В света на информационните технологии автоматизацията не е нещо ново за повечето от нас. Всъщност повечето организации го използват за различни цели в зависимост от техния вид работа и цели. Например анализаторите на данни използват автоматизация за генериране на отчети, системните администратори използват автоматизация за своите повтарящи се задачи, като почистване на дисково пространство, а разработчиците използват автоматизация, за да автоматизират процеса на разработка.
В днешно време има много налични инструменти за автоматизация за ИТ и могат да бъдат избрани, благодарение на ерата на DevOps. Кой е най-добрият инструмент? Отговорът е предвидим „зависи“, тъй като зависи от това, което се опитваме да постигнем, както и от настройката на нашата среда. Някои от инструментите за автоматизация са Terraform, Bolt, Chef, SaltStack и един много модерен е Ansible. Ansible е ИТ машина с отворен код без агенти, която може да автоматизира внедряването на приложения, управлението на конфигурацията и ИТ оркестрацията. Ansible е основана през 2012 г. и е написана на най-популярния език Python. Той използва учебник за изпълнение на цялата автоматизация, където всички конфигурации са написани на разбираем от човека език, YAML.
В днешната публикация ще научим как да използваме Ansible за внедряване на база данни на Postgresql.
Какво прави Ansible специален?
Причината, поради която ansible се използва главно поради неговите характеристики. Тези характеристики са:
-
Всичко може да бъде автоматизирано с помощта на прост, четим от човека език YAML
-
Няма да бъде инсталиран агент на отдалечената машина (архитектура без агент)
-
Конфигурацията ще бъде прехвърлена от вашата локална машина към сървъра от вашата локална машина (push модел)
-
Разработено с помощта на Python (един от популярните езици, използвани в момента) и много библиотеки могат да бъдат избрани от
-
Колекция от модули Ansible, внимателно подбрани от инженерния екип на Red Had
Начинът, по който Ansible работи
Преди Ansible да може да изпълнява каквито и да е оперативни задачи към отдалечените хостове, трябва да го инсталираме в един хост, който ще стане възел на контролера. В този възел на контролера ще организираме всички задачи, които бихме искали да изпълняваме в отдалечените хостове, известни също като управлявани възли.
Контролерният възел трябва да разполага с инвентара на управляваните възли и софтуера Ansible, за да го управлява. Необходимите данни, които да се използват от Ansible, като име на хост или IP адрес на управляван възел, ще бъдат поставени в този инвентар. Без подходящ инвентар, Ansible не може да направи автоматизацията правилно. Вижте тук, за да научите повече за инвентара.
Ansible е без агент и използва SSH за натискане на промените, което означава, че не е нужно да инсталираме Ansible във всички възли, но всички управлявани възли трябва да имат инсталирани python и всички необходими библиотеки на python. И възелът на контролера, и управляваните възли трябва да бъдат зададени като без парола. Струва си да се спомене, че връзката между всички възли на контролера и управляваните възли е добра и е тествана правилно.
За тази демонстрация осигурих 4 виртуални машини Centos 8 с помощта на vagrant. Единият ще действа като контролен възел, а другите 2 виртуални машини ще действат като възли на базата данни, които ще бъдат разгърнати. Не навлизаме в подробности как да инсталирате Ansible в тази публикация в блога, но в случай, че искате да видите ръководството, не се колебайте да посетите тази връзка. Имайте предвид, че използваме 3 възела, за да настроим топология на поточно репликация, с един основен и 2 възела в режим на готовност. В днешно време много производствени бази данни са в настройка с висока наличност и настройката с 3 възела е често срещана.
