Миналата седмица направих няколко бързи сравнения на производителността, като поставих новия STRING_AGG() функция срещу традиционния FOR XML PATH подход, който използвам от векове. Тествах както недефиниран/произволен ред, така и изричен ред и STRING_AGG() излезе начело и в двата случая:
- SQL сървър v.Next :STRING_AGG() Производителност, част 1
За тези тестове пропуснах няколко неща (не всички умишлено):
- Mikael Eriksson и Grzegorz Łyp посочиха, че не използвам абсолютно най-ефективния
FOR XML PATHконструирам (и за да е ясно, никога не съм го правил). - Не извърших никакви тестове на Linux; само на Windows. Не очаквам те да бъдат значително различни, но тъй като Гжегож видя много различни продължителности, това си струва допълнително разследване.
- Тествах също само когато изходът ще бъде краен, не-LOB низ – което смятам, че е най-често срещаният случай на употреба (не мисля, че хората обикновено ще обединяват всеки ред в таблица в единична, разделена със запетая низ, но ето защо попитах в предишната си публикация за вашия случай(и) на употреба).
- За тестовете за подреждане не създадох индекс, който може да е полезен (или опитах нещо, където всички данни идват от една таблица).
В тази публикация ще се занимавам с няколко от тези елементи, но не всички.
ЗА XML ПЪТ
Използвах следното:
... FOR XML PATH, TYPE).value(N'.[1]', ...
След този коментар от Микаел актуализирах кода си, за да използвам тази малко по-различна конструкция:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux срещу Windows
Първоначално си бях направила труда да стартирам тестове на Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Но Гжегож каза справедливо, че той (и вероятно много други) има достъп само до Linux аромата на CTP 1.1. Така че добавих Linux към моята тестова матрица:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Някои интересни, но напълно тангенциални наблюдения:
@@VERSIONне показва издание в тази компилация, ноSERVERPROPERTY('Edition')връща очакванотоDeveloper Edition (64-bit).- Въз основа на времето за изграждане, кодирано в двоичните файлове, версиите за Windows и Linux изглежда вече се компилират по едно и също време и от един и същ източник. Или това беше едно лудо съвпадение.
Неподредени тестове
Започнах с тестване на произволно подредения изход (където няма изрично дефиниран ред за конкатенираните стойности). След Гжегож използвах WideWorldImporters (Стандарт), но извърших обединяване между Sales.Orders и Sales.OrderLines . Измисленото изискване тук е да изведете списък с всички поръчки и заедно с всяка поръчка, разделен със запетая списък на всеки StockItemID .
Тъй като StockItemID е цяло число, можем да използваме дефиниран varchar , което означава, че низът може да бъде 8000 знака, преди да трябва да се тревожим дали ще ни трябва MAX. Тъй като int може да бъде с максимална дължина от 11 (наистина 10, ако не е подписан), плюс запетая, това означава, че поръчката ще трябва да поддържа около 8 000/12 (666) артикули на склад в най-лошия случай (например всички стойности на StockItemID имат 11 цифри). В нашия случай най-дългият идентификационен номер е 3 цифри, така че докато не бъдат добавени данните, всъщност ще ни трябват 8 000/4 (2 000) уникални артикула в произволен ред, за да оправдаем MAX. В нашия случай има само 227 артикула на склад, така че MAX не е необходим, но трябва да го следите. Ако такъв голям низ е възможен във вашия сценарий, ще трябва да използвате varchar(max) вместо по подразбиране (STRING_AGG() връща nvarchar(max) , но съкращава до 8000 байта, освен ако вход е тип MAX).
Първоначалните заявки (за показване на примерен изход и за наблюдение на продължителността за единични изпълнения):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Пренебрегнах напълно данните за синтактичния анализ и компилирането, тъй като те винаги бяха точно нула или достатъчно близки, за да бъдат ирелевантни. Имаше незначителни различия във времето за изпълнение за всяко изпълнение, но не много – коментарите по-горе отразяват типичната делта по време на изпълнение (STRING_AGG изглежда се възползва малко от паралелизма там, но само в Linux, докато FOR XML PATH не и на нито една платформа). И двете машини имаха единичен сокет, четириядрен процесор, 8 GB памет, конфигурация извън кутията и никакви други дейности.
