Въведение в индексите на SQL Server
Microsoft SQL Server се счита за една от системите за управление на релационни бази данни (RDBMS ), в който данните са логически организирани в редове и колони, които се съхраняват в контейнери с данни, наречени таблици. Физически таблиците се съхраняват като 8 KB страници които могат да бъдат организирани в Heap или B-Tree Clustered таблици. ВКупа таблица, няма ред на сортиране, който контролира реда на данните вътре в страниците с данни и последователността на страниците в тази таблица, тъй като в тази таблица няма дефиниран клъстериран индекс, който да наложи механизма за сортиране. Ако клъстериран индекс е дефиниран в една колона от групата от колони на таблицата, данните ще бъдат сортирани вътре в страниците с данни въз основа на стойностите на ключовите колони за клъстериран индекс и страниците ще бъдат свързани заедно въз основа на тези ключови стойности на индекса. Тази сортирана таблица се нарича Клъстерирана таблица .
В SQL Server индексът се счита за важен и ефективен ключ в процеса на настройка на производителността. Целта на създаването на индекс е да ускори достъпа до основната таблица и да извлече исканите данни, без да се налага да сканирате всички редове на таблицата, за да върнете исканите данни. Можете да мислите за индекса на базата данни като указател на книгата, който ви помага бързо да намерите думите в книгата, без да се налага да четете цялата книга, за да намерите тази дума. Например, да предположим, че трябва да извлечете информация за конкретен клиент, използвайки клиентски идентификатор. Ако няма дефиниран индекс за колоната с идентификатор на клиента в тази таблица, SQL Server Engine проверява всички редове на таблицата, един по един, за да извлече клиента с предоставения идентификатор. Ако е дефиниран индекс за колоната Customer ID в тази таблица, SQL Server Engine ще търси исканите стойности на Customer ID в сортирания индекс, а не в основната таблица, за да извлече информация за клиента, намалявайки броя на сканираните редове, за да извлечете данните.
В SQL Server индексът е структуриран логически като 8K страници или индексни възли под формата на B-дърво. Структурата на B-Tree съдържа три нива:Root Level която включва една индексна страница в горната част на B-дървото, Ниво на листа който се намира в долната част на B-дървото и съдържа страници с данни и Междинно ниво който включва всички възли, разположени между корена и нивата на листа, със стойности на индексни ключове и указатели към следващите страници. Тази форма на B-дърво осигурява бърз начин за навигация в страниците с данни отляво надясно и отгоре надолу, въз основа на клавиша за индекс.
В SQL Server има два основни типа индекси, Клъстерен индекс, в който действителните данни се съхраняват на страниците на ниво лист на индекса, с възможност за създаване само на един клъстериран индекс за всяка таблица, тъй като данните вътре в страниците с данни и редът на страниците ще бъдат сортирани въз основа на клъстерирания индекс ключ. Ако дефинирате ограничение за първичен ключ във вашата таблица, клъстериран индекс ще бъде създаден автоматично, ако преди това не е бил дефиниран клъстериран индекс за тази таблица. Вторият тип индекси е Неклъстериран индекс който включва сортирано копие на колоните с ключ на индекса и указател към останалите колони в основната таблица или клъстерирания индекс, с възможност за създаване на до 999 неклъстерирани индекса за всяка таблица.
SQL Server ни предоставя други специални типове индекси, като Уникален индекс който се създава автоматично, когато се дефинира уникално ограничение, за да се наложи уникалността на конкретни стойности на колони, Съставен индекс в която повече от една ключова колона ще участва в ключа на индекса, Покриващ индекс в който всички колони, поискани от конкретна заявка, ще участват в ключа на индекса, Филтриран индекс това е оптимизиран неклъстериран индекс с предикат за филтриране за индексиране само на малка част от редовете на таблицата, Пространствен индекс който се създава върху колоните, които съхраняват пространствени данни, XML индекс, който е създаден върху XML двоични големи обекти (BLOB) в колони от тип данни XML, Индекс на Columnstore в който данните са организирани в колонен формат на данни, Пълнотекстов индекс който е създаден от SQL Server Full-Text Engine и Хеш индекс който се използва в оптимизирани за памет таблици.