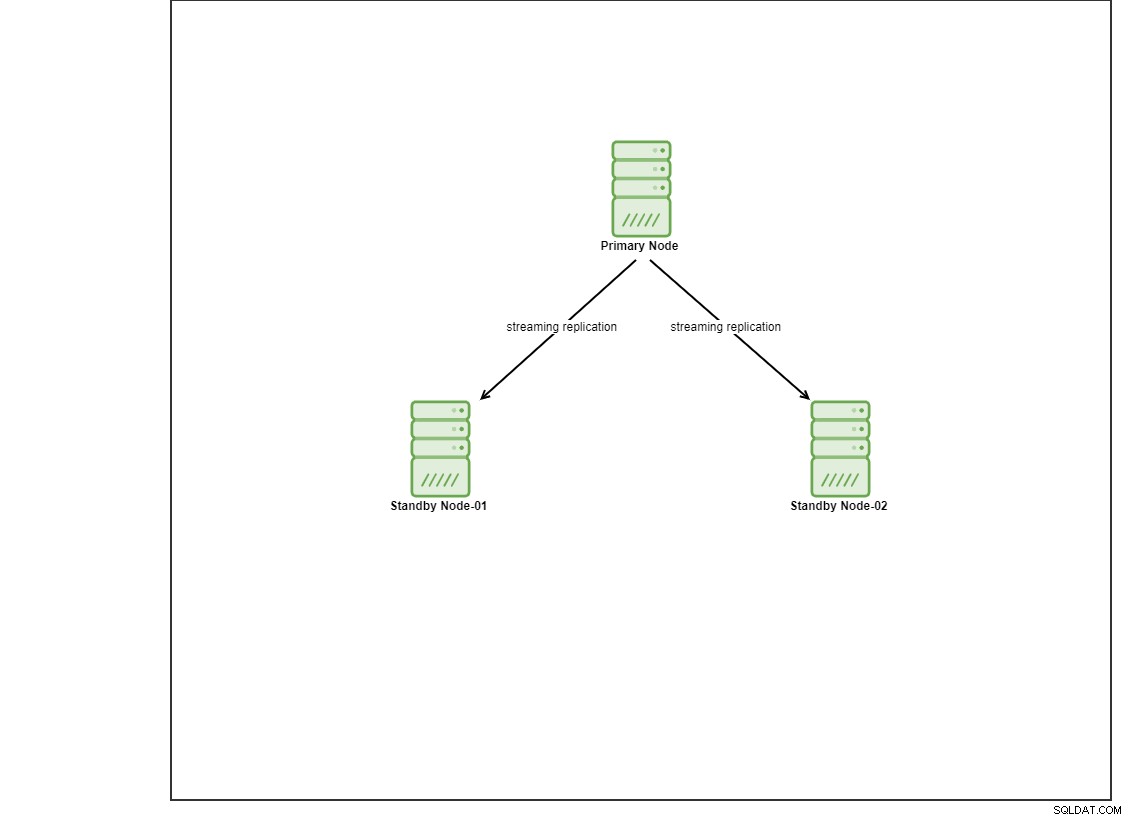
Инсталиране на PostgreSQL
Има няколко начина за инсталиране на PostgreSQL с помощта на Ansible. Днес ще използвам Ansible Roles, за да постигна тази цел. Ansible Roles накратко е набор от задачи за конфигуриране на хост да служи на определена цел, като конфигуриране на услуга. Ролите на Ansible се дефинират с помощта на YAML файлове с предварително дефинирана структура на директории, достъпна за изтегляне от портала Ansible Galaxy.
Ansible Galaxy, от друга страна, е хранилище за Ansible Roles, които са достъпни за поставяне директно във вашите Playbooks, за да рационализирате вашите проекти за автоматизация.
За тази демонстрация избрах ролите, поддържани от dudefellah. За да можем да използваме тази роля, трябва да я изтеглим и инсталираме на възела на контролера. Задачата е доста проста и може да бъде изпълнена, като изпълните следната команда, при условие че Ansible е инсталиран на вашия контролен възел:
$ ansible-galaxy install dudefellah.postgresqlТрябва да видите следния резултат, след като ролята е инсталирана успешно във вашия контролен възел:
$ ansible-galaxy install dudefellah.postgresql
- downloading role 'postgresql', owned by dudefellah
- downloading role from https://github.com/dudefellah/ansible-role-postgresql/archive/0.1.0.tar.gz
- extracting dudefellah.postgresql to /home/ansible/.ansible/roles/dudefellah.postgresql
- dudefellah.postgresql (0.1.0) was installed successfully
За да инсталираме PostgreSQL, използвайки тази роля, трябва да се направят няколко стъпки. Тук идва Ansible Playbook. Ansible Playbook е мястото, където можем да напишем Ansible код или колекция от скриптове, които бихме искали да изпълняваме на управляваните възли. Ansible Playbook използва YAML и се състои от една или повече пиеси, изпълнявани в определен ред. Можете да дефинирате хостове, както и набор от задачи, които искате да изпълнявате на тези назначени хостове или управлявани възли.
