Вероятно ще бъде по-добре да оставите MySql да вземе решение за плана на заявката. Има голяма вероятност сканирането на индекс да бъде по-малко ефективно от пълното сканиране на таблицата.
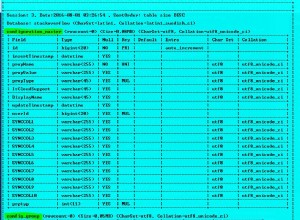
Има две структури от данни на диска за тази таблица
- Самата маса; и
- Индексът на B-дървото на първичния ключ.
Когато стартирате заявка, оптимизаторът има две опции за достъп до данните:
SELECT * FROM userapplication WHERE application_id > 1025;
Използване на индекса
- Сканирайте индекса на B-Tree, за да намерите адреса на всички редове, където
application_id > 1025 - Прочетете съответните страници на таблицата, за да получите данните за тези редове.
Не се използва индексът
Сканирайте цялата таблица и изберете подходящите записи.
Избор на най-добрата стратегия
Работата на оптимизатора на заявки е да избере най-ефективната стратегия за получаване на данните, които искате. Ако има много редове с application_id > 1025 тогава всъщност може да бъде по-малко ефективно използването на индекса. Например, ако 90% от записите имат application_id > 1025 тогава оптимизаторът на заявки ще трябва да сканира около 90% от крайните възли на индекса на b-дървото и след това да прочете поне 90% от таблицата, за да получи действителните данни; това би включвало четене на повече данни от диска, отколкото просто сканиране на таблицата.