Използването на клъстер Galera е чудесен начин за изграждане на високодостъпна среда за MySQL или MariaDB. Това е клъстерна среда без споделено нищо, която може да бъде мащабирана дори над 12-15 възела. Galera обаче има някои ограничения. Той блести в среди с ниска латентност и въпреки че може да се използва в WAN, производителността е ограничена от латентността на мрежата. Производителността на Galera също може да бъде засегната, ако един от възлите започне да се държи неправилно. Например, прекомерното натоварване на един от възлите може да го забави, което води до по-бавна обработка на записите и това ще повлияе на всички други възли в клъстера. От друга страна е доста невъзможно да управлявате бизнес, без да анализирате данните си. Такъв анализ обикновено изисква изпълнение на тежки заявки, което е доста различно от натоварването на OLTP. В тази публикация в блога ще обсъдим лесен начин за изпълнение на аналитични заявки за данни, съхранявани в Galera Cluster за MySQL или MariaDB, по начин, който да не влияе върху производителността на основния клъстер.
Как да изпълнявам аналитични заявки в Galera Cluster?
Както казахме, изпълняването на продължителни заявки директно в клъстер на Galera е изпълнимо, но може би не е толкова добра идея. В зависимост от хардуера, това може да бъде приемливо решение (ако използвате силен хардуер и няма да изпълнявате многонишково аналитично натоварване), но дори и използването на процесора няма да е проблем, фактът, че един от възлите ще има смесено натоварване ( OLTP и OLAP) сами по себе си ще представляват някои предизвикателства пред производителността. OLAP заявките ще извадят данните, необходими за вашето OLTP работно натоварване, от буферния пул и това ще забави вашите OLTP заявки. За щастие има прост, но ефективен начин за разделяне на аналитичното работно натоварване от обикновените заявки – подчинен асинхронен репликация.
Подчинената репликация е много просто решение - всичко, от което се нуждаете, е просто друг хост, който може да бъде осигурен и асинхронната репликация трябва да бъде конфигурирана от Galera Cluster към този възел. При асинхронна репликация подчинената няма да повлияе на останалата част от клъстера по никакъв начин. Без значение дали е силно натоварен, използва различен (по-малко мощен) хардуер, той просто ще продължи да се репликира от основния клъстер. Най-лошият сценарий е, че подчинения за репликация ще започне да изостава, но след това от вас зависи да приложите многонишкова репликация или евентуално да увеличите подчинения за репликация.
След като робът за репликация започне да работи, трябва да изпълните по-тежките заявки към него и да разтоварите клъстера Galera. Това може да стане по няколко начина, в зависимост от вашата настройка и среда. Ако използвате ProxySQL, можете лесно да насочвате заявки към аналитичното подчинено устройство въз основа на изходния хост, потребител, схема или дори самата заявка. В противен случай вашето приложение ще зависи от изпращането на аналитични заявки до правилния хост.
Настройването на роб за репликация не е много сложно, но все пак може да бъде трудно, ако не сте опитни с MySQL и инструменти като xtrabackup. Целият процес ще се състои от настройка на хранилището на нов сървър и инсталиране на MySQL база данни. След това ще трябва да осигурите този хост, като използвате данни от клъстер Galera. Можете да използвате xtrabackup за това, но други инструменти като mydumper/myloader или дори mysqldump също ще работят (стига да ги изпълните правилно). След като данните са там, ще трябва да настроите репликацията между главен възел на Galera и подчинения за репликация. И накрая, ще трябва да преконфигурирате вашия прокси слой, за да включите новия подчинен и да насочите трафика към него или да направите промени в начина, по който приложението ви се свързва с базата данни, за да пренасочите част от натоварването към подчинения за репликация.