Тогава исках да тествам в мащаб (просто една сесия, изпълняваща една и съща заявка 500 пъти). Не исках да връщам целия изход, както в горната заявка, 500 пъти, тъй като това би претоварило SSMS – и да се надяваме, че така или иначе не представлява реални сценарии на заявка. Така че присвоих изхода на променливи и просто измерих общото време за всяка партида:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Проведох тези тестове три пъти и разликата беше дълбока - почти порядък. Ето средната продължителност на трите теста:
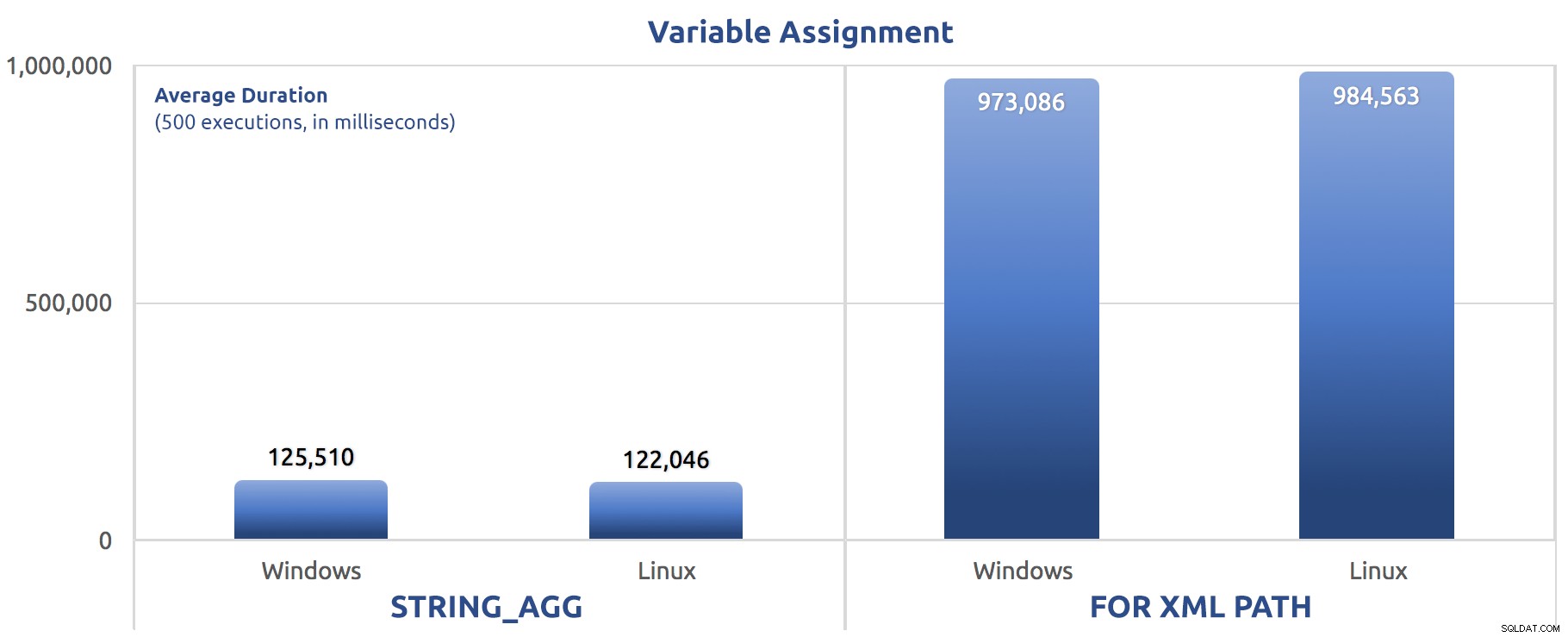 Средна продължителност, в милисекунди, за 500 изпълнения на присвояване на променлива
Средна продължителност, в милисекунди, за 500 изпълнения на присвояване на променлива
Тествах и различни други неща по този начин, най-вече за да се уверя, че покривам видовете тестове, които Гжегож изпълнява (без частта LOB).