Както наричах индекса на SQL Server, това е нож с две остриета , където SQL Server Query Optimizer може да се възползва от индекса, проектиран добре за подобряване на производителността на вашите приложения чрез ускоряване на процеса на извличане на данни. Обратно, индекс, който е проектиран по лош начин, няма да бъде избран от SQL Server Query Optimizer и ще влоши производителността на вашите приложения, като забави операциите за промяна на данните и ще изразходва хранилището ви, без да се възползвате от него в данните процеси на извличане. Ето защо е по-добре първо да следвате най-добрите практики и насоки за създаване на индекс, да проверите ефекта от създаването на среда за разработка и да намерите компромис между скоростта на операциите за извличане на данни и режийните разходи за добавяне на този индекс към операциите за промяна на данни и изискванията за пространство на този индекс, преди да го приложите към производствената среда.
Преди да създадете индекс, трябва да проучите различните аспекти, които влияят върху създаването и използването на индекса. Това включва типа от работното натоварване на базата данни, онлайн обработка на транзакции (OLTP) или онлайн аналитична обработка (OLAP), размерът на таблицата , характеристиките на колоните на таблицата , редът на сортиране от колоните в заявката, типа на индекса който съответства на заявката и свойствата за съхранение, като FILLFACTOR и PAD_INDEX опции, които контролират процента пространство на всяко ниво на листа и страниците на междинно ниво, които трябва да бъдат запълнени с данни.
Фрагментация на индекса на SQL сървър
Вашата работа като администратор на база данни не се ограничава до създаването на правилния индекс. След като индексът е създаден, трябва да наблюдавате използването на индекса и статистиката, например, трябва да знаете дали този индекс се използва лошо или изобщо не се използва. По този начин можете да предоставите правилното решение за поддържане на тези индекси или да ги замените с по-ефективни. По този начин ще поддържате най-високата приложима производителност за вашата система. Може да се запитате:Защо SQL Server Query Optimizer вече не използва моя индекс, въпреки че го правеше преди?
Отговорът е свързан главно с непрекъснатите промени в данните и схемите, които се извършват върху основната таблица, които трябва да бъдат отразени в индексите. С течение на времето и с всички тези промени индексните страници стават несортирани, което води до фрагментиране на индекса. Друга причина за фрагментацията е опит за вмъкване на нова стойност или актуализиране на текущата стойност, като новата стойност не се вписва в наличното в момента свободно пространство. В този случай страницата ще бъде разделена на две страници, където новата страница ще бъде създадена физически след последната страница. И можете да си представите четене от фрагментиран индекс и броя на страниците, които трябва да бъдат сканирани, и, разбира се, броя на извършените I/O операции за извличане на няколко записа поради разстоянието между тези страници. И поради тези допълнителни разходи за използване на този фрагментиран индекс, SQL Server Query Optimizer ще игнорира този индекс.
