Виждам много съвети, които казват нещо от рода на „Променете курсора си на операция, базирана на набор; това ще го направи по-бързо.“ Въпреки че това често може да се случи, това не винаги е вярно. Един случай на употреба, който виждам, когато курсорът многократно превъзхожда типичния подход, базиран на набори, е изчисляването на текущите суми. Това е така, защото подходът, базиран на набори, обикновено трябва да разглежда някаква част от основните данни повече от един път, което може да бъде експоненциално лошо нещо, тъй като данните стават все повече; докато курсорът – колкото и болезнено да звучи – може да премине през всеки ред/стойност точно веднъж.
Това са нашите основни опции в най-често срещаните версии на SQL Server. В SQL Server 2012 обаче имаше няколко подобрения на функциите за прозорци и клаузата OVER, най-вече произтичащи от няколко страхотни предложения, представени от колегата MVP Ицик Бен-Ган (ето едно от неговите предложения). Всъщност Itzik има нова книга за MS-Press, която обхваща всички тези подобрения в много по-големи подробности, озаглавена „Високопроизводителен T-SQL на Microsoft SQL Server 2012 с използване на функции на прозореца“.
Така че, естествено, бях любопитен; новата функционалност на прозореца би ли направила техниките на курсора и самостоятелното присъединяване остарели? Ще бъдат ли по-лесни за кодиране? Ще бъдат ли по-бързи във всички (няма значение всички) случаи? Какви други подходи може да са валидни?
Настройката
За да направим някои тестове, нека настроим база данни:
USE [master];
GO
IF DB_ID('RunningTotals') IS NOT NULL
BEGIN
ALTER DATABASE RunningTotals SET SINGLE_USER WITH ROLLBACK IMMEDIATE;
DROP DATABASE RunningTotals;
END
GO
CREATE DATABASE RunningTotals;
GO
USE RunningTotals;
GO
SET NOCOUNT ON;
GO И след това попълнете таблица с 10 000 реда, които можем да използваме, за да направим някои текущи суми. Нищо твърде сложно, само обобщена таблица с ред за всяка дата и число, представящо колко глоби за превишена скорост са издадени. Не съм имал глоба за превишена скорост от няколко години, така че не знам защо това беше моят подсъзнателен избор за опростен модел на данни, но ето го.
CREATE TABLE dbo.SpeedingTickets ( [Date] DATE NOT NULL, TicketCount INT ); GO ALTER TABLE dbo.SpeedingTickets ADD CONSTRAINT pk PRIMARY KEY CLUSTERED ([Date]); GO ;WITH x(d,h) AS ( SELECT TOP (250) ROW_NUMBER() OVER (ORDER BY [object_id]), CONVERT(INT, RIGHT([object_id], 2)) FROM sys.all_objects ORDER BY [object_id] ) INSERT dbo.SpeedingTickets([Date], TicketCount) SELECT TOP (10000) d = DATEADD(DAY, x2.d + ((x.d-1)*250), '19831231'), x2.h FROM x CROSS JOIN x AS x2 ORDER BY d; GO SELECT [Date], TicketCount FROM dbo.SpeedingTickets ORDER BY [Date]; GO
Съкратени резултати:
И така отново, 10 000 реда доста прости данни – малки INT стойности и поредица от дати от 1984 до май 2011 г.
Подходите
Сега задачата ми е сравнително проста и типична за много приложения:връщане на набор от резултати, който има всичките 10 000 дати, заедно с кумулативната сума на всички глоби за превишена скорост до и включително тази дата. Повечето хора първо биха опитали нещо подобно (ще наречем това „вътрешно присъединяване " метод):
SELECT st1.[Date], st1.TicketCount, RunningTotal = SUM(st2.TicketCount) FROM dbo.SpeedingTickets AS st1 INNER JOIN dbo.SpeedingTickets AS st2 ON st2.[Date] <= st1.[Date] GROUP BY st1.[Date], st1.TicketCount ORDER BY st1.[Date];
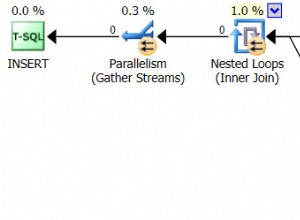
…и бъдете шокирани да откриете, че тичането отнема почти 10 секунди. Нека бързо да разгледаме защо, като прегледаме графичния план за изпълнение, използвайки SQL Sentry Plan Explorer:

Големите дебели стрелки трябва да дават незабавна индикация за това, което се случва:вложеният цикъл чете един ред за първото агрегиране, два реда за второто, три реда за третото и нататък и нататък през целия набор от 10 000 реда. Това означава, че трябва да видим приблизително ((10000 * (10000 + 1)) / 2) редове, обработени, след като целият набор бъде обходен, и това изглежда съвпада с броя на редовете, показани в плана.