- Избиране само на дължината на изхода
- Получаване на максималната дължина на изхода (на произволен ред)
- Избиране на целия изход в нова таблица
Избиране само на дължината на изхода
Този код просто преминава през всяка поръчка, конкатенира всички стойности на StockItemID и след това връща само дължината.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ За пакетната версия отново използвах присвояване на променливи, вместо да се опитвам да върна много набори от резултати към SSMS. Присвояването на променлива ще се окаже на произволен ред, но това все пак изисква пълно сканиране, тъй като произволният ред не е избран първи.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Показатели за ефективност на 500 изпълнения:
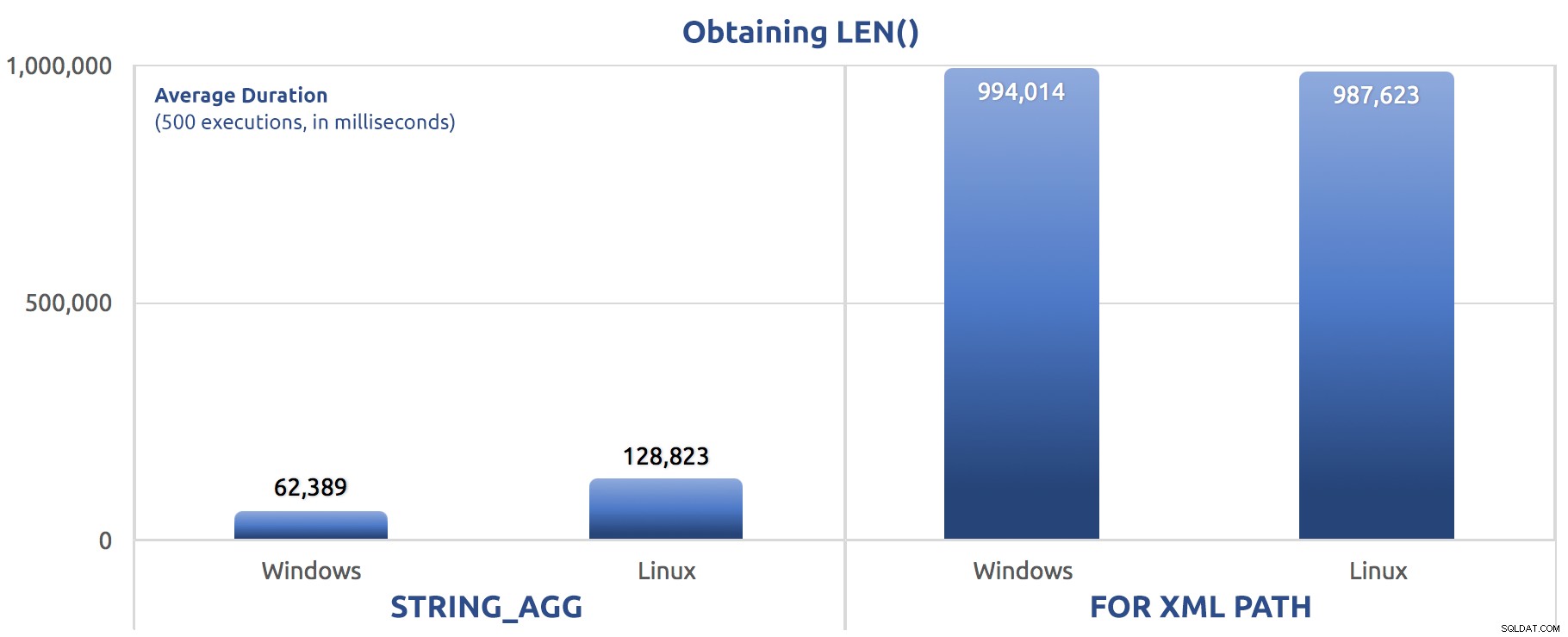 500 изпълнения на присвояване на LEN() на променлива
500 изпълнения на присвояване на LEN() на променлива
Отново виждаме FOR XML PATH е много по-бавно, както в Windows, така и в Linux.