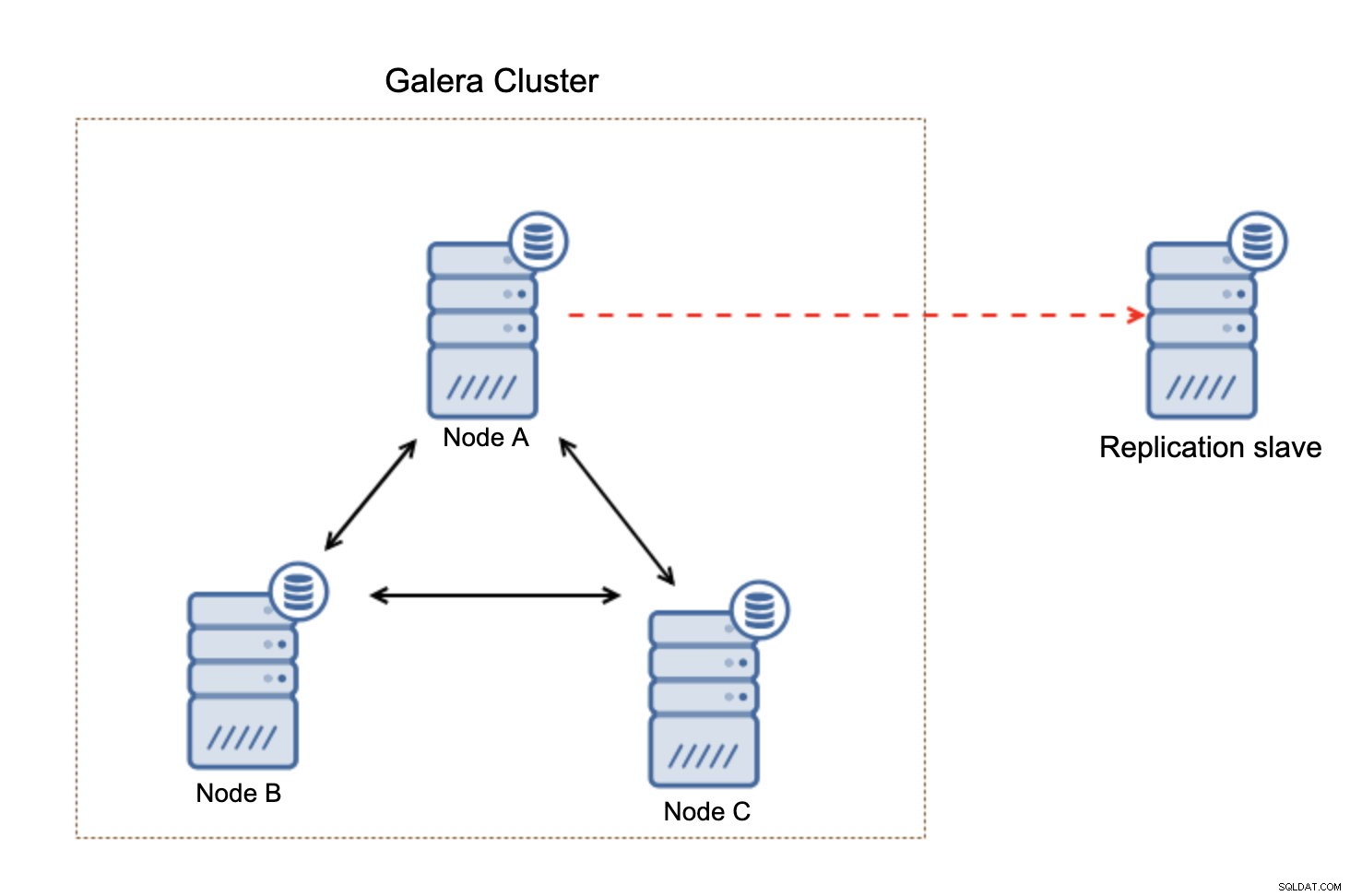
Това, което е важно да имате предвид, тази настройка не е устойчива. Ако „главният“ възел на Galera изпадне, връзката за репликация ще бъде прекъсната и ще предприеме ръчно действие за подчиняване на репликата от друг главен възел в клъстера на Galera.
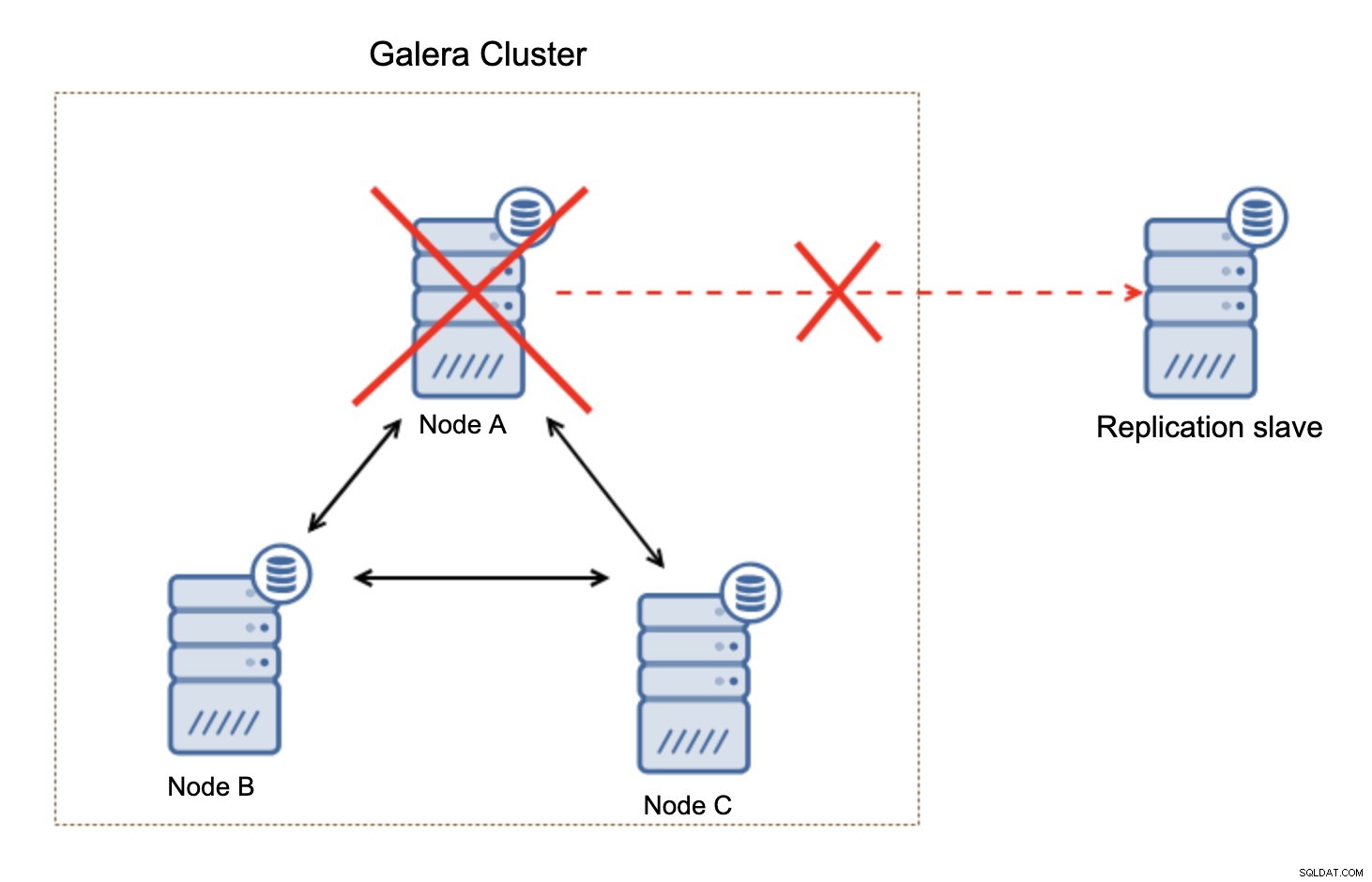
Това не е голяма работа, особено ако използвате репликация с GTID (Global Transaction ID), но трябва да идентифицирате, че репликацията е повредена и след това да предприемете ръчни действия.
