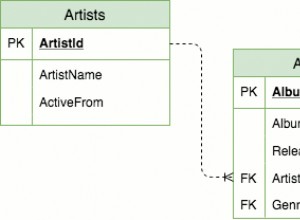
При липса на функции на прозореца можете да поръчате tbl и използвайте потребителски променливи, за да изчислите сами ранга върху вашите дялове (стойности за "дата"):
SELECT "date", -- D) Desired columns
id,
value,
rank
FROM (SELECT "date", -- C) Rank by date
id,
value,
CASE COALESCE(@partition, "date")
WHEN "date" THEN @rank := @rank + 1
ELSE @rank := 1
END AS rank,
@partition := "date" AS dummy
FROM (SELECT @rank := 0 AS rank, -- A) User var init
@partition := NULL AS partition) dummy
STRAIGHT_JOIN
( SELECT "date", -- B) Ordering query
id,
value
FROM tbl
ORDER BY date, value) tbl_ordered;
Актуализиране
И така, какво прави тази заявка?
Използваме потребителски променливи за да "превъртите" през сортиран набор от резултати, увеличавайки или нулиращи брояч (@rank ) в зависимост от това кой последователен сегмент от резултатния набор (проследен в @partition ) ние сме вътре.
В заявкаА ние инициализираме две потребителски променливи. В заявка B получаваме записите на вашата таблица в реда, от който се нуждаем:първо по дата и след това по стойност. А и B заедно правят извлечена таблица, tbl_ordered , това изглежда нещо подобно:
rank | partition | "date" | id | value
---- + --------- + ------ + ---- + -----
0 | NULL | d1 | id2 | 1
0 | NULL | d1 | id1 | 2
0 | NULL | d2 | id1 | 10
0 | NULL | d2 | id2 | 11
Не забравяйте, че не ни интересуват колоните dummy.rank и dummy.partition — те са просто случайности в начина, по който инициализираме променливите @rank и @partition .
В заявка C преглеждаме записите на извлечената таблица. Това, което правим, е повече или по-малко това, което прави следният псевдокод:
rank = 0
partition = nil
foreach row in fetch_rows(sorted_query):
(date, id, value) = row
if partition is nil or partition == date:
rank += 1
else:
rank = 1
partition = date
stdout.write(date, id, value, rank, partition)
Накрая заявете D проектира всички колони от C освен за колоната, съдържаща @partition (който нарекохме dummy и не е необходимо да се показват).