Избиране на максималната дължина на изхода
Лека вариация на предишния тест, този просто извлича максимум дължина на конкатенирания изход:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ И в мащаб, ние просто присвояваме този изход отново на променлива:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Резултати от производителността за 500 изпълнения, осреднени за три цикъла:
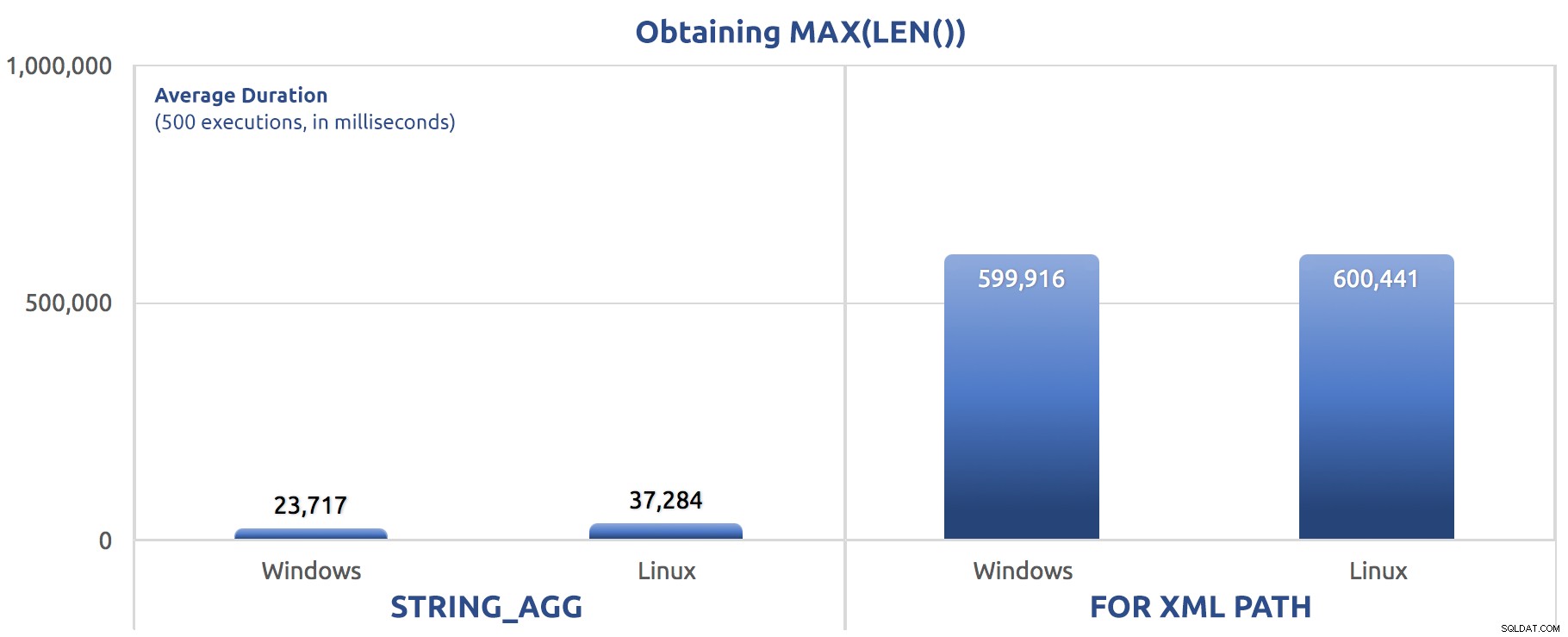 500 изпълнения на присвояване на MAX(LEN()) на променлива
500 изпълнения на присвояване на MAX(LEN()) на променлива
Може да започнете да забелязвате модел в тези тестове – FOR XML PATH винаги е куче, дори и с подобренията в производителността, предложени в предишната ми публикация.
ИЗБЕРЕТЕ В
Исках да видя дали методът на конкатенация има някакво влияние върху записването данните обратно на диска, както е в някои други сценарии:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
В този случай виждаме, че може би SELECT INTO успяхме да се възползваме от малко паралелизъм, но все пак виждаме FOR XML PATH борба, с времена на изпълнение с порядък по-дълги от STRING_AGG .