Как да настроя асинхронния подчинен на Galera Cluster с помощта на ClusterControl?
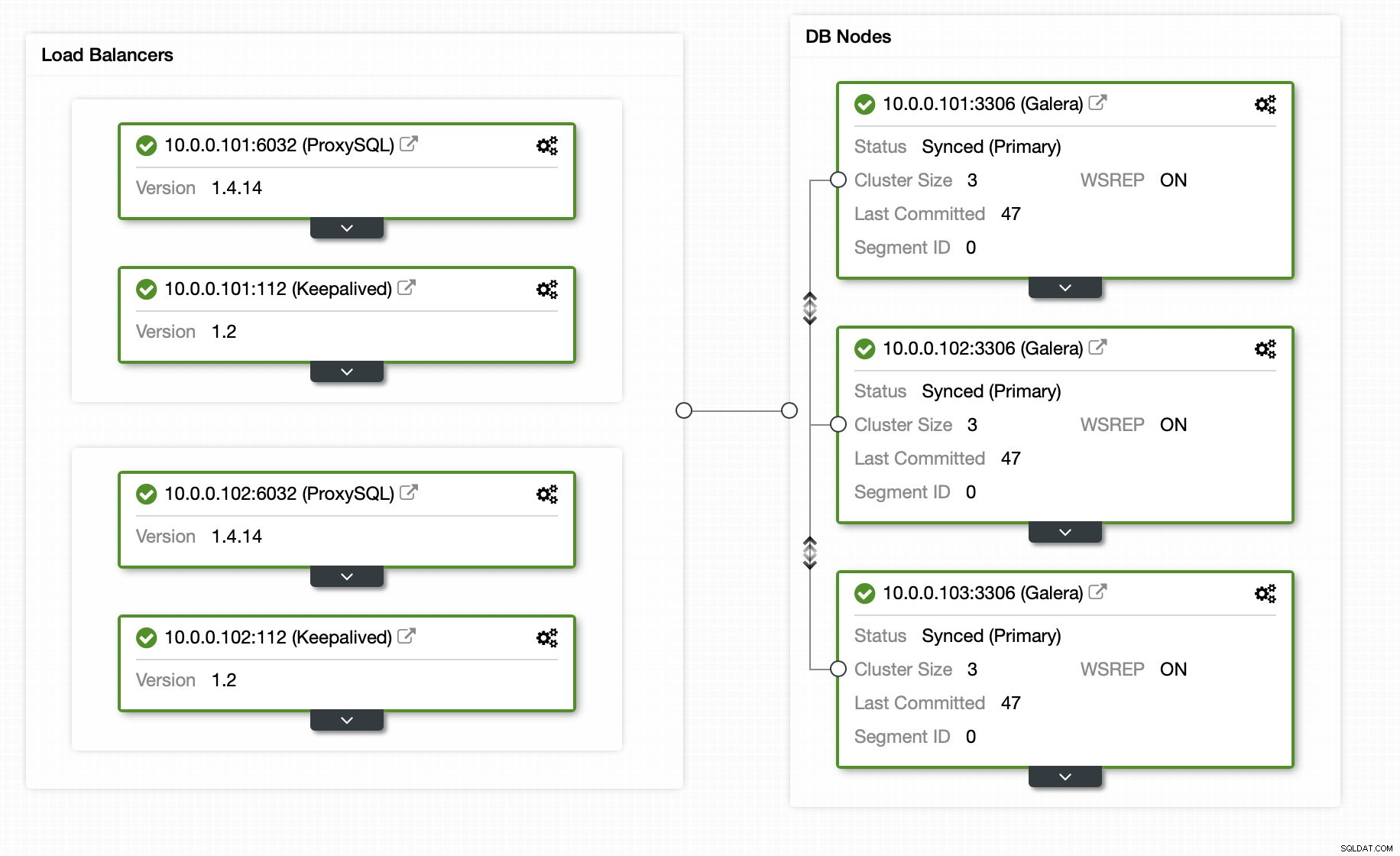
За щастие, ако използвате ClusterControl, целият процес може да бъде автоматизиран и изисква само шепа щраквания. Първоначалното състояние вече е настроено с помощта на ClusterControl – клъстер Galera с 3 възела с 2 възела ProxySQL и 2 възела Keepalived за висока наличност както на базата данни, така и на прокси слоя.
