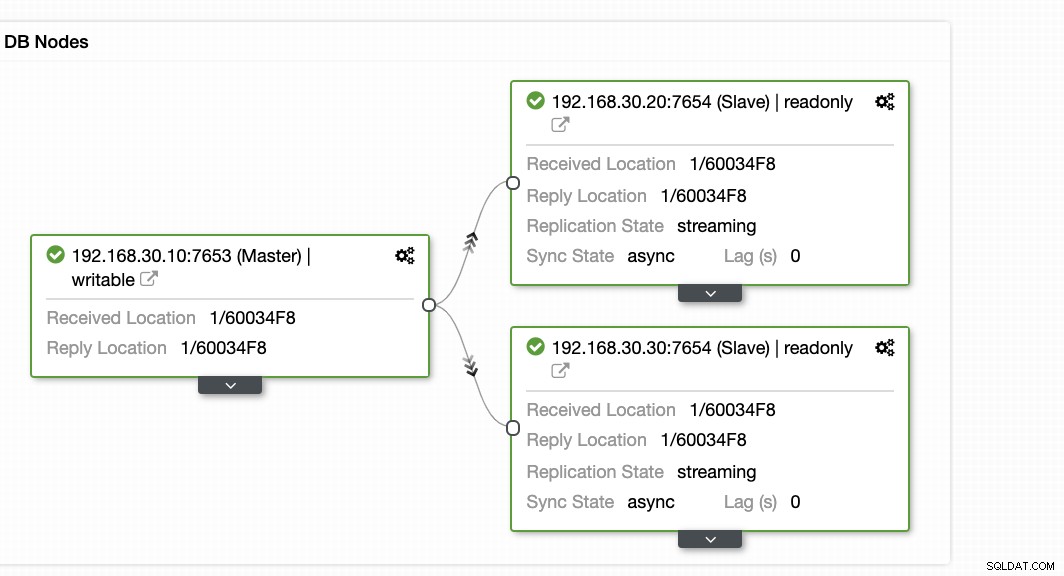
По принцип двете екранни снимки по-горе показват как е състоянието на репликацията и какво е текущото WAL сегменти. Това изобщо не е така. ClusterControl също така показва текущата активност на това, което се случва с вашия клъстер.
Заключение
Наблюдението на здравето на репликацията в PostgreSQL може да завърши с различен подход, стига да сте в състояние да посрещнете нуждите си. Използването на инструменти на трети страни с възможност за наблюдение, които могат да ви уведомят в случай на катастрофа, е идеалният ви маршрут, независимо дали е с отворен код или предприятие. Най-важното е, че имате план за възстановяване след бедствие и непрекъснатост на бизнеса, планирани преди подобни проблеми.