Обърнете внимание, че изпълнението на заявката без паралелизъм (използвайки намек за заявка OPTION (MAXDOP 1)) прави формата на плана малко по-опростена, но изобщо не помага нито за времето за изпълнение, нито за I/O; както е показано в плана, продължителността всъщност се удвоява, а четенията намаляват само с много малък процент. В сравнение с предишния план:
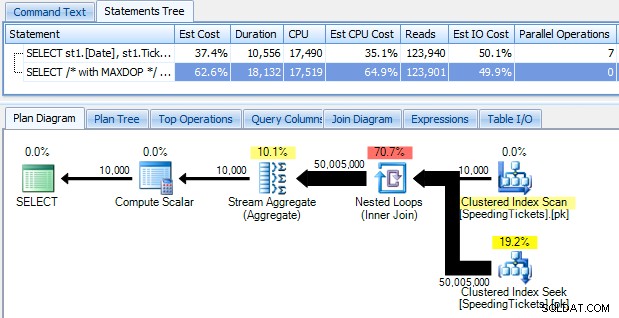
Има много други подходи, които хората са се опитвали да получат ефективни текущи суми. Един пример е „метод на подзаявка ", който просто използва корелирана подзаявка почти по същия начин като метода за вътрешно присъединяване, описан по-горе:
SELECT [Date], TicketCount, RunningTotal = TicketCount + COALESCE( ( SELECT SUM(TicketCount) FROM dbo.SpeedingTickets AS s WHERE s.[Date] < o.[Date]), 0 ) FROM dbo.SpeedingTickets AS o ORDER BY [Date];
Сравняване на тези два плана:
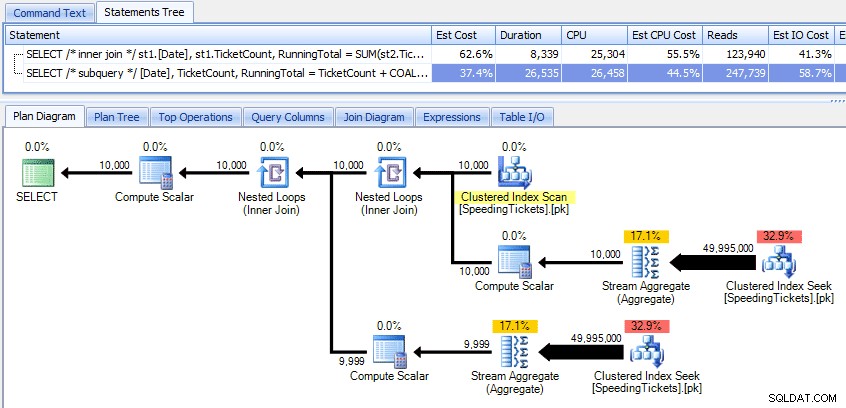
Така че, докато методът на подзаявката изглежда има по-ефективен цялостен план, е по-лошо там, където има значение:продължителност и I/O. Можем да видим какво допринася за това, като се поразровим в плановете малко по-дълбоко. Като преминем към раздела Най-добри операции, можем да видим, че при метода за вътрешно свързване търсенето на клъстериран индекс се изпълнява 10 000 пъти, а всички други операции се изпълняват само няколко пъти. Въпреки това, няколко операции се изпълняват 9 999 или 10 000 пъти в метода на подзаявката:
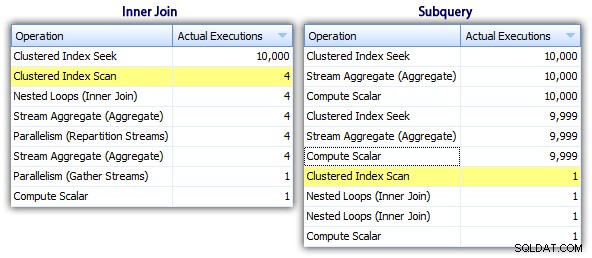
Така че подходът на подзаявката изглежда е по-лош, а не по-добър. Следващият метод, който ще опитаме, ще нарека „странна актуализация " метод. Това не е точно гарантирано, че работи и никога не бих го препоръчал за производствен код, но го включвам за пълнота. По принцип странната актуализация се възползва от факта, че по време на актуализация можете да пренасочвате заданието и математиката, така че че променливата се увеличава зад кулисите, когато всеки ред се актуализира.
