Докато SQL Server на Linux открадна почти всички заглавия за v.Next, има някои други интересни подобрения, които идват в следващата версия на нашата любима платформа за бази данни. От фронта на T-SQL най-накрая имаме вграден начин за извършване на групирана конкатенация на низове:STRING_AGG() .
Да кажем, че имаме следната проста структура на таблицата:
СЪЗДАВАНЕ НА ТАБЛИЦА dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL РЕФЕРЕНЦИИ НА ВЪНШЕН КЛЮЧ dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns ПРАВИЛЕН КЛЮЧ ([object_id],column_name));
За тестове за производителност ще попълним това с помощта на sys.all_objects и sys.all_columns . Но за проста демонстрация първо, нека добавим следните редове:
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'CustomerID');
Ако форумите са някаква индикация, много често се изисква да се върне ред за всеки обект, заедно със списък с имена на колони, разделени със запетая. (Екстраполирайте това към каквито и типове обекти, които моделирате по този начин – имена на продукти, свързани с поръчка, имена на части, участващи в сглобяването на продукт, подчинени, отчитащи се на мениджър и т.н.) Така че, например, с горните данни бихме искам изход като този:
обект колони--------- -------------------------------------Employees EmployeeID,CurrentStatusOrders OrderID,OrderDate, ИД на клиента
Начинът, по който бихме постигнали това в текущите версии на SQL Server вероятно е да използваме FOR XML PATH , както показах, че е най-ефективният извън CLR в тази по-ранна публикация. В този пример ще изглежда така:
SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c [object_id] =o.[object_id] ЗА XML) ЗА XML. ПЪТ, ТИП ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')ОТ dbo.Objects КАТО o;
Очаквано, получаваме същия изход, демонстриран по-горе. В SQL Server v.Next ще можем да изразим това по-просто:
SELECT [object] =o.[ime_object], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[] object_id]GROUP BY o.[ime_object];
Отново, това произвежда абсолютно същия изход. И успяхме да направим това с естествена функция, избягвайки както скъпите FOR XML PATH скеле и STUFF() функция, използвана за премахване на първата запетая (това се случва автоматично).
Какво ще кажете за поръчката?
Един от проблемите с много от kludge решенията за групирана конкатенация е, че подреждането на списъка, разделен със запетая, трябва да се счита за произволен и недетерминистичен.
За XML PATH решение, демонстрирах в друга по-ранна публикация, че добавянето на ORDER BY е тривиален и гарантиран. Така че в този пример бихме могли да подредим списъка с колони по име на колона по азбучен ред, вместо да го оставим на SQL Server за сортиране (или не):
SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c. column_name -- промяна само ЗА XML ПЪТ, ТИП ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')ОТ dbo.Objects КАТО o;
Изход:
обект колони--------- -------------------------------------Служители CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, ИД на поръчка
CTP 1.1 добавя WITHIN GROUP към STRING_AGG() , така че използвайки новия подход, можем да кажем:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') В ГРУПАТА (ПОРЕД ОТ c.column_name) -- само changeFROM dbo.Objects AS oINNER JOIN dbo. Колони AS cON o.[object_id] =c.[object_id]GROUP BY o.[object_name];
Сега получаваме същите резултати. Имайте предвид, че точно като обикновен ORDER BY клауза, можете да добавите множество колони за подреждане или изрази вътре в WITHIN GROUP () .
Добре, изпълнение вече!
Използвайки четириядрени 2,6 GHz процесори, 8 GB памет и SQL Server CTP1.1 (14.0.100.187), създадох нова база данни, създадох отново тези таблици и добавих редове от sys.all_objects и sys.all_columns . Уверих се, че включвам само обекти, които имат поне една колона:
INSERT dbo.Objects([object_id], [object_name]) -- 656 реда SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FROM sys.all_objects КАТО o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS ( ИЗБЕРЕТЕ 1 ОТ sys.all_columns WHERE [object_id] =o.[object_id] ]); INSERT dbo.Columns([object_id], column_name) -- 8,085 реда SELECT [object_id], name FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id]);В моята система това даде 656 обекта и 8085 колони (вашата система може да даде малко по-различни числа).