Различни начини за получаване на фрагментация на индекс
SQL Server ни предоставя различни начини да получим процента на фрагментация на индекса. Първият начин е да проверите процента на фрагментация на индекса в Индекса Свойства прозорец, под Фрагментация раздел, както е показано по-долу:
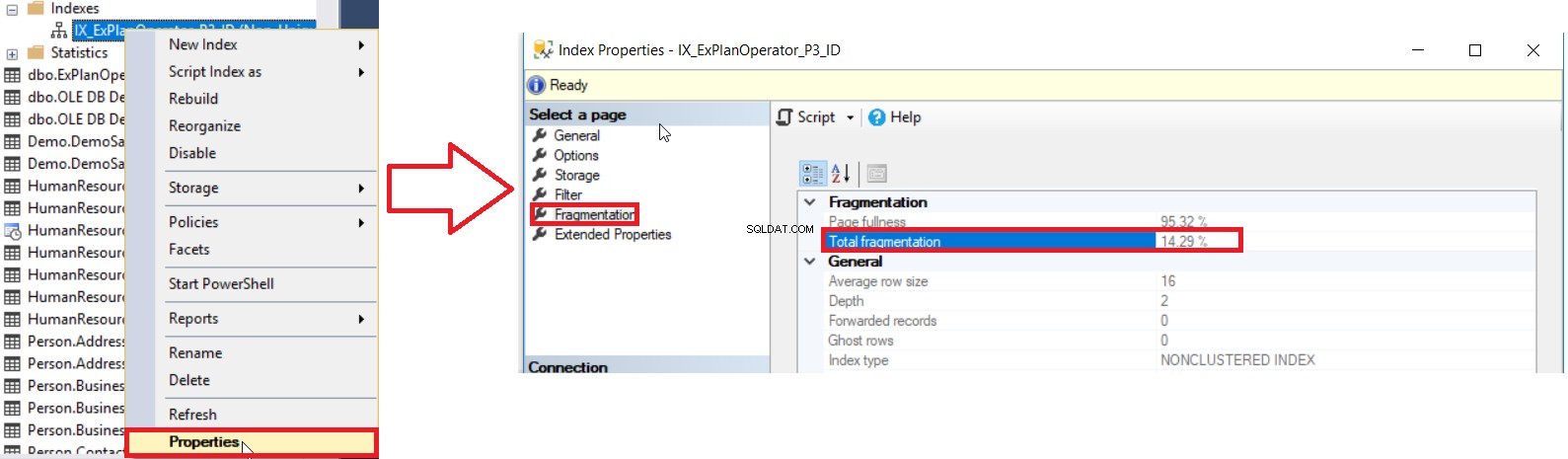
Но за да проверите нивото на фрагментация на множество индекси, първо трябва да извършите проверка на метода на потребителския интерфейс за всички индекси, един по един, което е операция, която губи време. Вторият наличен метод за проверка на нивото на фрагментация на всички индекси на базата данни е запитване на sys.dm_db_index_physical_stats DMF и присъединяване към sys.indexes DMV, за да извлече цялата информация за тези индекси, като се