DECLARE @st TABLE ( [Date] DATE PRIMARY KEY, TicketCount INT, RunningTotal INT ); DECLARE @RunningTotal INT = 0; INSERT @st([Date], TicketCount, RunningTotal) SELECT [Date], TicketCount, RunningTotal = 0 FROM dbo.SpeedingTickets ORDER BY [Date]; UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st; SELECT [Date], TicketCount, RunningTotal FROM @st ORDER BY [Date];
Ще повторя, че не вярвам, че този подход е безопасен за производство, независимо от показанията, които ще чуете от хора, които сочат, че „никога не се проваля“. Освен ако поведението не е документирано и гарантирано, се опитвам да стоя далеч от предположения, базирани на наблюдавано поведение. Никога не знаете кога някаква промяна в пътя на решението на оптимизатора (въз основа на промяна на статистиката, промяна на данните, сервизен пакет, флаг за проследяване, намек за заявка, какво имате) драстично ще промени плана и потенциално ще доведе до различен ред. Ако наистина харесвате този неинтуитивен подход, можете да се почувствате малко по-добре, като използвате опцията за заявка FORCE ORDER (и това ще се опита да използва подредено сканиране на PK, тъй като това е единственият допустим индекс в променливата на таблицата):
UPDATE @st SET @RunningTotal = RunningTotal = @RunningTotal + TicketCount FROM @st OPTION (FORCE ORDER);
За малко повече увереност при малко по-висока I/O цена, можете да върнете оригиналната маса обратно в игра и да се уверите, че се използва PK на основната маса:
UPDATE st SET @RunningTotal = st.RunningTotal = @RunningTotal + t.TicketCount FROM dbo.SpeedingTickets AS t WITH (INDEX = pk) INNER JOIN @st AS st ON t.[Date] = st.[Date] OPTION (FORCE ORDER);
Лично аз не мисля, че е толкова по-гарантирано, тъй като частта SET от операцията може потенциално да повлияе на оптимизатора независимо от останалата част от заявката. Отново не препоръчвам този подход, просто включвам сравнението за пълнота. Ето плана от тази заявка:
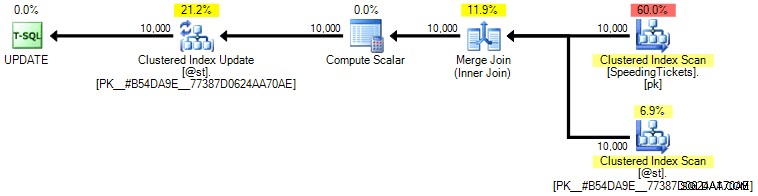
Въз основа на броя на изпълненията, които виждаме в раздела Най-добри операции (ще ви спестя екранната снимка; тя е 1 за всяка операция), е ясно, че дори и да извършим присъединяване, за да се почувстваме по-добре при поръчването, странното актуализацията позволява текущите суми да бъдат изчислени с едно преминаване на данните. Сравнявайки го с предишните заявки, той е много по-ефективен, въпреки че първо изхвърля данни в таблична променлива и се разделя на множество операции:

Това ни води до "рекурсивен CTE " метод. Този метод използва стойността на датата и разчита на предположението, че няма пропуски. Тъй като попълнихме тези данни по-горе, знаем, че това е напълно непрекъсната серия, но в много сценарии не можете да направите това предположение. Така че, въпреки че го включих за пълнота, този подход не винаги ще бъде валиден. Във всеки случай, това използва рекурсивна CTE с първата (известна) дата в таблицата като котва и рекурсивната част, определена чрез добавяне на един ден (добавяне на опцията MAXRECURSION, тъй като знаем точно колко реда имаме):
;WITH x AS ( SELECT [Date], TicketCount, RunningTotal = TicketCount FROM dbo.SpeedingTickets WHERE [Date] = '19840101' UNION ALL SELECT y.[Date], y.TicketCount, x.RunningTotal + y.TicketCount FROM x INNER JOIN dbo.SpeedingTickets AS y ON y.[Date] = DATEADD(DAY, 1, x.[Date]) ) SELECT [Date], TicketCount, RunningTotal FROM x ORDER BY [Date] OPTION (MAXRECURSION 10000);
Тази заявка работи приблизително толкова ефективно, колкото и странният метод за актуализиране. Можем да го сравним с методите на подзаявката и вътрешното присъединяване:

Подобно на странния метод за актуализиране, не бих препоръчал този CTE подход в производството, освен ако не можете абсолютно да гарантирате, че вашата ключова колона няма пропуски. Ако може да имате пропуски в данните си, можете да създадете нещо подобно с помощта на ROW_NUMBER(), но няма да е по-ефективно от метода за самостоятелно присъединяване по-горе.