Добавянето на подчинения за репликация е само на едно щракване разстояние:
Репликацията, очевидно, изисква активиране на двоични регистрационни файлове. Ако нямате активирани binlogs на вашите възли на Galera, можете да го направите и от ClusterControl. Моля, имайте предвид, че активирането на двоични регистрационни файлове ще изисква рестартиране на възел за прилагане на промените в конфигурацията.
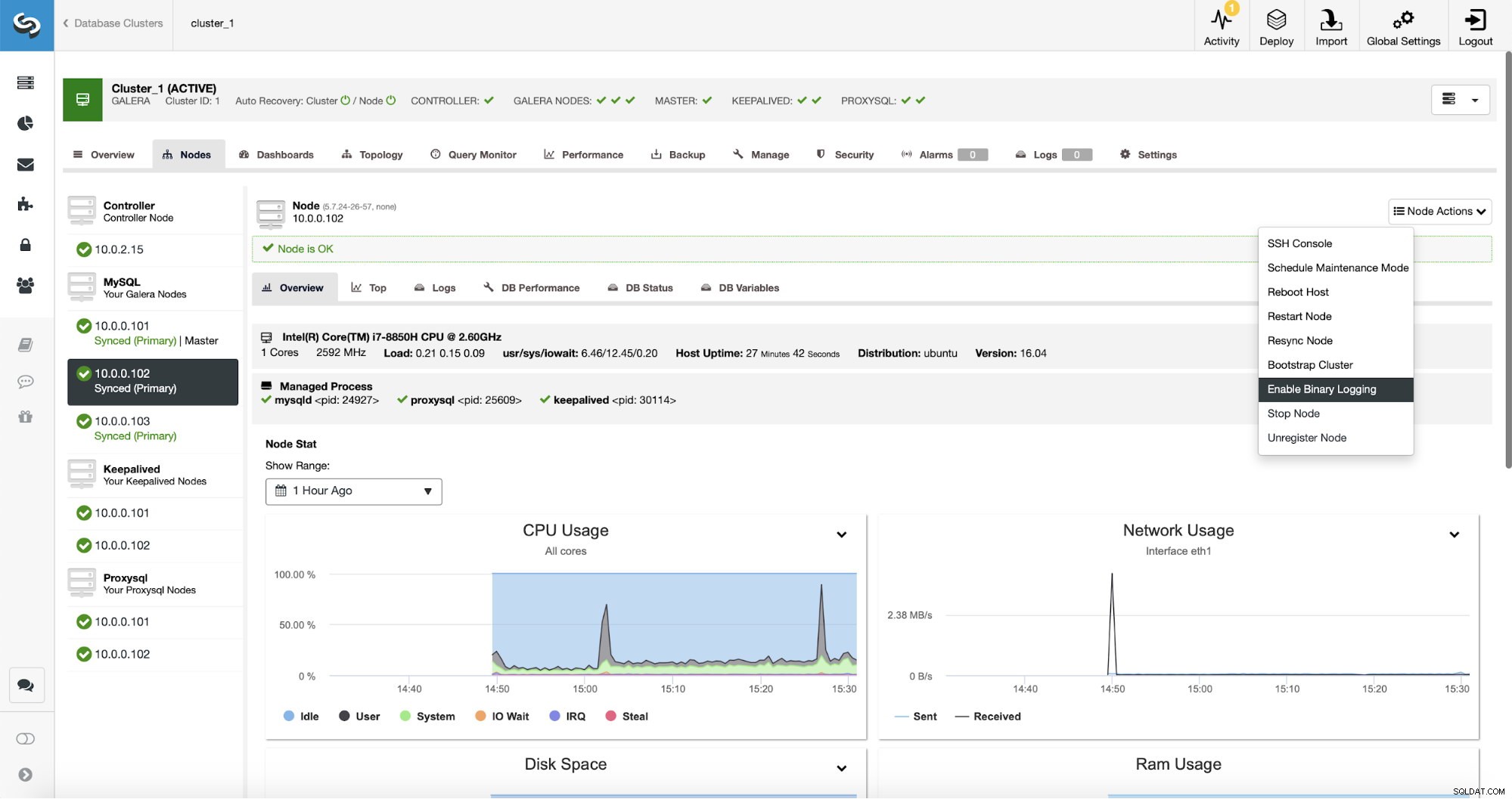
Дори ако един възел в клъстера има активирани двоични регистрационни файлове (маркирани като „Master“ на екранната снимка по-горе), все пак е добре да активирате двоичен регистрационен файл на поне още един възел. ClusterControl може автоматично да преодолява подчинения за репликация, след като открие, че главният възел Galera се е сринал, но за това е необходим друг главен възел с активирани двоични регистрационни файлове или няма да има на какво да премине.
