Изминаха почти два месеца, откакто пуснахме SCUMM (Обединено управление и наблюдение на няколко клъстера). SCUMM използва Prometheus като основен метод за събиране на данни от времеви редове от експортери, работещи върху екземпляри на база данни и балансиращи натоварването. Този блог ще ви покаже как да отстраните проблеми, когато експортерите на Prometheus не работят, или ако графиките не показват данни или показват „Няма точки от данни“.
Какво е Прометей?
Prometheus е система за мониторинг с отворен код с модел на измерения на данните, гъвкав език за заявки, ефективна база данни от времеви серии и модерен подход за сигнализиране. Това е платформа за наблюдение, която събира метрики от наблюдавани цели, като изстъргва метрики на HTTP крайните точки на тези цели. Той предоставя данни за размерите, мощни заявки, страхотна визуализация, ефективно съхранение, лесна работа, прецизни сигнали, много клиентски библиотеки и много интеграции.
Prometheus в действие за табла за управление на SCUMM
Prometheus събира метрични данни от експортери, като всеки износител работи на база данни или хост за балансиране на натоварване. Диаграмата по-долу ви показва как тези експортери са свързани със сървъра, хостващ процеса Prometheus. Показва, че възелът ClusterControl има работещ Prometheus, където също изпълнява process_exporter и node_exporter.
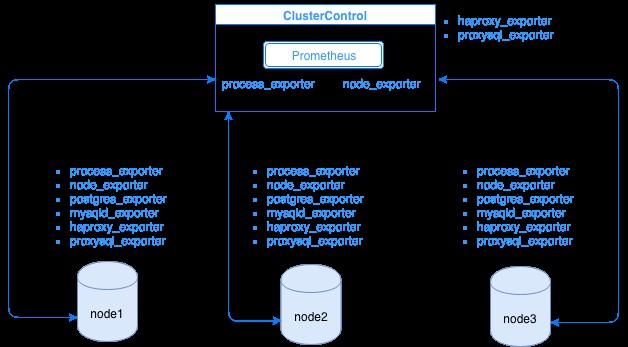
Диаграмата показва, че Prometheus работи на хоста ClusterControl и експортерите process_exporter и node_exporter също се изпълняват, за да събират показатели от собствения си възел. По желание можете да направите своя ClusterControl хост като цел, в която можете да настроите HAProxy или ProxySQL.
За възлите на клъстера по-горе (node1, node2 и node3) може да има работещ mysqld_exporter или postgres_exporter, които са агентите, които изстъргват данни вътрешно в този възел и ги предават на сървъра на Prometheus и ги съхраняват в собственото си хранилище на данни. Можете да намерите неговите физически данни чрез /var/lib/prometheus/data в хоста, където е настроен Prometheus.
Когато конфигурирате Prometheus, например, в хоста ClusterControl, той трябва да има отворени следните портове. Вижте по-долу:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusВъз основа на изхода, ProxySQL работи и на хоста testccnode, в който се хоства ClusterControl.
Чести проблеми с таблата за управление на SCUMM, използващи Prometheus
Когато таблата за управление са активирани, ClusterControl ще инсталира и разположи двоични файлове и експортери като node_exporter, process_exporter, mysqld_exporter, postgres_exporter и daemon. Това са общите набори от пакети към възлите на базата данни. Когато те са настроени и инсталирани, следните команди на демон се задействат и изпълняват, както се вижда по-долу:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusЗа възел на PostgreSQL,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterТой има същите експортери като за MySQL възел, но се различава само от postgres_exporter, тъй като това е възел на база данни PostgreSQL.
Въпреки това, когато възел страда от прекъсване на захранването, срив на системата или рестартиране на системата, тези експортери ще спрат да работят. Prometheus ще съобщи, че един износител не работи. ClusterControl взема проби от самия Prometheus и пита за статусите на експортера. Така той действа въз основа на тази информация и ще рестартира експортера, ако не работи.