има предвид, че тези статистически данни ще бъдат обновени, когато Услугата на SQL Server се рестартира, като се използва заявка, подобна на следната:
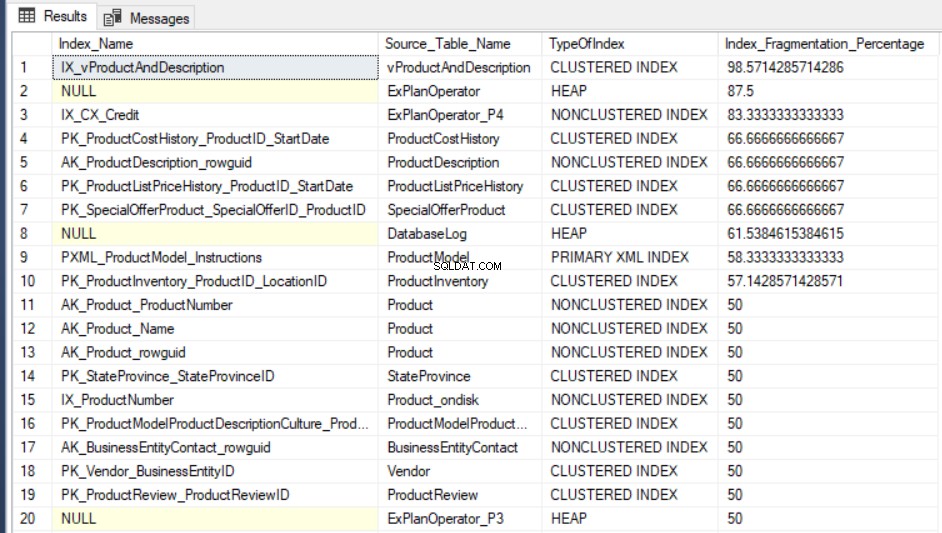
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Резултатът от заявката на AdventureWorks2016CTP3 базата данни за тестване ще бъде подобна на следното:
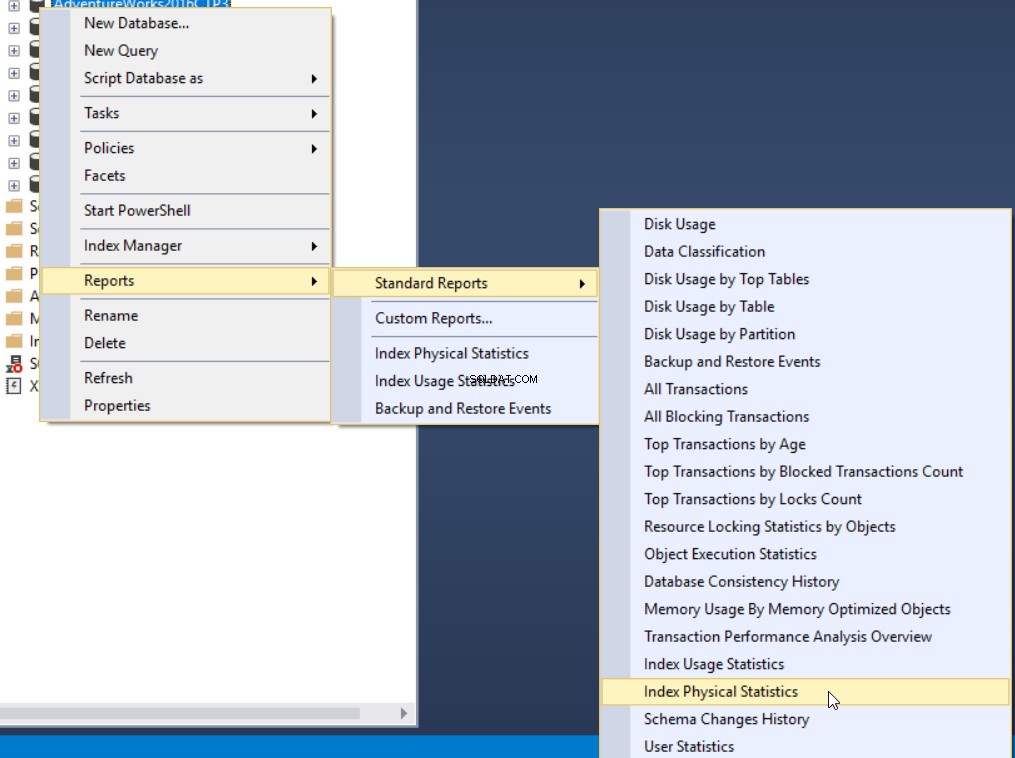
Третият метод за получаване на процента на фрагментация е да използвате вградения стандартен отчет на SQL Server, наречен Index Physical Statistics. Този отчет връща полезна информация за дяловете на индекса, процента на фрагментация, броя на страниците на всеки индексен дял и препоръки как да коригирате проблема с фрагментирането на индекса чрез повторно изграждане или реорганизиране