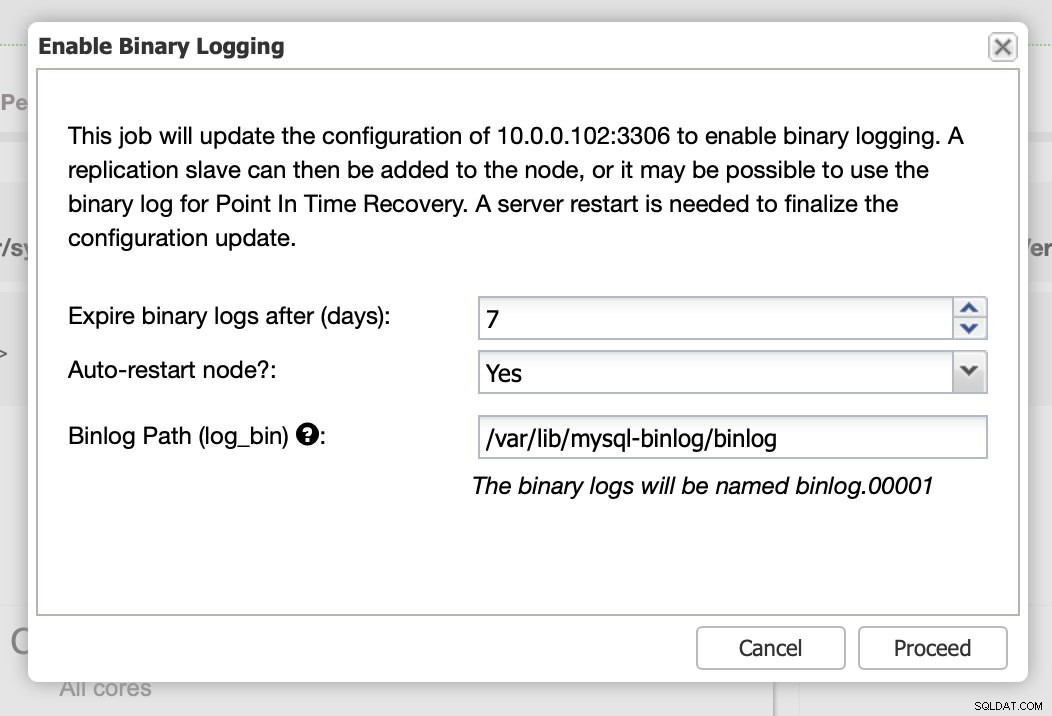
Както казахме, активирането на двоични регистрационни файлове изисква рестартиране. Можете или да го изпълните веднага, или просто да направите промени в конфигурацията и да извършите рестартирането по някое друго време.
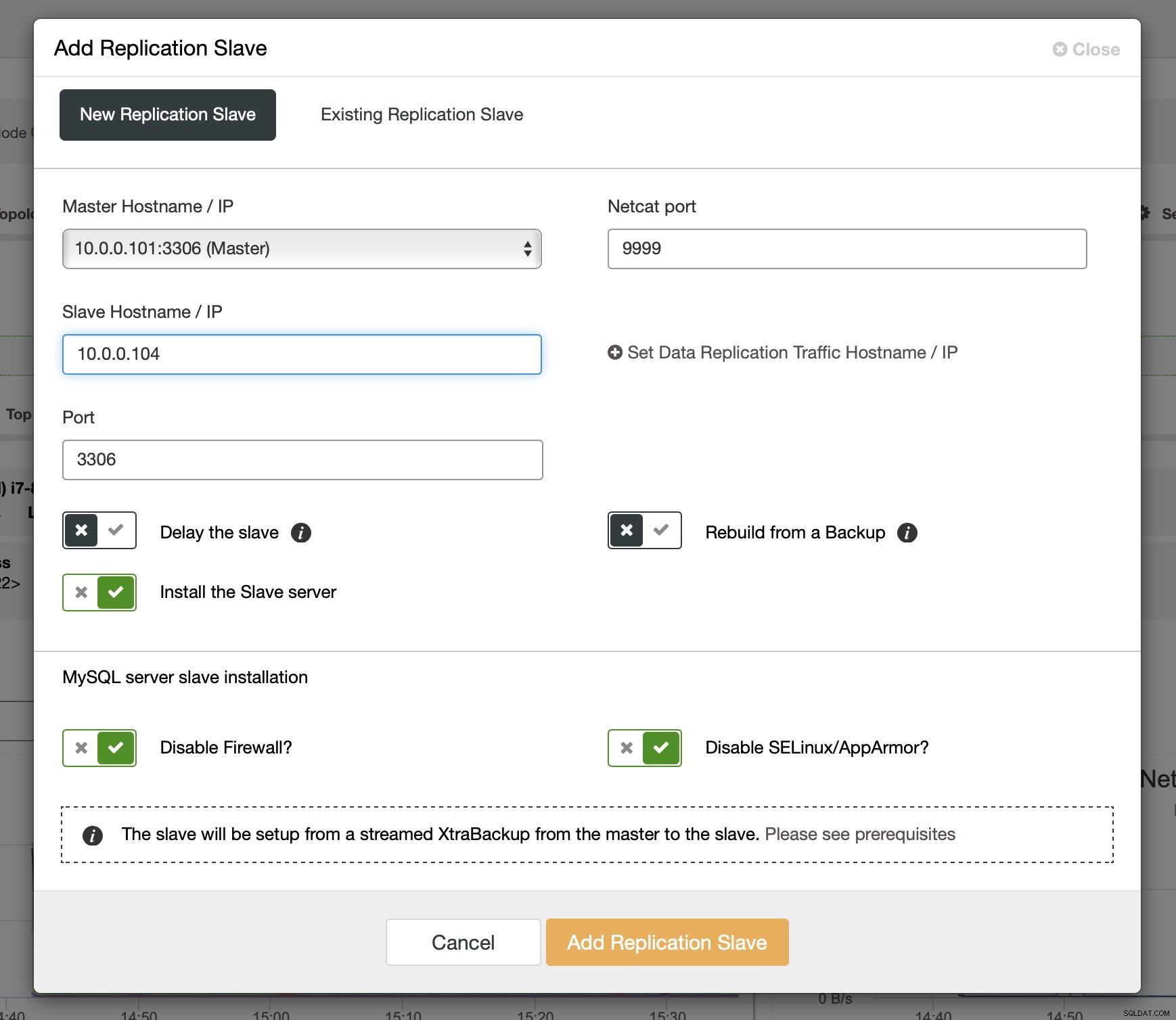
След като binlogs са активирани на някои от възлите на Galera, можете да продължите с добавянето на подчинения за репликация. В диалоговия прозорец трябва да изберете главния хост, да подадете името на хоста или IP адреса на подчинения. Ако имате скорошни архиви под