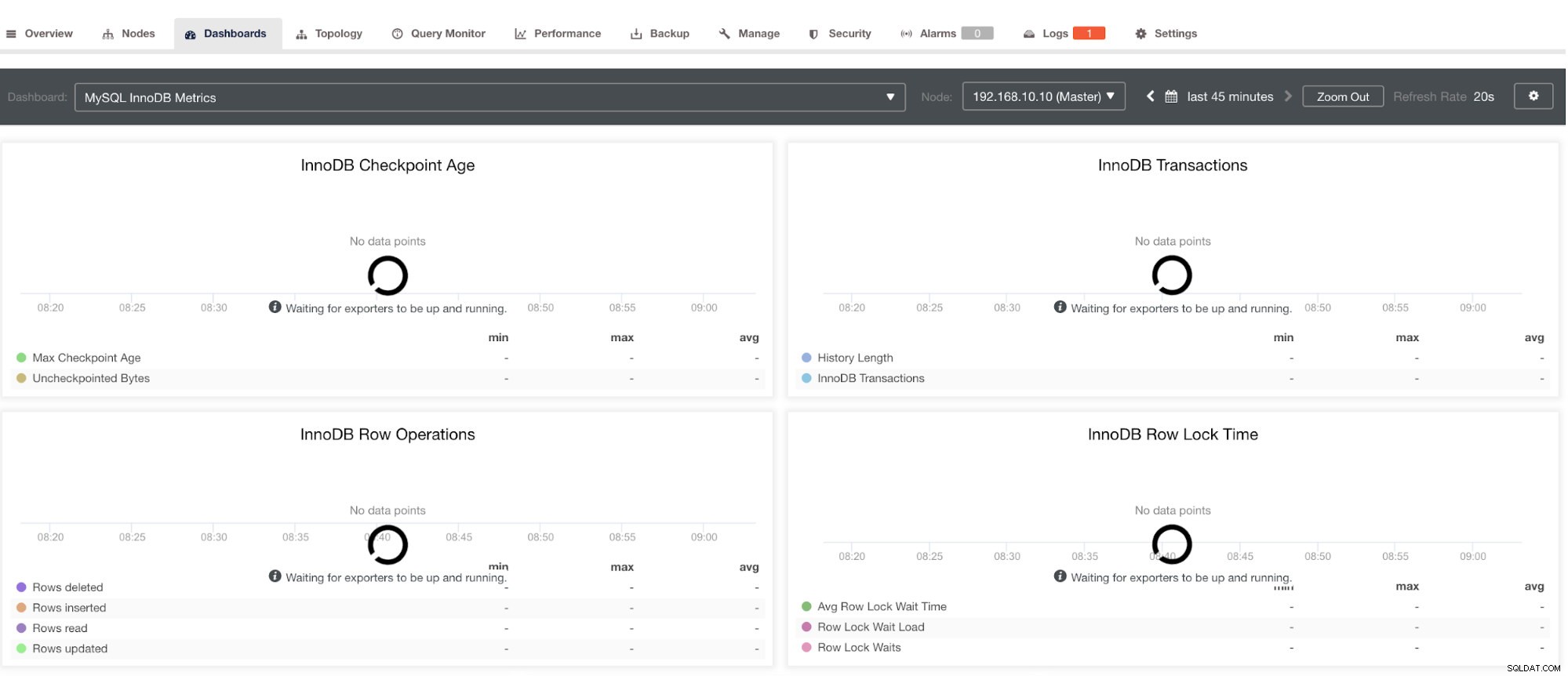
Имайте предвид обаче, че за експортери, които не са инсталирани чрез ClusterControl, те няма да бъдат рестартирани след срив. Причината е, че те не се наблюдават от systemd или демон, който действа като скрипт за безопасност, който би рестартирал процес при срив или необичайно изключване. Следователно екранната снимка по-долу ще покаже как изглежда, когато експортерите не работят. Вижте по-долу:
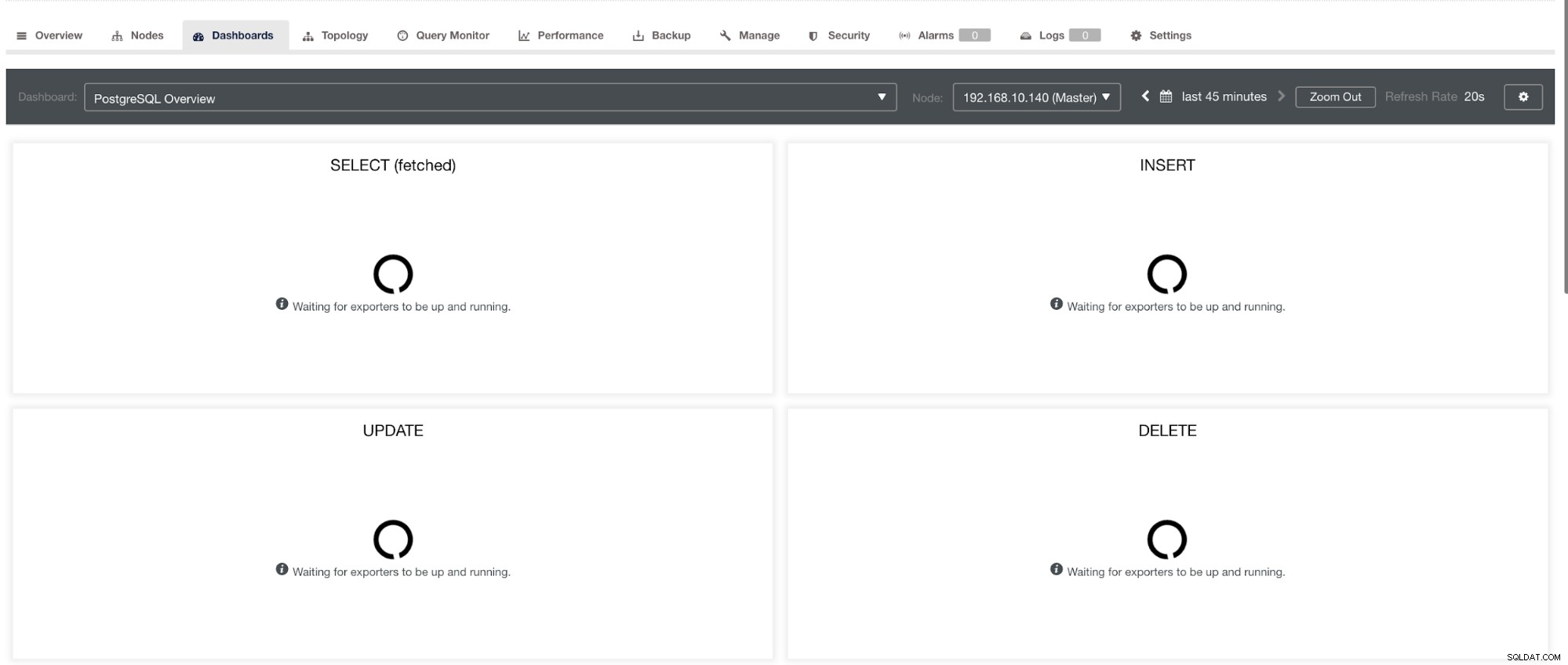
и в PostgreSQL Dashboard, ще има същата икона за зареждане с етикет „Няма точки от данни“ в графиката. Вижте по-долу:
Следователно те могат да бъдат отстранени чрез различни техники, които ще последват в следващите раздели.
Отстраняване на проблеми с Prometheus
Агентите на Prometheus, известни като експортери, използват следните портове:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter0) и собствения promethe90, който принадлежи на promethe. процес. Това са портовете за тези агенти, които се използват от ClusterControl.
За да започнете да отстранявате проблеми с таблото за управление на SCUMM, можете да започнете, като проверите отворените портове от възела на базата данни. Можете да следвате списъците по-долу:
-
Проверете дали портовете са отворени
напр.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporВъзможно е портовете да не са отворени поради защитна стена (като iptables или firewalld), която блокира отварянето на порта или самият процесен демон не работи.
-
Използвайте curl от монитора на хоста и проверете дали портът е достъпен и отворен.
напр.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0В идеалния случай на практика намерих този подход за осъществим за мен, тъй като мога лесно да grep и да отстранявам грешки от терминала.
-
Защо не използвате уеб потребителския интерфейс?
