SQL Server 2014 CTP1 излиза от няколко седмици и вероятно сте виждали доста преса за оптимизирани за памет таблици и обновяеми индекси на columnstore. Въпреки че те със сигурност заслужават внимание, в тази публикация исках да проуча новото подобрение на паралелизма SELECT ... INTO. Подобрението е една от онези промени в готовото облекло, които, както изглежда, няма да изискват значителни промени в кода, за да започнете да се възползвате от него. Моите проучвания бяха извършени с помощта на версия на Microsoft SQL Server 2014 (CTP1) – 11.0.9120.5 (X64), Enterprise Evaluation Edition.
Паралелен SELECT … INTO
SQL Server 2014 въвежда паралелно активиран SELECT ... INTO за бази данни и за тестване на тази функция използвах базата данни AdventureWorksDW2012 и версия на таблицата FactInternetSales, която имаше 61 847 552 реда в нея (аз бях отговорен за добавянето на тези редове; те не идват с базата данни по подразбиране).
Тъй като тази функция, от CTP1, изисква ниво на съвместимост на базата данни 110, за целите на тестването настроих базата данни на ниво 100 и изпълних следната заявка за първия си тест:
SELECT [ProductKey],
[OrderDateKey],
[DueDateKey],
[ShipDateKey],
[CustomerKey],
[PromotionKey],
[CurrencyKey],
[SalesTerritoryKey],
[SalesOrderNumber],
[SalesOrderLineNumber],
[RevisionNumber],
[OrderQuantity],
[UnitPrice],
[ExtendedAmount],
[UnitPriceDiscountPct],
[DiscountAmount],
[ProductStandardCost],
[TotalProductCost],
[SalesAmount],
[TaxAmt],
[Freight],
[CarrierTrackingNumber],
[CustomerPONumber],
[OrderDate],
[DueDate],
[ShipDate]
INTO dbo.FactInternetSales_V2
FROM dbo.FactInternetSales; Продължителността на изпълнението на заявката беше 3 минути и 19 секунди на моя тестов VM и действителният план за изпълнение на заявката беше, както следва:

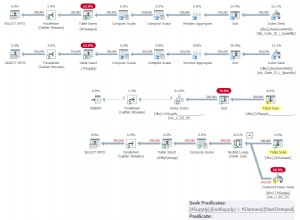
SQL Server използва сериен план, както очаквах. Забележете също, че в моята таблица имаше неклъстериран индекс на columnstore, който беше сканиран (създадох този неклъстериран индекс на columnstore за използване с други тестове, но ще ви покажа и плана за изпълнение на заявка за клъстериран columnstore по-късно). Планът не използва паралелизъм и Columnstore Index Scan използва режим на изпълнение на ред вместо режим на пакетно изпълнение.
След това промених нивото на съвместимост на базата данни (и имайте предвид, че все още няма ниво на съвместимост със SQL Server 2014 в CTP1):
USE [master]; GO ALTER DATABASE [AdventureWorksDW2012] SET COMPATIBILITY_LEVEL = 110; GO
Изпуснах таблицата FactInternetSales_V2 и след това изпълних отново моя оригинален SELECT ... INTO операция. Този път продължителността на изпълнение на заявката беше 1 минута и 7 секунди, а действителният план за изпълнение на заявката беше както следва:
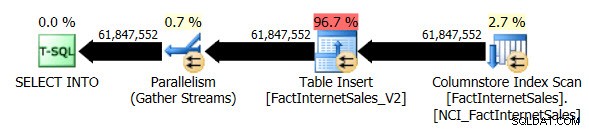
Вече имаме паралелен план и единствената промяна, която трябваше да направя, беше нивото на съвместимост на базата данни за AdventureWorksDW2012. Моят тестов VM има четири vCPU, разпределени към него, а планът за изпълнение на заявката разпределя редове в четири нишки:

Неклъстерираното индексно сканиране на Columnstore, докато използва паралелизъм, не използва режим на пакетно изпълнение. Вместо това той използва режим на изпълнение на редове.
Ето таблица за показване на резултатите от теста до момента:
| Тип сканиране | Ниво на съвместимост | Паралелен SELECT … INTO | Режим на изпълнение | Продължителност |
|---|---|---|---|---|
| Неклъстерирано индексно сканиране на Columnstore | 100 | Не | Ред | 3:19 |
| Неклъстерирано индексно сканиране на Columnstore | 110 | Да | Ред | 1:07 |
Така че като следващ тест пуснах неклъстерирания индекс на columnstore и изпълних отново SELECT ... INTO заявка, използвайки и двете нива на съвместимост на базата данни 100 и 110.
Тестът за ниво 100 на съвместимост отне 5 минути и 44 секунди за изпълнение и беше генериран следният план:
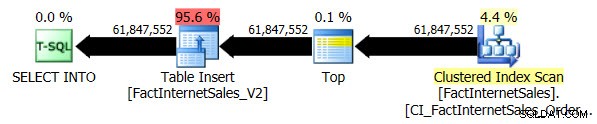
Серийното клъстерирано индексно сканиране отне 2 минути и 25 секунди повече от серийното неклъстерно индексно сканиране на Columnstore.
Използвайки ниво на съвместимост 110, заявката отне 1 минута и 55 секунди за изпълнение и беше генериран следният план:

Подобно на паралелния неклъстериран тест за индексно сканиране на Columnstore, паралелното Clustered Index Scan разпределя редове в четири нишки:
Следната таблица обобщава тези два гореспоменати теста:
| Тип сканиране | Ниво на съвместимост | Паралелен SELECT … INTO | Режим на изпълнение | Продължителност |
|---|---|---|---|---|
| Клъстерно сканиране на индекси | 100 | Не | Ред (N/A) | 5:44 |
| Клъстерно сканиране на индекси | 110 | Да | Ред (N/A) | 1:55 |
Така че тогава се чудех за производителността за клъстериран индекс на columnstore (ново в SQL Server 2014), така че махнах съществуващите индекси и създадох клъстериран индекс на columnstore в таблицата FactInternetSales. Освен това трябваше да премахна осемте различни ограничения на външния ключ, дефинирани в таблицата, преди да мога да създам клъстерирания индекс на columnstore.
Дискусията става донякъде академична, тъй като сравнявам SELECT ... INTO производителност при нива на съвместимост на базата данни, които не предлагат клъстерни индекси за columnstore на първо място – нито по-ранните тестове за неклъстерни индекси за columnstore на ниво 100 на съвместимост на базата данни – и все пак е интересно да се видят и сравнят общите характеристики на производителността.
CREATE CLUSTERED COLUMNSTORE INDEX [CCSI_FactInternetSales] ON [dbo].[FactInternetSales] WITH (DROP_EXISTING = OFF); GO
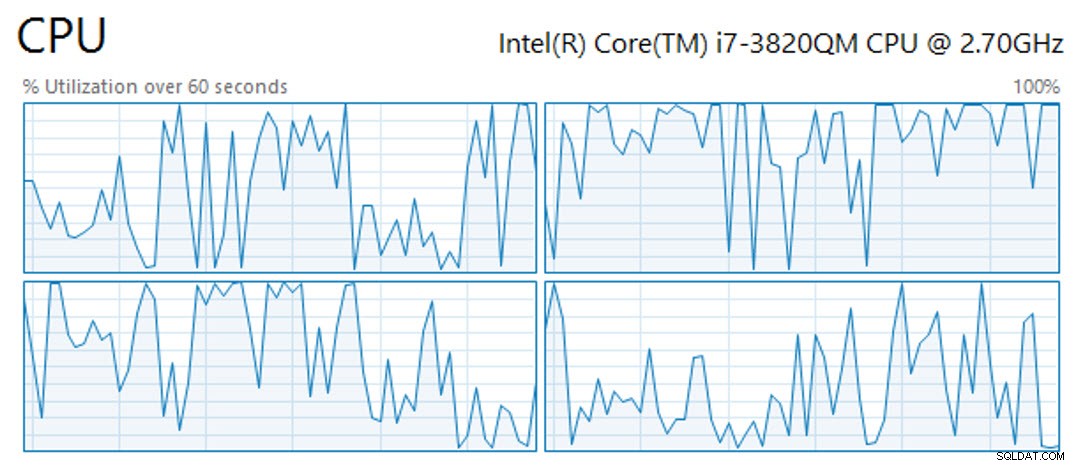
Като настрана, операцията за създаване на клъстериран индекс на columnstore в таблица с редове от 61 847 552 милиона отне 11 минути и 25 секунди с четири налични vCPU (от които операцията ги използва всички), 4 GB RAM и виртуално гостно хранилище на OCZ Vertex SSD. През това време процесорите не бяха фиксирани през цялото време, а по-скоро показваха върхове и долини (извадка от 60 секунди от активността на процесора, показана по-долу):
След като беше създаден клъстерираният индекс на columnstore, изпълних отново двата SELECT ... INTO тестове. Тестът за ниво 100 на съвместимост отне 3 минути и 22 секунди за изпълнение и планът беше сериен, както се очакваше (показвам версията на SQL Server Management Studio на плана след клъстерното сканиране на индекса на Columnstore, от SQL Server 2014 CTP1 , все още не е напълно разпознат от Plan Explorer):