Пакетната версия току-що смени командите SET STATISTICS за SELECT sysdatetime(); и добави същия GO 500 след двете основни партиди, както при предишните тестове. Ето как се получи това (отново ми кажете дали сте чували това преди):
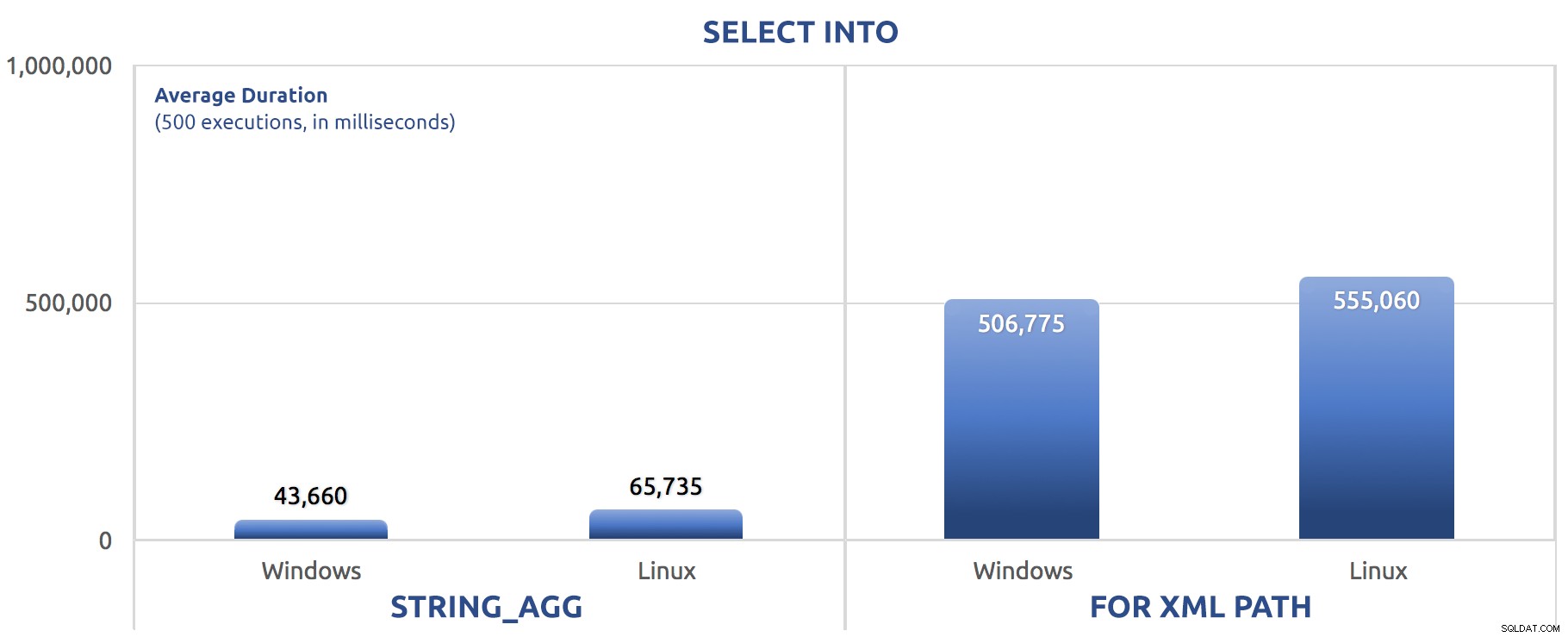 500 изпълнения на SELECT INTO
500 изпълнения на SELECT INTO
Поръчани тестове
Проведох същите тестове, използвайки подредения синтаксис, напр.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Това имаше много малко влияние върху каквото и да било – същият набор от четири тестови устройства показа почти идентични показатели и модели в целия борд.
Ще ми бъде любопитно да видя дали това е различно, когато конкатенираният изход е в не-LOB или когато конкатенацията трябва да подреди низове (със или без поддържащ индекс).
Заключение
За низове, които не са LOB , ясно ми е, че STRING_AGG има определено предимство в производителността пред FOR XML PATH , както на Windows, така и на Linux. Имайте предвид, че за да избегнете изискването за varchar(max) или nvarchar(max) , не използвах нищо подобно на тестовете, които Grzegorz проведе, което би означавало просто конкатениране на всички стойности от колона, в цяла таблица, в един низ. В следващата си публикация ще разгледам случая на използване, при който изходът на конкатенирания низ би могъл да бъде по-голям от 8000 байта и така ще трябва да се използват LOB типове и преобразувания.