на индекса. За да видите отчета, щракнете с десния бутон върху базата данни, изберете опцията Отчети, Стандартни отчети и изберете Индекс на физическа статистика, както е показано по-долу:
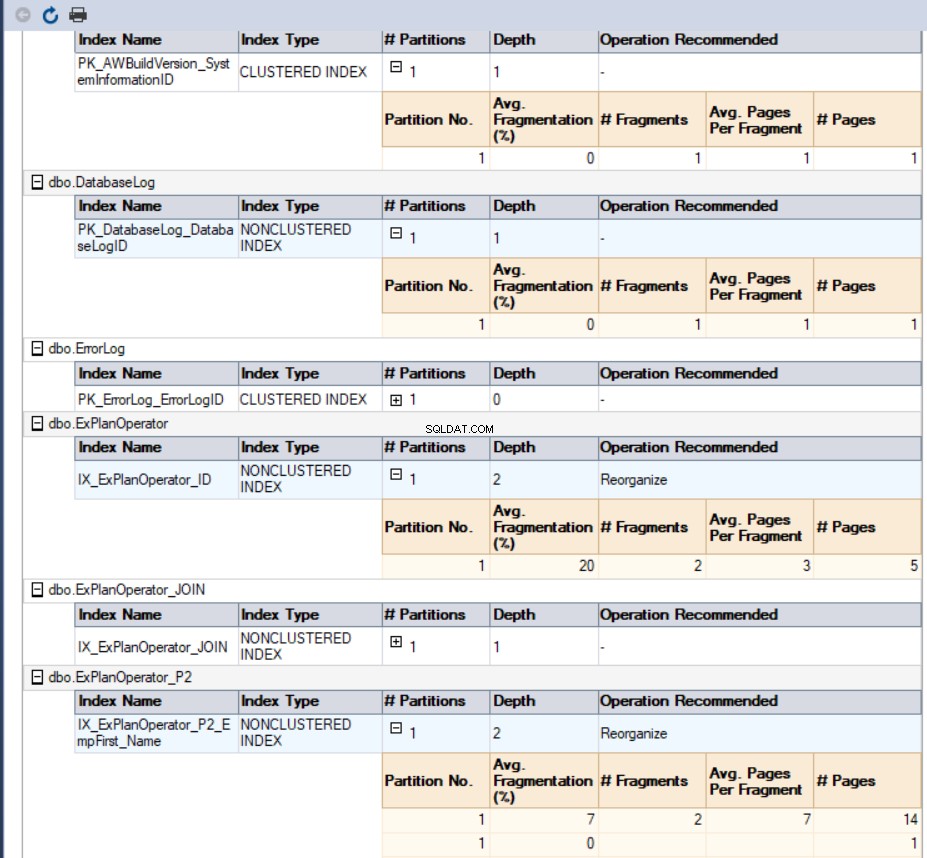
В нашия случай генерираният отчет ще изглежда така:
Последният и най-лесният начин за извличане на процента на фрагментация на всички индекси на базата данни е инструментът dbForge Index Manager. dbForge Index Manager инструментът е добавка, която може да бъде добавена към вашето SQL Server Management Studio за анализиране на индексите на базите данни на SQL Server, като ви предоставя много полезен отчет със състоянието на избраните индекси на база данни и предложения за поддръжка, за да коригирате тези проблеми с фрагментацията на индекса.