-
Prometheus разкрива порт 9090, който се използва от ClusterControl в нашите табла за управление на SCUMM. Освен това, портовете, които износителите излагат, могат да се използват и за отстраняване на неизправности и определяне на наличните имена на показатели с помощта на PromQL. В сървъра, където работи Prometheus, можете да посетите https://
:9090/targets . Екранната снимка по-долу го показва в действие: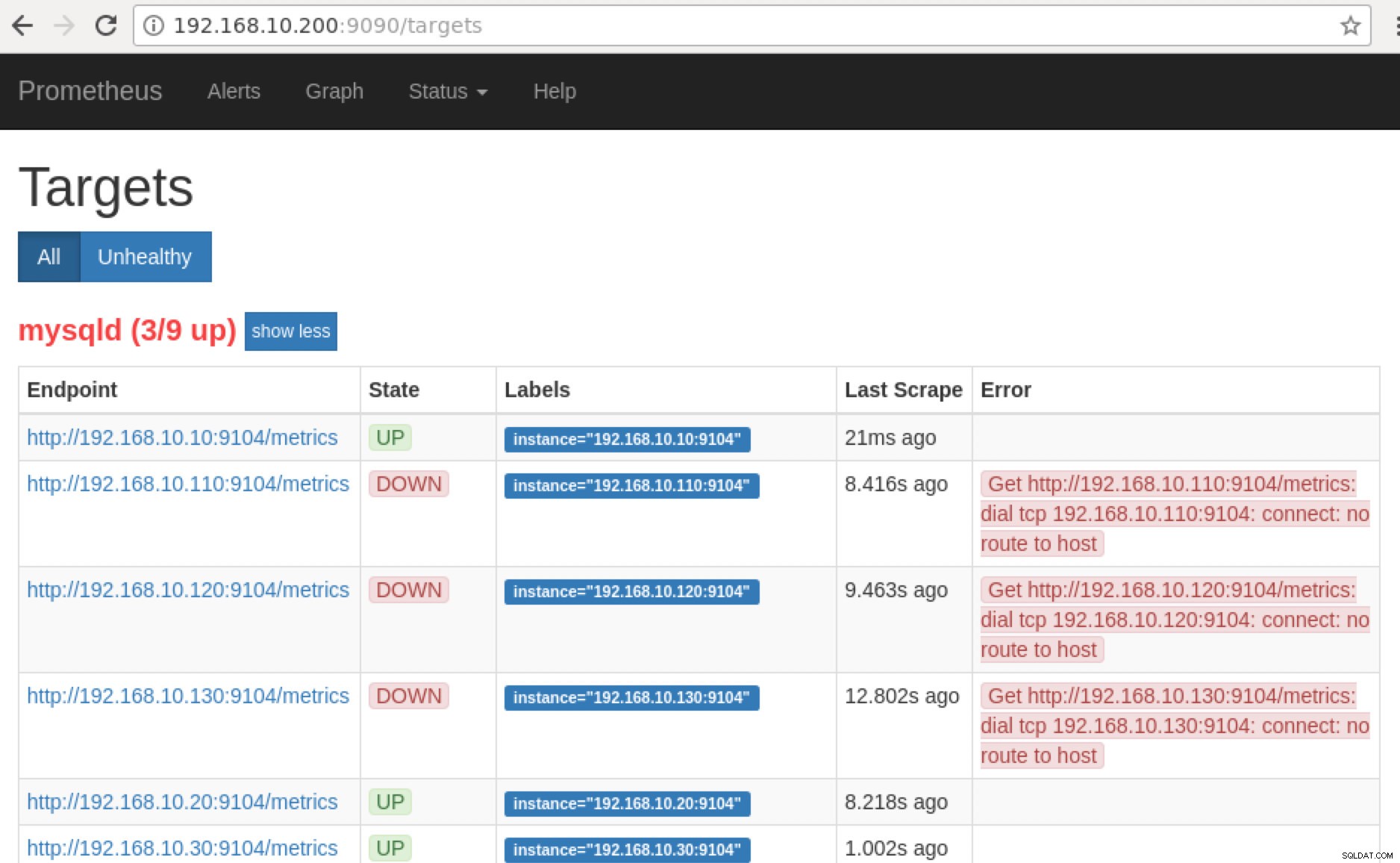
и като щракнете върху „Крайни точки“, можете да проверите показателите, както и на екранната снимка по-долу:
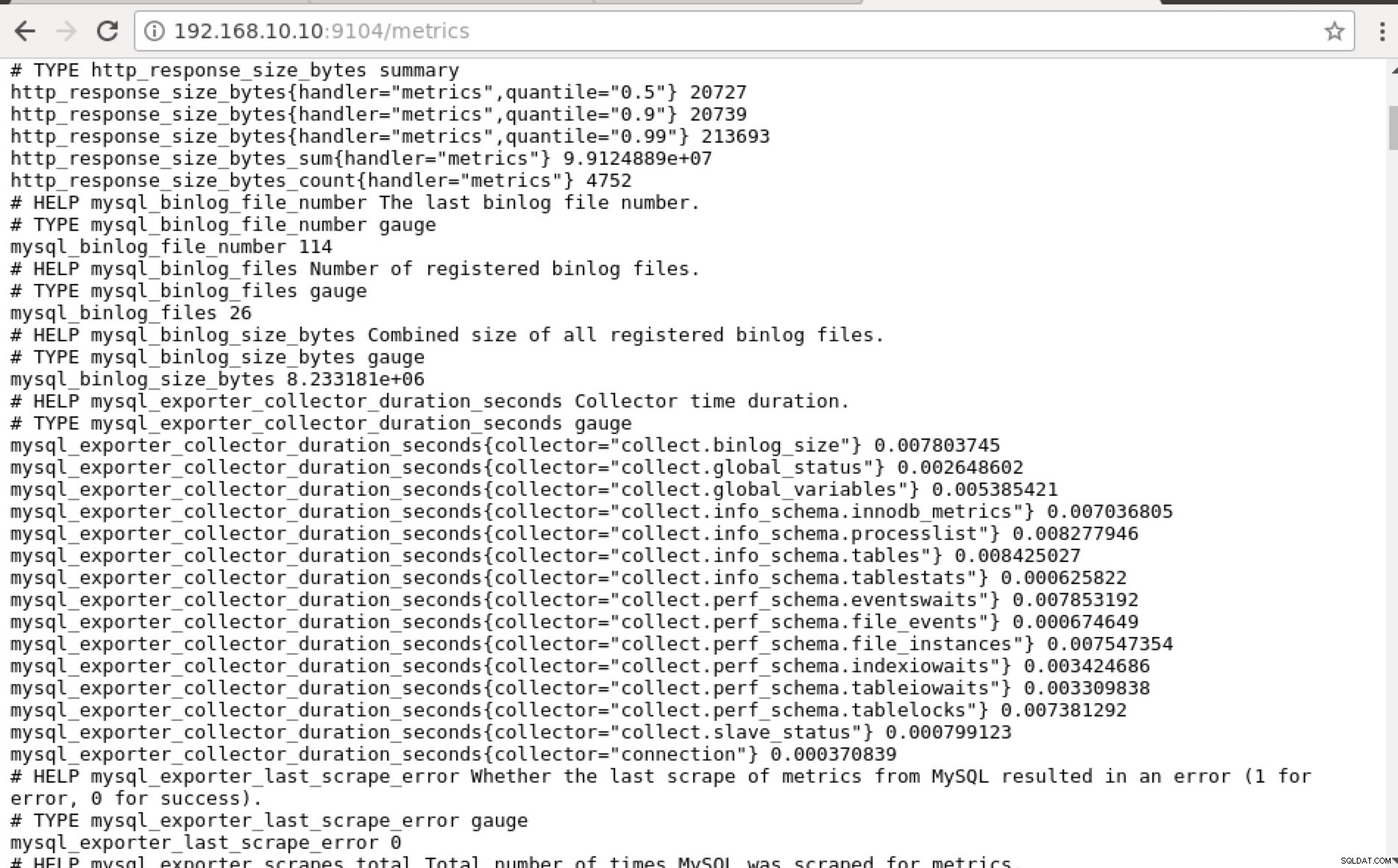
Вместо да използвате IP адреса, можете също да проверите това локално чрез localhost на този конкретен възел, като например посещение на https://localhost:9104/metrics или в уеб интерфейс на потребителския интерфейс, или чрез cURL.
Сега, ако се върнем към „Цели ” можете да видите списъка с възли, където може да има проблем с порта. Причините, които биха могли да причинят това, са изброени по-долу:
- Сървърът не работи
- Мрежата е недостъпна или портовете не са отворени поради работеща защитна стена
- Демонът не работи там, където
_exporter не работи. Например mysqld_exporter не работи.
-
Когато тези експортери работят, можете да стартирате и стартирате процеса с помощта на демона команда. Можете да се обърнете към наличните работещи процеси, които използвах в примера по-горе или споменати в предишния раздел на този блог.
Какво ще кажете за тези графики „Без точки от данни“ в моето табло?
SCUMM Dashboards предлагат общ сценарий за използване, който обикновено се използва от MySQL. Въпреки това, има някои променливи, когато извикването на такъв показател може да не е налично в конкретна версия на MySQL или доставчик на MySQL, като MariaDB или Percona Server.