Всички задачи ще бъдат изпълнени като ansible потребител, който е влязъл. За да можем да изпълняваме задачите с различен потребител, включително „root“, можем да използваме сталі. Нека да разгледаме pg-play.yml по-долу:
$ cat pg-play.yml
- hosts: pgcluster
become: yes
vars_files:
- ./custom_var.yml
roles:
- role: dudefellah.postgresql
postgresql_version: 13Както можете да видите, дефинирах хостовете като pgcluster и използвам postane, така че Ansible да изпълнява задачите с привилегията sudo. Потребителят vagrant вече е в групата sudoer. Също така дефинирах ролята, която инсталирах dudefellah.postgresql. pgcluster е дефиниран във файла hosts, който създадох. В случай, че се чудите как изглежда, можете да разгледате по-долу:
$ cat pghost
[pgcluster]
10.10.10.11 ansible_user=ansible
10.10.10.12 ansible_user=ansible
10.10.10.13 ansible_user=ansibleВ допълнение към това създадох друг персонализиран файл (custom_var.yml), в който включих цялата конфигурация и настройки за PostgreSQL, които бих искал да внедря. Подробностите за персонализирания файл са както следва:
$ cat custom_var.yml
postgresql_conf:
listen_addresses: "*"
wal_level: replica
max_wal_senders: 10
max_replication_slots: 10
hot_standby: on
postgresql_users:
- name: replication
password: example@sqldat.com
privs: "ALL"
role_attr_flags: "SUPERUSER,REPLICATION"
postgresql_pg_hba_conf:
- { type: "local", database: "all", user: "all", method: "trust" }
- { type: "host", database: "all", user: "all", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "0.0.0.0/0", method: "md5" }
- { type: "host", database: "replication", user: "replication", address: "127.0.0.1/32", method: "md5" }За да стартираме инсталацията, всичко, което трябва да направим, е да изпълним следната команда. Няма да можете да изпълните командата ansible-playbook без създадения файл playbook (в моя случай това е pg-play.yml).
$ ansible-playbook pg-play.yml -i pghostСлед като изпълних тази команда, тя ще изпълни няколко задачи, дефинирани от ролята, и ще покаже това съобщение, ако командата е изпълнена успешно:
PLAY [pgcluster] *************************************************************************************
TASK [Gathering Facts] *******************************************************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Load platform variables] ***********************************************
ok: [10.10.10.11]
ok: [10.10.10.12]
TASK [dudefellah.postgresql : Set up role-specific facts based on some inputs and the OS distribution] ***
included: /home/ansible/.ansible/roles/dudefellah.postgresql/tasks/role_facts.yml for 10.10.10.11, 10.10.10.12След като ansible завърши задачите, влязох в подчинения (n2), спрях услугата PostgreSQL, премахнах съдържанието на директорията с данни (/var/lib/pgsql/13/data/) и изпълнете следната команда, за да стартирате задачата за архивиране:
$ sudo -u postgres pg_basebackup -h 10.10.10.11 -D /var/lib/pgsql/13/data/ -U replication -P -v -R -X stream -C -S slaveslot1
10.10.10.11 is the IP address of the master. We can now verify the replication slot by logging into the master:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_replication_slots;
-[ RECORD 1 ]-------+-----------
slot_name | slaveslot1
plugin |
slot_type | physical
datoid |
database |
temporary | f
active | t
active_pid | 63854
xmin |
catalog_xmin |
restart_lsn | 0/3000148
confirmed_flush_lsn |
wal_status | reserved
safe_wal_size |Можем също да проверим състоянието на репликацията в режим на готовност, като използваме следната команда, след като стартираме обратно PostgreSQL услугата:
$ sudo -u postgres psql
postgres=# SELECT * FROM pg_stat_wal_receiver;
-[ RECORD 1 ]---------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
pid | 229552
status | streaming
receive_start_lsn | 0/3000000
receive_start_tli | 1
written_lsn | 0/3000148
flushed_lsn | 0/3000148
received_tli | 1
last_msg_send_time | 2021-05-09 14:10:00.29382+00
last_msg_receipt_time | 2021-05-09 14:09:59.954983+00
latest_end_lsn | 0/3000148
latest_end_time | 2021-05-09 13:53:28.209279+00
slot_name | slaveslot1
sender_host | 10.10.10.11
sender_port | 5432
conninfo | user=replication password=******** channel_binding=prefer dbname=replication host=10.10.10.11 port=5432 fallback_application_name=walreceiver sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=prefer krbsrvname=postgres target_session_attrs=anyКакто виждате, трябва да се свърши много работа, за да настроим репликацията за PostgreSQL, въпреки че сме автоматизирали някои от задачите. Нека видим как това може да бъде постигнато с ClusterControl.