Плановете
Първо, нека сравним плановете и разделите за вход/изход на таблица за нашите две неподредени заявки, използвайки Plan Explorer. Ето общите показатели по време на изпълнение:
Показатели за време на изпълнение за XML PATH (отгоре) и STRING_AGG() (отдолу)
Графичният план и таблицата I/O от
FOR XML PATHзаявка:
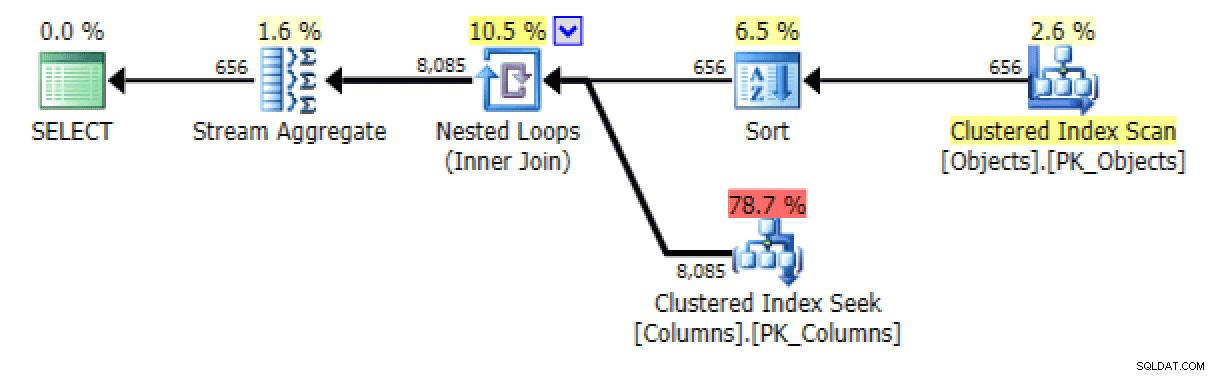
План и таблица I/O за XML PATH, без поръчка
И от
STRING_AGGверсия:
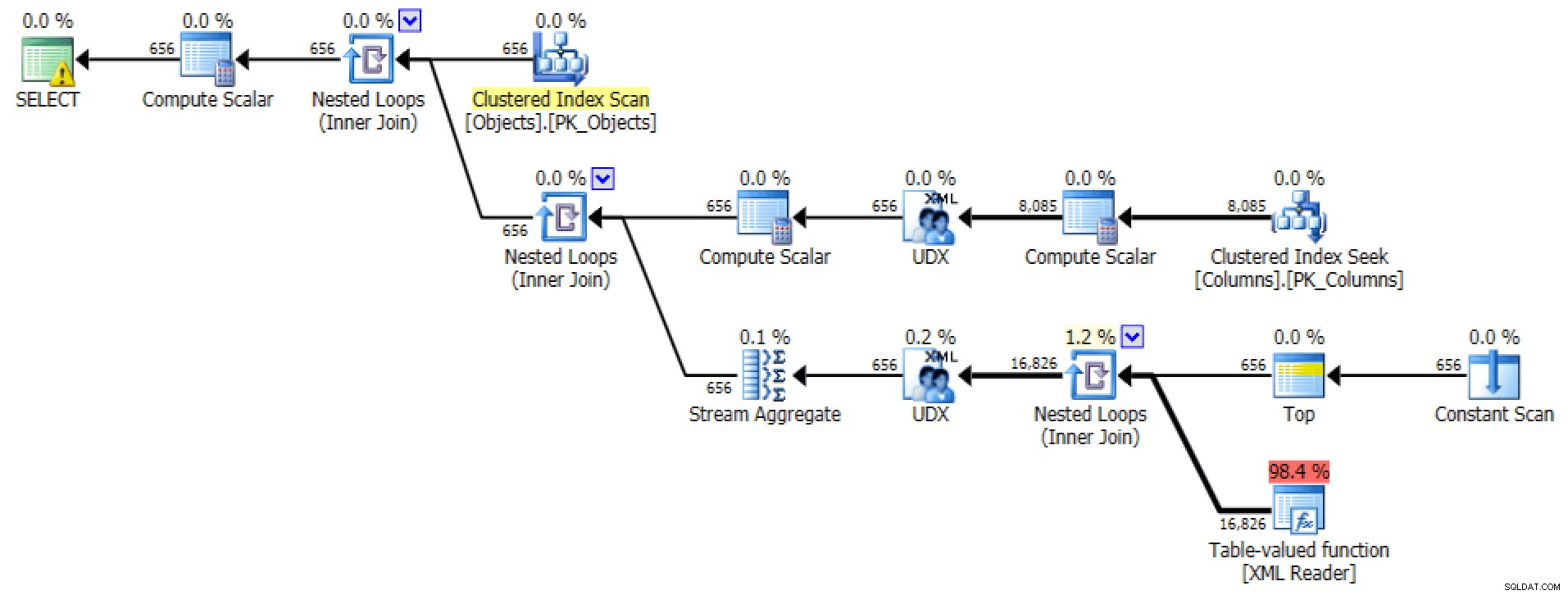
План и таблица I/O за STRING_AGG, без поръчка
За последното търсенето на клъстериран индекс ми изглежда малко обезпокоително. Това изглеждаше като добър случай за тестване на рядко използвания
FORCESCANнамек (и не, това със сигурност няма да помогне заFOR XML PATHзапитване):SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS OINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- добавен подсказкаON o .[object_id] =c.[object_id]GROUP BY o.[object_name];Сега разделът за план и таблица I/O изглеждат много по-добре, поне на пръв поглед:
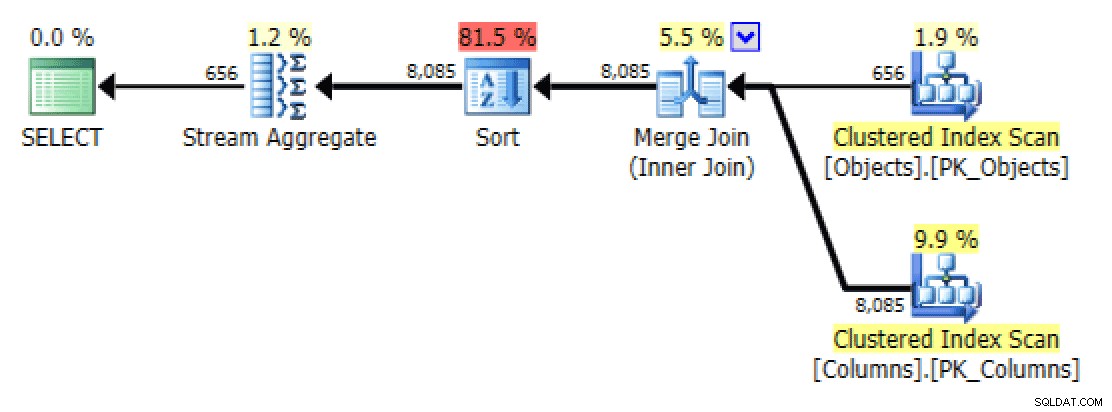
План и таблица I/O за STRING_AGG(), без подреждане, с FORCESCAN
Подредените версии на заявките генерират приблизително същите планове. За
FOR XML PATHверсия, се добавя сортиране:
Добавено сортиране във версия FOR XML PATH
За
STRING_AGG(), в този случай се избира сканиране, дори безFORCESCANнамек и не се изисква допълнителна операция за сортиране – така че планът изглежда идентичен сFORCESCANверсия.В мащаб
Разглеждането на план и еднократни показатели по време на изпълнение може да ни даде някаква представа за това дали
STRING_AGG()работи по-добре от съществуващияFOR XML PATHрешение, но по-голям тест може да има повече смисъл. Какво се случва, когато извършим групираната конкатенация 5000 пъти?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_idid] ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unorreded] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[ime_object];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME(). ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c КЪДЕ c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value. (N'.[1]',N'nvarchar(max)'),1,1,N'')ОТ dbo.Objects КАТО o;GO 5000SELECT [за xml път, неподреден] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') В рамките на ГРУПА (ПОРЕД ОТ c.column_name) ОТ dbo.Objects КАТО o INNER JOIN dbo.Columns КАТО c ON o.[object_id_id] ] =c.[идентификатор_обект] ГРУПА ПО o.[име_на_обект];GO 5000SELECT [string_agg, подредено] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c КЪДЕ c.[object_id] =o.[object_id] ПОРЪЧАЙТЕ ПО c.column_name ЗА XML ПЪТЯ). , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')ОТ dbo.Objects КАТО OORDER BY o.[ime_object];GO 5000SELECT [за xml пътека]; , подредено] =SYSDATETIME();След като изпълних този скрипт пет пъти, усредних числата за продължителност и ето резултатите:
Продължителност (милисекунди) за различни групирани подходи за конкатенация
Можем да видим, че нашият
FORCESCANнамек наистина влоши нещата – докато изместихме цената от търсенето на клъстерен индекс, сортирането всъщност беше много по-лошо, въпреки че изчислените разходи ги смятаха за относително еквивалентни. По-важното е, че можем да видим, чеSTRING_AGG()предлага предимство на производителността, независимо дали конкатенираните низове трябва да бъдат подредени по специфичен начин. Както приSTRING_SPLIT(), който разгледах още през март, съм доста впечатлен, че тази функция се мащабира доста преди "v1."Планирани са ми допълнителни тестове, може би за бъдеща публикация:
- Когато всички данни идват от една таблица, със и без индекс, който поддържа подреждане
- Подобни тестове за производителност на Linux
Междувременно, ако имате конкретни случаи на употреба за групирана конкатенация, моля, споделете ги по-долу (или ми изпратете имейл на abertrand@sentryone.com). Винаги съм отворен да се уверя, че тестовете ми са възможно най-реални.