След това промених нивото на съвместимост на базата данни на 110 и стартирах отново теста, който този път заявката отне 1 минута и 11 секунди и имаше следния действителен план за изпълнение:

Планът разпределя редове в четири нишки и точно като неклъстерирания индекс на columnstore, режимът на изпълнение на клъстерното сканиране на индекс Columnstore беше ред, а не пакет.
Следната таблица обобщава всички тестове в тази публикация (по реда на продължителност, от ниска към висока):
| Тип сканиране | Ниво на съвместимост | Паралелен SELECT … INTO | Режим на изпълнение | Продължителност |
|---|---|---|---|---|
| Неклъстерирано индексно сканиране на Columnstore | 110 | Да | Ред | 1:07 |
| Клъстерно сканиране на индекс на Columnstore | 110 | Да | Ред | 1:11 |
| Клъстерно сканиране на индекси | 110 | Да | Ред (N/A) | 1:55 |
| Неклъстерирано индексно сканиране на Columnstore | 100 | Не | Ред | 3:19 |
| Клъстерно сканиране на индекс на Columnstore | 100 | Не | Ред | 3:22 |
| Клъстерно сканиране на индекси | 100 | Не | Ред (N/A) | 5:44 |
Няколко наблюдения:
- Не съм сигурен дали разликата между паралелен
SELECT ... INTOоперацията срещу неклъстериран индекс на columnstore срещу клъстериран индекс на columnstore е статистически значима. Ще трябва да направя още тестове, но мисля, че ще изчакам да ги направя до RTM. - Смело мога да кажа, че паралелният
SELECT ... INTOзначително превъзхождаше серийните еквиваленти в тестовете за клъстериран индекс, неклъстеризирано columnstore и клъстеризирано columnstore индексни тестове.
Струва си да се спомене, че тези резултати са за CTP версия на продукта и моите тестове трябва да се разглеждат като нещо, което може да промени поведението си от RTM - така че бях по-малко заинтересован от самостоятелните продължителности в сравнение с това как тези продължителности се сравняват между серийни и паралелни условия.
Някои характеристики на производителност изискват значително префакториране – но за SELECT ... INTO подобрение, всичко, което трябваше да направя, беше да повиша нивото на съвместимост на базата данни, за да започна да виждам предимствата, което определено е нещо, което оценявам.