Разгръщане на PostgreSQL с помощта на ClusterControl GUI
Сега, когато знаем как да внедрим PostgreSQL с помощта на Ansible, нека видим как можем да разположим с помощта на ClusterControl. ClusterControl е софтуер за управление и автоматизация за клъстери от бази данни, включително MySQL, MariaDB, MongoDB, както и TimescaleDB. Той помага за внедряването, наблюдението, управлението и мащабирането на вашия клъстер от база данни. Има два начина за разгръщане на базата данни, в тази публикация в блога ще ви покажем как да я разгърнете с помощта на графичния потребителски интерфейс (GUI), като приемем, че вече имате инсталиран ClusterControl във вашата среда.
Първата стъпка е да влезете във вашия ClusterControl и да кликнете върху Разгръщане:
Ще ви бъде представена екранната снимка по-долу за следващата стъпка от внедряването , изберете раздела PostgreSQL, за да продължите:
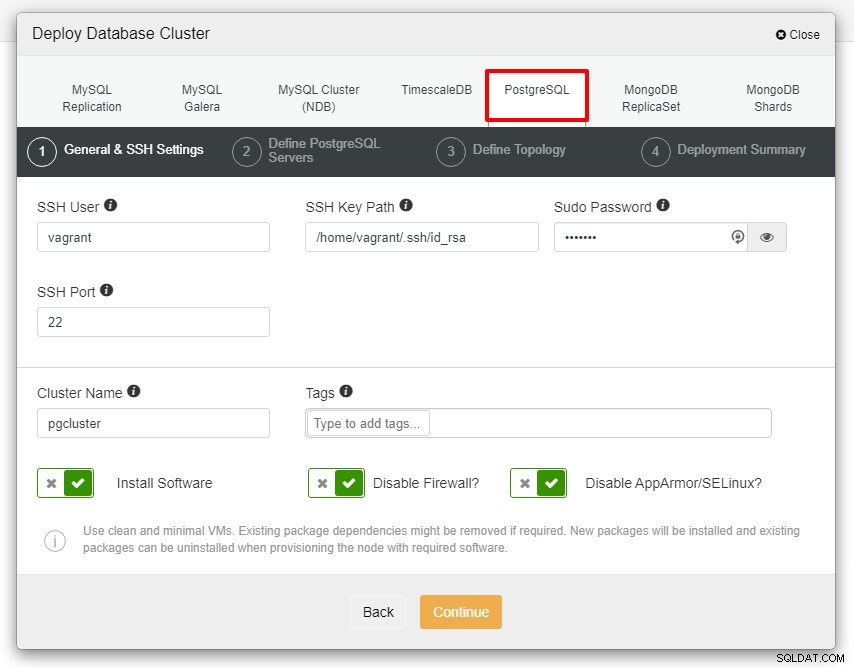
Преди да продължим по-нататък, бих искал да ви напомня, че връзката между възела ClusterControl и възлите на базата данни трябва да бъде без парола. Преди внедряването, всичко, което трябва да направим, е да генерираме ssh-keygen от възела ClusterControl и след това да го копираме във всички възли. Попълнете въвеждането за SSH потребител, парола Sudo, както и име на клъстер според вашето изискване и щракнете върху Продължи.
