Принципът „Не се повтаряйте“ предполага, че трябва да намалите повторенията. Тази седмица попаднах на случай, при който DRY трябва да се изхвърли през прозореца. Има и други случаи (например скаларни функции), но този беше интересен, включващ побитова логика.
Нека си представим следната таблица:
CREATE TABLE dbo.CarOrders
(
OrderID INT PRIMARY KEY,
WheelFlag TINYINT,
OrderDate DATE
--, ... other columns ...
);
CREATE INDEX IX_WheelFlag ON dbo.CarOrders(WheelFlag); Битовете "WheelFlag" представляват следните опции:
0 = stock wheels 1 = 17" wheels 2 = 18" wheels 4 = upgraded tires
Така че възможните комбинации са:
0 = no upgrade 1 = upgrade to 17" wheels only 2 = upgrade to 18" wheels only 4 = upgrade tires only 5 = 1 + 4 = upgrade to 17" wheels and better tires 6 = 2 + 4 = upgrade to 18" wheels and better tires
Нека оставим настрана аргументите, поне засега, дали това трябва да бъде пакетирано в един TINYINT на първо място, или да се съхранява като отделни колони, или да използваме модел на EAV... коригирането на дизайна е отделен въпрос. Става дума за работа с това, което имате.
За да направим примерите полезни, нека попълним тази таблица с куп произволни данни. (И за простота ще приемем, че тази таблица съдържа само поръчки, които все още не са изпратени.) Това ще вмъкне 50 000 реда с приблизително еднакво разпределение между шестте комбинации от опции:
;WITH n AS
(
SELECT n,Flag FROM (VALUES(1,0),(2,1),(3,2),(4,4),(5,5),(6,6)) AS n(n,Flag)
)
INSERT dbo.CarOrders
(
OrderID,
WheelFlag,
OrderDate
)
SELECT x.rn, n.Flag, DATEADD(DAY, x.rn/100, '20100101')
FROM n
INNER JOIN
(
SELECT TOP (50000)
n = (ABS(s1.[object_id]) % 6) + 1,
rn = ROW_NUMBER() OVER (ORDER BY s2.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x
ON n.n = x.n; Ако погледнем разбивката, можем да видим това разпределение. Имайте предвид, че вашите резултати може да се различават малко от моите в зависимост от обектите във вашата система:
SELECT WheelFlag, [Count] = COUNT(*) FROM dbo.CarOrders GROUP BY WheelFlag;
Резултати:
WheelFlag Count --------- ----- 0 7654 1 8061 2 8757 4 8682 5 8305 6 8541
Сега да кажем, че е вторник и току-що получихме пратка от 18-инчови колела, които преди не бяха на склад. Това означава, че сме в състояние да удовлетворим всички поръчки, които изискват 18-инчови колела – и тези, които модернизираха гуми (6), и тези, които не са го направили (2). Така че ние *можем* да напишем заявка като следната:
SELECT OrderID
FROM dbo.CarOrders
WHERE WheelFlag IN (2,6); В реалния живот, разбира се, не можете да направите това; какво ще стане, ако по-късно се добавят още опции, като ключалки на колелата, доживотна гаранция на колелата или множество опции за гуми? Не искате да се налага да пишете серия от IN() стойности за всяка възможна комбинация. Вместо това можем да напишем операция BITWISE AND, за да намерим всички редове, където е зададен 2-ри бит, като например:
DECLARE @Flag TINYINT = 2;
SELECT OrderID
FROM dbo.CarOrders
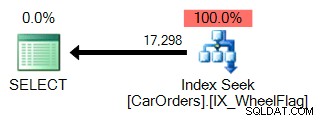
WHERE WheelFlag & @Flag = @Flag; Това ми дава същите резултати като IN() заявката, но ако ги сравня с помощта на SQL Sentry Plan Explorer, производителността е доста различна:

Лесно е да се разбере защо. Първият използва търсене на индекс, за да изолира редовете, които отговарят на заявката, с филтър в колоната WheelFlag:

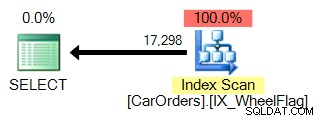
Вторият използва сканиране, съчетано с имплицитно преобразуване и ужасно неточна статистика. Всичко благодарение на оператора BITWISE AND:


И така, какво означава това? В основата на това, това ни казва, че операцията BITWISE AND не може да се sargable .
Но всяка надежда не е загубена.
Ако пренебрегнем принципа DRY за момент, можем да напишем малко по-ефективна заявка, като бъдем малко излишни, за да се възползваме от индекса в колоната WheelFlag. Ако приемем, че търсим която и да е опция WheelFlag над 0 (без надстройка изобщо), можем да пренапишем заявката по този начин, като кажем на SQL Server, че стойността на WheelFlag трябва да бъде поне същата стойност като флага (което елиминира 0 и 1 ), и след това добавяне на допълнителната информация, че тя също трябва да съдържа този флаг (по този начин се елиминира 5).
SELECT OrderID FROM dbo.CarOrders WHERE WheelFlag >= @Flag AND WheelFlag & @Flag = @Flag;
Частта>=на тази клауза очевидно е покрита от частта BITWISE, така че тук нарушаваме DRY. Но тъй като тази клауза, която добавихме, е sargable, пренасочването на операцията BITWISE AND към вторично условие за търсене все още дава същия резултат, а цялостната заявка дава по-добра производителност. Виждаме подобно търсене на индекс към твърдо кодираната версия на заявката по-горе и въпреки че оценките са още по-далеч (нещо, което може да бъде разгледано като отделен проблем), четенията все още са по-ниски, отколкото при само операцията BITWISE AND:

Можем също да видим, че срещу индекса се използва филтър, което не видяхме, когато използвахме само операцията BITWISE AND:

Заключение
Не се страхувайте да се повтаряте. Има моменти, когато тази информация може да помогне на оптимизатора; въпреки че може да не е напълно интуитивно за *добавяне* критерии, за да се подобри производителността, важно е да се разбере кога допълнителните клаузи помагат за намаляване на данните за крайния резултат, вместо да улесняват оптимизатора да намери точните редове самостоятелно.