Брент Озар, сертифициран майстор на Microsoft, наскоро обсъди паралелизма в SQL Server, по-конкретно типовете чакане CXPACKET и CXCONSUMER в последната си част от есенната серия от Quest’s Database Training Days. По обичайния си хумористичен и достъпен начин Брент демистифицира концепциите за паралелизъм и обясни как да се справя с него, когато виждате твърде много CXPACKET и CXCONSUMER статистически данни за чакане.
Първо, какво е паралелизъм и защо SQL Server кара заявките да се изпълняват паралелно?
Казано по-просто, SQL Server автоматично разпознава, че конкретна заявка има голямо натоварване и определя, че работата може да се извърши по-ефективно в множество процесори, отколкото само от един. Това обикновено е интелигентно решение, но може да срещне проблеми, когато SQL Server не балансира натоварването на нишките, изпълняващи задачата.
Разбиране на CXPACKET и CXCONSUMER типовете чакане
CXPACKET и CXCONSUMER са типове изчакване, които показват, че работата не е еднакво балансирана. Когато видите тези статистически данни за изчакване на вашия сървър, ще знаете, че SQL Server изпълнява заявки паралелно, но не върши чудесна работа по разпространението им между наличните процесори.
Всеки специалист по база данни е запознат с концепцията за „цена“, за да изрази колко скъпо е изпълнението на заявката по отношение на потреблението на ресурси. Тези „долари за заявка“ са приблизителна мярка за работа и важен сигнал за това дали заявката ще се изпълнява паралелно или не. Евтината заявка няма да трябва да се изпълнява паралелно, но скъпата ще бъде. Целта е заявката да се изпълни възможно най-бързо и ефективно, за да може да започне следващата по ред. SQL Server обозначава нишка като планировчик и тази нишка, която Брент смята за „робот властелин“, ще присвоява части от паралелното работно натоварване на работните нишки или „роботите миньони“.

Паралелизъм и роботът господ
Брент се гмурна в демонстрация, за да покаже как работи това. Използвайки базата данни на Stack Overflow, той създаде евтино търсене на база данни, което беше много бързо поради наличието на индекс. Планът за изпълнение беше доста ясен и не изискваше паралелизъм за изпълнение.
Но когато той въведе търсене за нещо, което не беше в индекса, нещата се промениха, като наложи ключово търсене за всеки ред в клъстерирания индекс на таблицата. SQL Server разбра, че това ще бъде много работа, така че въведе паралелизъм и беше обозначен като такъв с икона в плана за изпълнение. Ако планът за изпълнение беше триизмерен, бихте могли да видите множеството нишки подредени, но тъй като не е, трябва да прегледате статистическите данни, за да видите информация като логическите четения, извършени от всяка нишка на процесора.
SQL Server обаче възложи тази задача само на няколко нишки, а не на всички. Брент обясни, че всичко, което се случва извън паралелната икона, се случва само на определените процесори. Така че нишките, извършили първоначалните четения, сега са единствените, които също извършват ключовите търсения. Повелителят на роботите помоли само няколко миньона да изпълнят цялата задача, вместо да помоли всички миньони да се включат.
Той продължи да обясни, че SQL Server трябва да отчита какво правят нишките, както и да проследява какво прави господарят на робота. В първите дни цялата тази работа беше представена от една статистика за чакане, но това нямаше смисъл, защото независимо от всичко, господарят все още трябва да чака, докато всички нишки работят. И така, беше въведен нов тип изчакване – това беше CXCONSUMER и той проследява какво прави нишката на планировщика/повелителя, докато CXPACKET проследява какво правят нишките работник/миньон.
Брент се върна към заявката, за да я направи още по-сложна, като добави сортиране. Сега става още по-ясно, че паралелизмът създава проблем, а не прави операцията по-ефективна. Работата е станала още по-небалансирана в няколко работни нишки, а на някои им липсва памет и се прехвърлят на диска. Той добави присъединяване, като още повече натовари работещите ядра, които не получават никаква помощ от неработещите. Статистиката на CXPACKET продължи да се покачва.
Какво можете да направите в тази ситуация? Решението за паралелизъм се случва на ниво сървър, а не на ниво заявка, така че ще са необходими някои промени в конфигурацията.
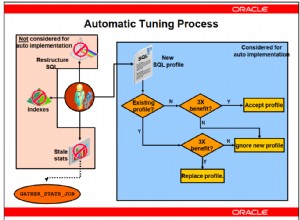
Оценяване на ключови конфигурации
Вече научихме, че ако цената на заявката е по-висока от определено ниво, това кара SQL Server да се паралелизира. Малките заявки се ограничават до една нишка. Но какво контролира прага? Това е свойство, наречено Cost Threshold for Parallelism (CTFP). По подразбиране, ако планът за изпълнение определи цената да е по-висока от 5 долара за заявка, заявката ще се паралелизира. Въпреки че няма насоки как да зададете това, Брент препоръчва число, по-голямо от 50. Това ще премахне паралелизма за тривиални заявки.
Друга конфигурация е максимальната степен на паралелизъм (MAXDOP), която описва броя нишки, които SQL Server ще присвои на заявката. Стойността по подразбиране тук е нула, което означава, че SQL Server може да използва всички налични процесори, до 64, за да изпълни заявката. Задаването на опцията MAXDOP на 1 ограничава SQL Server до използване само на един процесор – на практика принуждавайки сериен план да изпълни заявката. SQL Server ще препоръча стойност MAXDOP въз основа на броя на сървърните ядра, които имате, но като цяло по-нисък MAXDOP има смисъл, тъй като няма да има много пъти, когато всички ядра са необходими.
Брент направи корекции в тези две конфигурации и изпълни отново заявката си. Този път можехме да видим, че повече ядра бяха ангажирани в паралелната операция. Статистиката за изчакване на CXPACKET беше по-ниска, което означаваше, че натоварването беше по-равномерно балансирано в повече ядра от преди.
Съвети за борба със статистическите данни за изчакване CXPACKET и CXCONSUMER
Brent препоръчва следните стъпки, ако виждате прекомерна статистика за чакане на CXPACKET и CXCONSUMER:
- Задайте CTFP и MAXDOP според най-добрите практики в отрасъла и след това оставете тези настройки да се изпекат за няколко дни. Това изчиства кеша на плана и принуждава SQL Server да изгради отново плановете за изпълнение на заявка (преоценете разходите).
- Направете подобрения в индекса, което ще намали времето, когато заявките вървят паралелно за извършване на сканиране и сортиране. Оставете новите индекси да се изпичат и след това потърсете заявки, които все още вършат много работа.
- Настройте тези заявки и ги оставете да се пекат за няколко дни.
- Накрая, ако паралелизмът все още е сериозен проблем, започнете да търсите конкретните заявки с проблеми с паралелизма.
За още по-голяма представа можете да видите цялата сесия на обучение на Брент на CXPACKET и CXCONSUMER статистически данни за чакане при поискване по-долу.