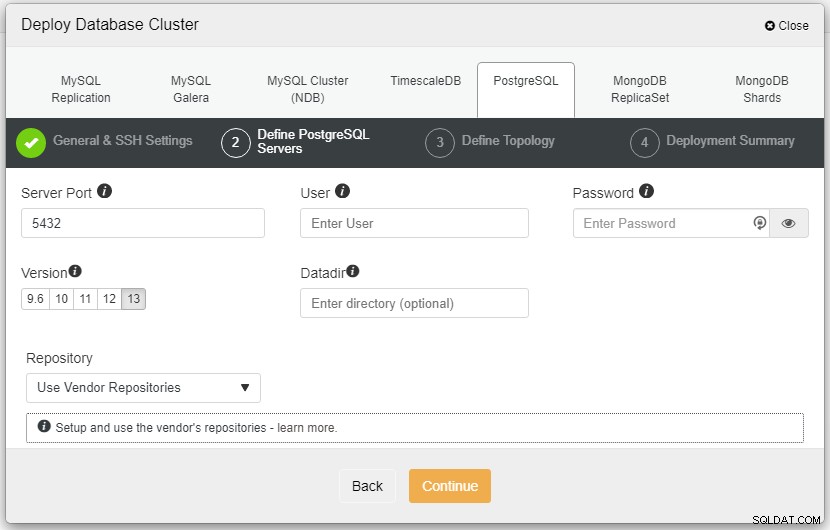
На екранната снимка по-горе ще трябва да дефинирате сървърния порт (в случай че искате да използвате други), потребителя, който искате, както и паролата и версията, която искате за инсталиране.
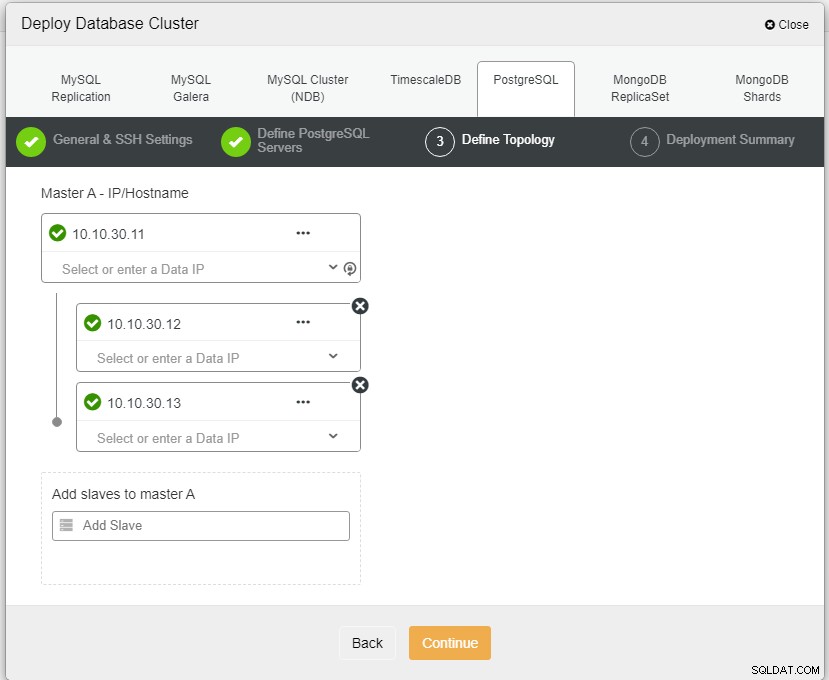
Тук трябва да дефинираме сървърите чрез името на хоста или IP адреса, като в този случай 1 главен и 2 подчинени. Последната стъпка е да изберете режима на репликация за нашия клъстер.
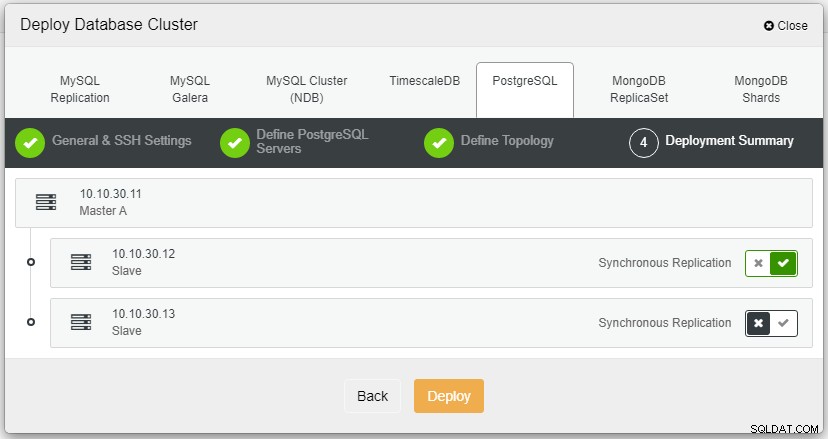
След като щракнете върху Разгръщане, процесът на внедряване ще започне и ние можем да наблюдаваме напредъка в раздела Активност.