ръка (което трябва да направите), можете да използвате такъв, за да осигурите подчинения. В противен случай ClusterControl ще го осигури с помощта на xtrabackup – всички скорошни основни данни ще бъдат предавани поточно към подчинения и след това репликацията ще бъде конфигурирана.
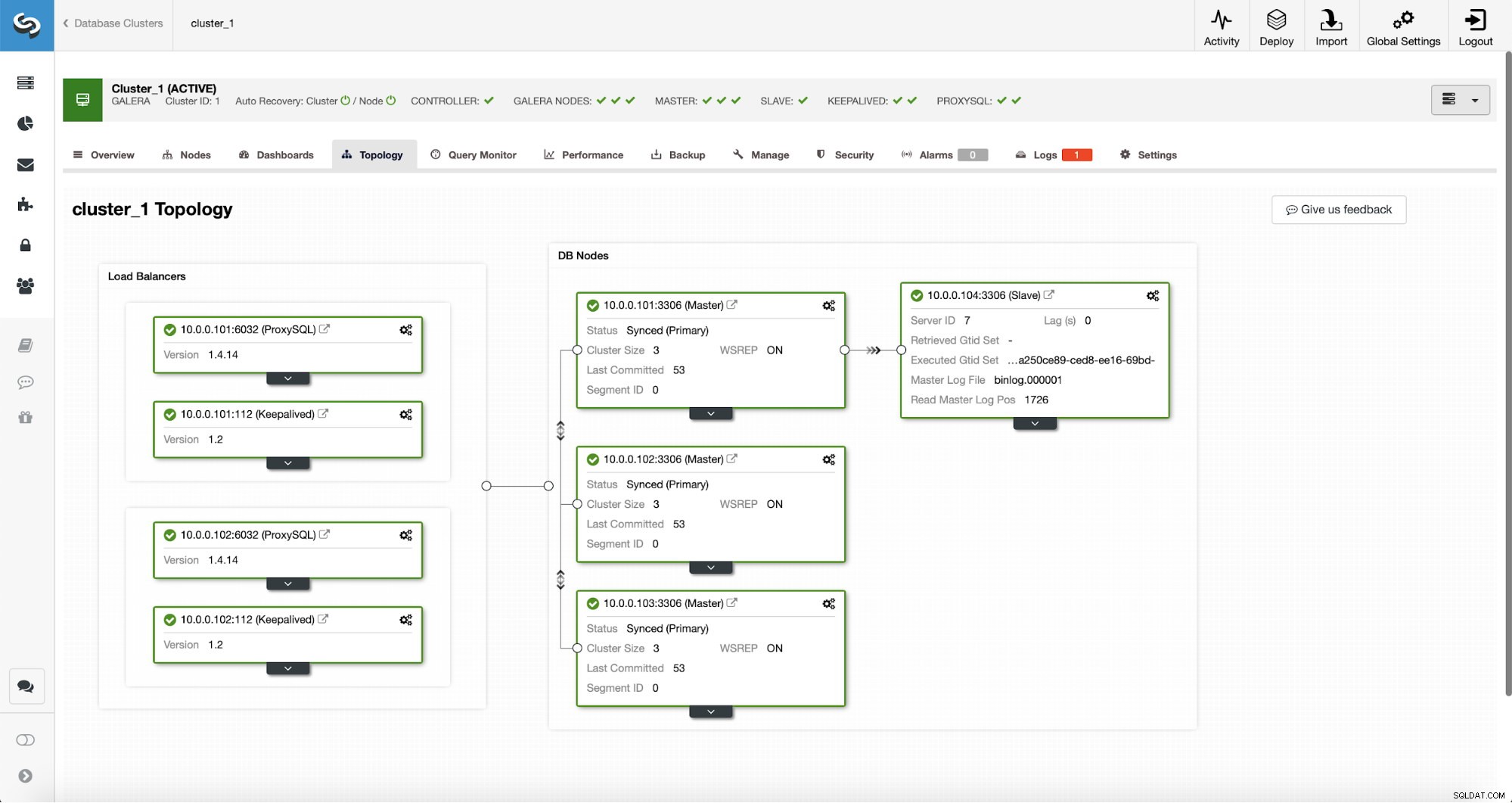
След приключване на заданието към клъстера е добавен подчинен репликация. Както беше посочено по-рано, ако 10.0.0.101 умре, друг хост в клъстера Galera ще бъде избран като главен и ClusterControl автоматично ще подчини 10.0.0.104 от друг възел.