И тогава имаме "курсор " подход:
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
DECLARE
@Date DATE,
@TicketCount INT,
@RunningTotal INT = 0;
DECLARE c CURSOR
LOCAL STATIC FORWARD_ONLY READ_ONLY
FOR
SELECT [Date], TicketCount
FROM dbo.SpeedingTickets
ORDER BY [Date];
OPEN c;
FETCH NEXT FROM c INTO @Date, @TicketCount;
WHILE @@FETCH_STATUS = 0
BEGIN
SET @RunningTotal = @RunningTotal + @TicketCount;
INSERT @st([Date], TicketCount, RunningTotal)
SELECT @Date, @TicketCount, @RunningTotal;
FETCH NEXT FROM c INTO @Date, @TicketCount;
END
CLOSE c;
DEALLOCATE c;
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date]; …което е много повече код, но противно на това, което популярното мнение може да предложи, се връща за 1 секунда. Можем да разберем защо от някои от детайлите на плана по-горе:повечето от другите подходи в крайна сметка четат едни и същи данни отново и отново, докато курсорният подход чете всеки ред веднъж и запазва текущата сума в променлива, вместо да изчислява сумата за и отново. Можем да видим това, като разгледаме изявленията, заснети чрез генериране на действителен план в Plan Explorer:
Можем да видим, че са събрани над 20 000 изявления, но ако сортираме по Прогнозни или Действителни редове надолу, откриваме, че има само две операции, които обработват повече от един ред. Което е далеч от някои от горните методи, които причиняват експоненциални четения поради четене на едни и същи предишни редове отново и отново за всеки нов ред.
Сега, нека да разгледаме новите подобрения на прозорците в SQL Server 2012. По-специално, вече можем да изчислим SUM OVER() и да посочим набор от редове спрямо текущия ред. Така например:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] RANGE UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date]; SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date] ROWS UNBOUNDED PRECEDING) FROM dbo.SpeedingTickets ORDER BY [Date];
Тези две заявки дават един и същ отговор, с правилни текущи суми. Но дали те работят абсолютно еднакво? Плановете предполагат, че не го правят. Версията с ROWS има допълнителен оператор, проект за последователност от 10 000 реда:
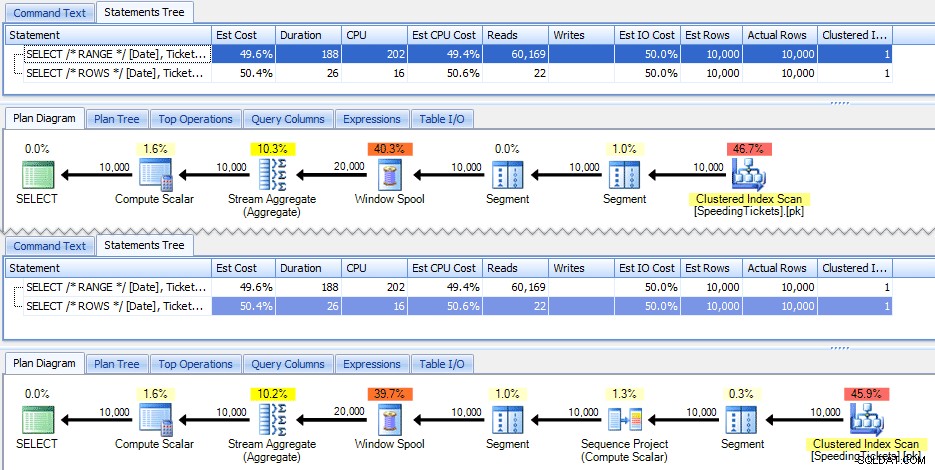
И това е около степента на разликата в графичния план. Но ако погледнете малко по-отблизо действителните показатели по време на изпълнение, ще видите малки разлики в продължителността и процесора и огромна разлика в четенията. Защо е това? Е, това е така, защото RANGE използва макара на диска, докато ROWS използва макара в паметта. При малки комплекти разликата вероятно е незначителна, но цената на макарата на диска със сигурност може да стане по-очевидна, когато комплектите стават по-големи. Не искам да развалям края, но може да подозирате, че едно от тези решения ще се представи по-добре от другото при по-задълбочен тест.