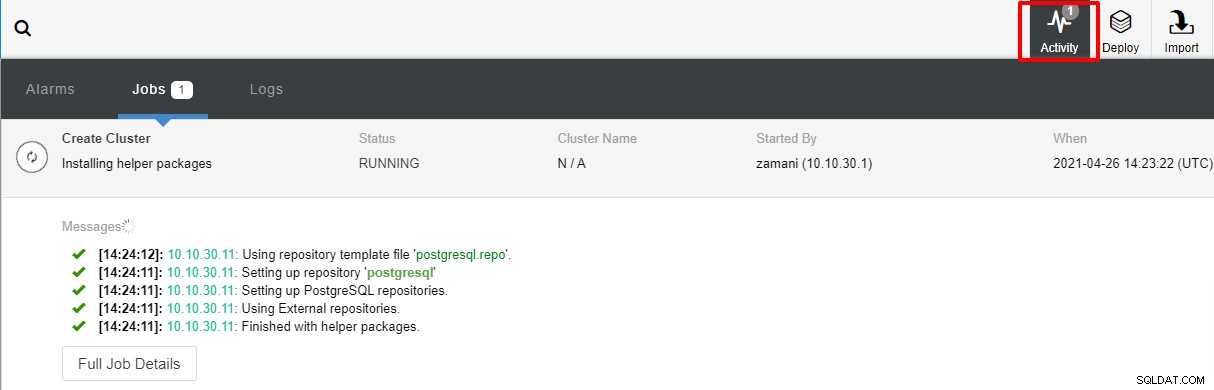
Разгръщането обикновено ще отнеме няколко минути, производителността зависи най-вече от мрежата и спецификацията на сървъра.

Сега, когато имаме инсталиран PostgreSQL с помощта на ClusterControl.
Разгръщане на PostgreSQL с помощта на ClusterControl CLI
Другият алтернативен начин за внедряване на PostgreSQL е използването на CLI. при условие че вече сме конфигурирали връзката без парола, можем просто да изпълним следната команда и да я оставим да завърши.
$ s9s cluster --create --cluster-type=postgresql --nodes="10.10.50.11?master;10.10.50.12?slave;10.10.50.13?slave" --provider-version=13 --db-admin="postgres" --db-admin-passwd="example@sqldat.com$$W0rd" --cluster-name=PGCluster --os-user=root --os-key-file=/root/.ssh/id_rsa --logТрябва да видите съобщението по-долу, след като процесът завърши успешно и можете да влезете в мрежата на ClusterControl, за да потвърдите:
...
Saving cluster configuration.
Directory is '/etc/cmon.d'.
Filename is 'cmon_1.cnf'.
Configuration written to 'cmon_1.cnf'.
Sending SIGHUP to the controller process.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Registering the cluster on the web UI.
Waiting until the initial cluster starts up.
Cluster 1 is running.
Generated & set RPC authentication token.Заключение
Както можете да видите, има няколко начина за внедряване на PostgreSQL. В тази публикация в блога научихме как да го разгърнем, като използваме Ansible и, както и нашия ClusterControl. И двата начина са лесни за следване и могат да бъдат постигнати с минимална крива на обучение. С ClusterControl настройката за репликация на поточно предаване може да бъде допълнена с HAProxy, VIP и PGBouncer, за да добавите преодоляване на връзката, виртуален IP и пул на връзки към настройката.
Обърнете внимание, че внедряването е само един от аспектите на средата на производствена база данни. Поддържането му и работещо, автоматизирането на отказите, възстановяването на повредени възли и други аспекти като наблюдение, предупреждение, архивиране са от съществено значение.
Надяваме се, че тази публикация в блога ще бъде полезна на някои от вас и ще даде идея как да автоматизирате внедряването на PostgreSQL.