След като инсталирате добавката dbForge Index Manager към вашия SSMS, можете да я стартирате, като щракнете с десния бутон върху базата данни, която ще бъде сканирана, изберете Index Manager , след това Управление на фрагментацията на индекса както е показано по-долу:
Инструментът dbForge Index Manager ви позволява да получите цялостна картина на фрагментацията на избраните индекси на базата данни, с препоръка за правилните действия за отстраняване на този проблем, както е показано по-долу:

Инструментът dbForge Index Manager ви позволява също да превключвате между бази данни, като ви предоставя нов отчет след сканиране на тази база данни, както е показано по-долу:
Отчетът за фрагментация на индекса, генериран от инструмента dbForge Index Manager, може да бъде експортиран в CSV файл, за да се анализира състоянието на фрагментация на индекси, както е показано по-долу:
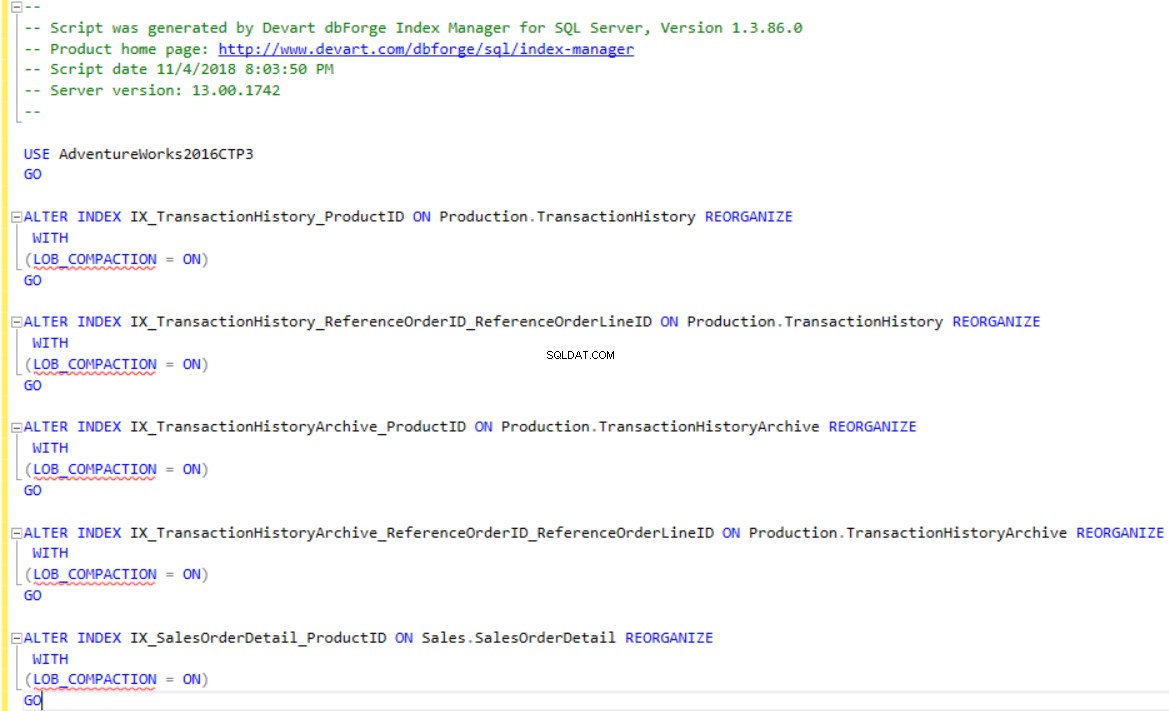
dbForge Index Manager ви позволява да генерирате T-SQL скриптове за повторно изграждане или реорганизиране на индексите съгласно препоръката на инструмента. Използвайте Промени в скрипта опция за показване или запазване на скрипта за индексите, които са фрагментирани, както е показано по-долу:
Инструментът dbForge Index Manager ви предоставя възможността да коригирате проблема с фрагментацията на индекса директно, като щракнете върху Fix бутон, който ще извърши препоръчаното действие директно върху избраните индекси, показвайки състоянието на коригиране в Резултата колона, както е показано по-долу:

Ако щракнете върху Повторно анализиране бутон, той ще сканира фрагментацията на индекса в базата данни отново след успешното изпълнение на операцията за корекция. Това, което е изброено тук в тази статия, е само въведение в това как инструментът dbForge Index Manager ще ни помогне да идентифицираме и коригираме проблеми с фрагментацията на индекса. Моята препоръка за вас е да го изтеглите и да проверите какво може да ви предложи този инструмент.
Полезни връзки:
- Основи на индекса
- Типове индекси
- Описани клъстерни и неклъстерирани индекси
- Клъстерни индексни структури
Полезен инструмент:
dbForge Index Manager – удобна добавка за SSMS за анализиране на състоянието на SQL индексите и отстраняване на проблеми с фрагментацията на индекса.