Като настрана, следната версия на заявката дава същите резултати, но работи като по-бавната версия RANGE по-горе:
SELECT [Date], TicketCount, SUM(TicketCount) OVER (ORDER BY [Date]) FROM dbo.SpeedingTickets ORDER BY [Date];
Така че, докато играете с новите функции на прозореца, ще искате да имате предвид малки дреболии като това:съкратената версия на заявка или тази, която сте написали първи, не е непременно тази, която искате за да прокарате до производство.
Реалните тестове
За да проведа честни тестове, създадох съхранена процедура за всеки подход и измерих резултатите, като заснех изявления на сървър, където вече наблюдавах с SQL Sentry (ако не използвате нашия инструмент, можете да събирате SQL:BatchCompleted събития по подобен начин с помощта на SQL Server Profiler).
Под „справедливи тестове“ имам предвид, че например странният метод за актуализиране изисква действителна актуализация на статичните данни, което означава промяна на основната схема или използване на променлива на временна таблица/таблица. Така че структурирах съхранените процедури, така че всяка да създаде своя собствена променлива в таблицата и или да съхранява резултатите там, или да съхранява необработените данни там и след това да актуализира резултата. Другият проблем, който исках да премахна, беше връщането на данните на клиента - така че всяка от процедурите има параметър за отстраняване на грешки, указващ дали да не връща никакви резултати (по подразбиране), горен/долен 5 или всички. В тестовете за производителност го настроих да не връща резултати, но разбира се потвърдих всеки, за да гарантирам, че връща правилните резултати.
Всички съхранени процедури са моделирани по този начин (прикачих скрипт, който създава базата данни и съхранените процедури, така че просто включвам шаблон тук за краткост):
CREATE PROCEDURE [dbo].[RunningTotals_]
@debug TINYINT = 0
-- @debug = 1 : show top/bottom 3
-- @debug = 2 : show all 50k
AS
BEGIN
SET NOCOUNT ON;
DECLARE @st TABLE
(
[Date] DATE PRIMARY KEY,
TicketCount INT,
RunningTotal INT
);
INSERT @st([Date], TicketCount, RunningTotal)
-- one of seven approaches used to populate @t
IF @debug = 1 -- show top 3 and last 3 to verify results
BEGIN
;WITH d AS
(
SELECT [Date], TicketCount, RunningTotal,
rn = ROW_NUMBER() OVER (ORDER BY [Date])
FROM @st
)
SELECT [Date], TicketCount, RunningTotal
FROM d
WHERE rn < 4 OR rn > 9997
ORDER BY [Date];
END
IF @debug = 2 -- show all
BEGIN
SELECT [Date], TicketCount, RunningTotal
FROM @st
ORDER BY [Date];
END
END
GO И ги извиках в група, както следва:
EXEC dbo.RunningTotals_DateCTE @debug = 0; GO EXEC dbo.RunningTotals_Cursor @debug = 0; GO EXEC dbo.RunningTotals_Subquery @debug = 0; GO EXEC dbo.RunningTotals_InnerJoin @debug = 0; GO EXEC dbo.RunningTotals_QuirkyUpdate @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Range @debug = 0; GO EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; GO
Бързо разбрах, че някои от тези обаждания не се появяват в Top SQL, защото прагът по подразбиране е 5 секунди. Промених това на 100 милисекунди (нещо, което никога не искате да правите в производствена система!), както следва:
Ще повторя:това поведение не се оправдава за производствените системи!