Тъй като използваме ProxySQL, трябва да го конфигурираме. Ще добавим нов сървър в ProxySQL.
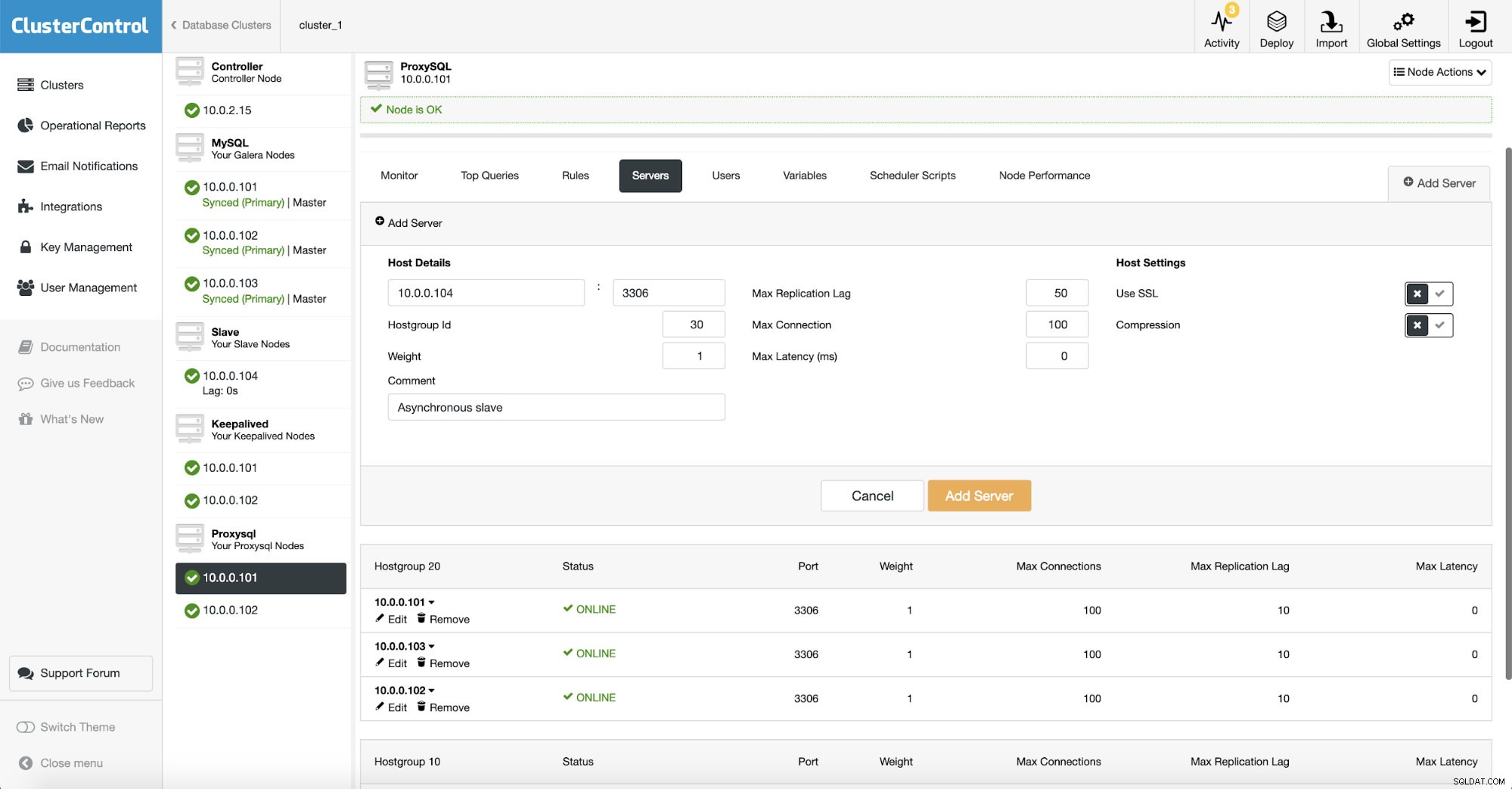
Създадохме друга хостгрупа (30), където поставихме нашия асинхронен подчинен. Също така увеличихме „Максималното забавяне на репликацията“ на 50 секунди от 10 по подразбиране. От вашите бизнес изисквания зависи колко зле може да изостава подчинението на анализа, преди да се превърне в проблем.
