Книгата на Крейг Ларман "Прилагане на UML с шаблони" описва 3-те често срещани решения на този проблем.
Вашите примери не са особено полезни - няма логическа причина да имате 3 различни начина за управление на името на човек във вашата база данни (въпреки че това се случва редовно поради странни начини за импортиране/експортиране на данни).
Въпреки това, много често е да има субект "лице", който може да бъде служител (с employee_id), контакт (с връзка към таблицата с перспективите) или клиент (с customer_id и връзка към таблицата с поръчки) .
В книгата на Ларман той дава 3 решения.
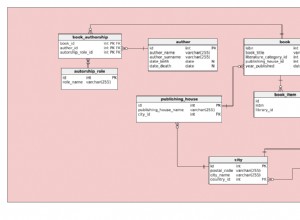
Една маса, за да управлявате всички Тук създавате една таблица с всички известни колони. Това създава разхвърляна таблица и прехвърля отговорността за познаването на правилата за запазване на всеки подклас към слоя на приложението - базата данни няма да наложи необходимостта клиентите да имат customer_id. Това обаче прави свързванията много по-лесни - всяка таблица, която трябва да се свърже с човек, може просто, добре, да се свърже с таблицата с хора.
Таблица за суперклас Това изчиства нещата, като извлича общите атрибути в една таблица - напр. "person" - и избутва специфичните за подклас полета към таблици на подкласове. Така че може да имате "person" като таблица на суперкласа и таблици "contact", "employee" и "customer" със специфични данни за подклас. Таблиците на подкласовете имат колона "person_id" за връзка към таблицата на суперкласа. Това е по-сложно – обикновено изисква допълнително присъединяване при извличане на данни – но и много по-малко податливо на грешки – не можете случайно да повредите модела на данни с грешка, която записва невалидни атрибути за „служител“.
Таблица за подклас - това е, което описахте. Той въвежда доста дублиране в модела на данните и често имате условни присъединявания - "присъединяване към таблица x, ако тип човек =y", което може да направи кода за достъп до данни труден.