Все още открих, че една от командите по-горе не е била уловена от най-горния SQL праг; това беше версията Windowed_Rows. Така че добавих следното само към тази партида:
EXEC dbo.RunningTotals_Windowed_Rows @debug = 0; WAITFOR DELAY '00:00:01'; GO
И сега получавах връщането на всичките 7 реда в Top SQL. Тук те са подредени по низходящо използване на процесора:
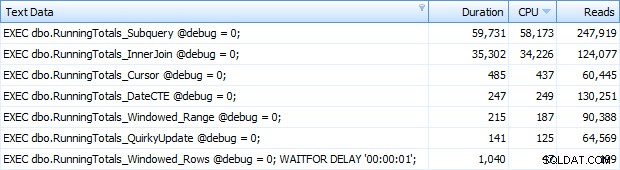
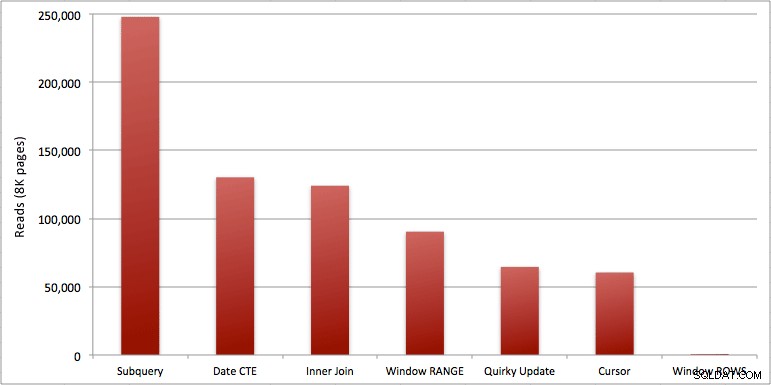
Можете да видите допълнителната секунда, която добавих към пакета Windowed_Rows; не беше хванат от най-горния SQL праг, защото завърши само за 40 милисекунди! Това очевидно е най-добрият ни производител и ако имаме наличен SQL Server 2012, това трябва да бъде методът, който използваме. Курсорът също не е наполовина лош, като се има предвид производителността или други проблеми с останалите решения. Начертаването на продължителността на графика е доста безсмислено – две високи точки и пет неразличими ниски точки. Но ако I/O е вашето тесно място, може да ви се стори интересна визуализацията на четенията:
Заключение
От тези резултати можем да направим няколко заключения:
- Прозоречни агрегати в SQL Server 2012 правят проблемите с производителността при текущите изчисления на общите суми (и много други проблеми със следващите редове/предходни редове) тревожно по-ефективни. Когато видях малкия брой четения, със сигурност си помислих, че има някаква грешка, че сигурно съм забравил да изпълня каквато и да е работа. Но не, получавате същия брой четения, ако вашата съхранена процедура просто изпълнява обикновен SELECT от таблицата SpeedingTickets. (Чувствайте се свободни да тествате това сами със STATISTICS IO.)
- Проблемите, които посочих по-рано относно RANGE спрямо ROWS, дават малко по-различно време на изпълнение (разлика в продължителността от около 6x – не забравяйте да игнорирате втората, която добавих с WAITFOR), но разликите в четенето са астрономически поради шпулата на диска. Ако вашият прозоречен агрегат може да бъде решен с помощта на ROWS, избягвайте RANGE, но трябва да тествате дали и двете дават един и същ резултат (или поне ROWS дава правилния отговор). Трябва също да отбележите, че ако използвате подобна заявка и не посочите RANGE или ROWS, планът ще работи така, както ако сте посочили RANGE).
- Методите на подзаявката и вътрешното присъединяване са сравнително ужасни. 35 секунди до минута, за да генерирате тези текущи суми? И това беше на една, кльощава маса, без да се връщат резултати на клиента. Тези сравнения могат да се използват, за да покажат на хората защо решението, базирано на набори, не винаги е най-добрият отговор.
- От по-бързите подходи, ако приемем, че все още не сте готови за SQL Server 2012, и ако приемем, че отхвърлите както странния метод за актуализиране (неподдържан), така и метода за дата на CTE (не може да гарантира непрекъсната последователност), само курсорът изпълнява приемливо. Има най-голяма продължителност от „по-бързите“ решения, но най-малко четения.
Надявам се, че тези тестове помогнат да се даде по-добра оценка за подобренията на прозореца, които Microsoft добави към SQL Server 2012. Моля, не забравяйте да благодарите на Itzik, ако го видите онлайн или лично, тъй като той беше движещата сила зад тези промени. Освен това се надявам, че това ще помогне на някои хора да разберат, че курсорът може да не винаги е злото и страшно решение, за което често се изобразява.
(Като допълнение, тествах функцията CLR, предлагана от Павел Павловски, и характеристиките на производителност бяха почти идентични с решението на SQL Server 2012, използвайки ROWS. Четенията бяха идентични, CPU беше 78 срещу 47 и общата продължителност беше 73 вместо 40. Така че, ако няма да преминете към SQL Server 2012 в близко бъдеще, може да искате да добавите решението на Павел към вашите тестове.)
Прикачени файлове:RunningTotals_Demo.sql.zip (2kb)