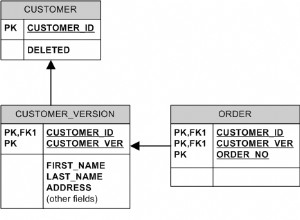
Бързо решение би било да филтрирате в подзаявката:
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
AND s.id IN(
SELECT g.site_id
FROM gstats g
WHERE g.start_date > '2015-04-30' AND g.site_id = s.id
GROUP BY g.site_id
HAVING SUM(g.results) > 100
)
GROUP BY s.id
ORDER BY dcount ASC
Тъй като в противен случай правите такава заявка за групиране за всеки възможен кандидат. Можем да направим това по-елегантно с EXISTS :
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
AND EXISTS (
SELECT 1
FROM gstats g
WHERE g.site_id = s.id AND g.start_date > '2015-04-30'
HAVING SUM(g.results) > 100
)
GROUP BY s.id
ORDER BY dcount ASC
Но все още не сме готови, сега ще използваме EXISTS за всеки елемент. Това е странно, тъй като заявката зависи само от s.id , така че зависи само от групата , а не отделните редове. Значи потенциал ускоряване, но това зависи от размерите на таблиците и т.н. е да се премести условието в HAVING изявление:
SELECT count(d.id) AS dcount, s.id, s.name
FROM sites s
LEFT JOIN deals d ON (s.id = d.site_id AND d.is_active = 1)
WHERE (s.is_active = 1)
GROUP BY s.id
ORDER BY dcount ASC
HAVING EXISTS (
SELECT 1
FROM gstats g
WHERE g.site_id = s.id AND g.start_date > '2015-04-30'
HAVING SUM(g.results) > 100
)