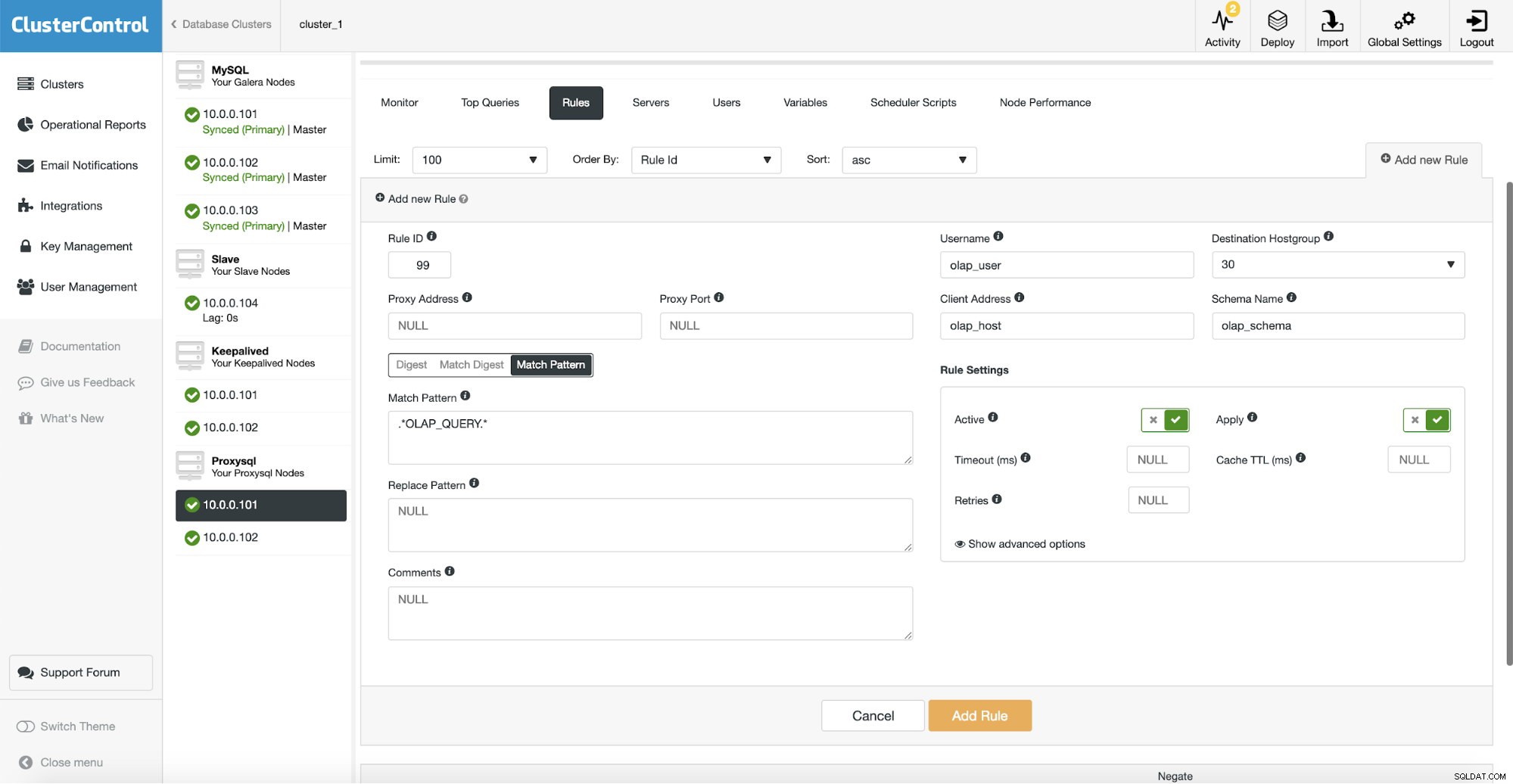
След това трябва да конфигурираме правило за заявка, което да съответства на нашия OLAP трафик и да го насочи към OLAP хост групата (30). На екранната снимка по-горе попълнихме няколко полета - това не е задължително. Обикновено ще трябва да използвате един, най-много два от тях. Снимката на екрана по-горе служи като пример, за да можем лесно да видим, че можете да съпоставите заявки с помощта на схема (ако имате отделна схема с аналитични данни), име на хост/IP (ако OLAP заявките се изпълняват от някакъв конкретен хост), потребител (ако приложението използва конкретен потребител за аналитични заявки. Можете също да съпоставите заявки директно, като подадете пълна заявка или като ги маркирате с SQL коментари и оставите ProxySQL да насочи всички заявки с низ „OLAP_QUERY“ към нашата аналитична хост група.
Както можете да видите, благодарение на ClusterControl успяхме да разположим роб за репликация в Galera Cluster само с няколко щраквания. Някои може да твърдят, че MySQL не е най-подходящата база данни за аналитично натоварване и ние сме склонни да се съгласим. Можете лесно да разширите тази настройка, като използвате ClickHouse и като настроите репликация от асинхронен подчинен към ClickHouse колонно хранилище за данни за много по-добра производителност на аналитичните заявки. Описахме тази настройка в една от по-ранните публикации в блога.