Позволете ми да покажа пример по-долу:
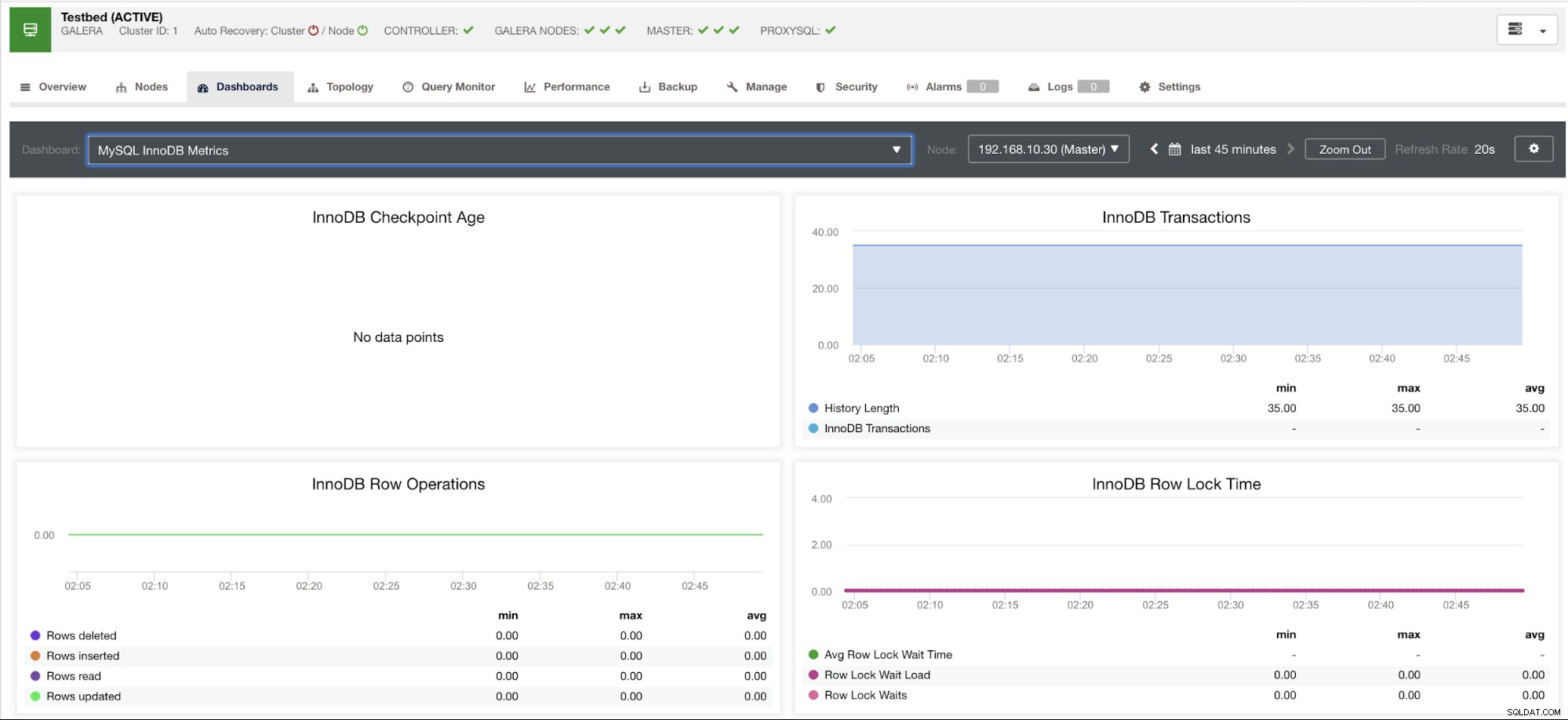
Тази графика е направена на сървър на база данни, работещ на версия 10.3.9-MariaDB-log MariaDB сървър с wsrep_patch_version на wsrep_25.23 екземпляр. Сега въпросът е защо няма зареждане на точки от данни? Е, докато запитах възела за статус на възраст на контролна точка, той разкрива, че е празен или не е намерена променлива. Вижте по-долу:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Нямам представа защо MariaDB няма тази променлива (моля, уведомете ни в секцията за коментари на този блог, ако имате отговора). Това е в контраст с Percona XtraDB Cluster Server, където променливата Innodb_checkpoint_max_age съществува. Вижте по-долу:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Какво означава това обаче е, че може да има графики, които нямат събрани точки от данни, тъй като няма данни, събрани за този конкретен показател, когато е била изпълнена заявка на Prometheus.
Въпреки това, графика, която няма точки от данни, не означава, че текущата ви версия на MySQL или нейния вариант не я поддържа. Например, има определени графики, които изискват определени променливи, които трябва да бъдат правилно настроени или активирани.
Следващият раздел ще покаже какви са тези графики.
Графика за изтласкване на състоянието на индекса (ICP)

Тази графика беше спомената в предишния ми блог. Той разчита на глобална променлива на MySQL с име innodb_monitor_enable. Тази променлива е динамична, така че можете да я зададете без твърдо рестартиране на вашата MySQL база данни. Също така изисква innodb_monitor_enable =module_icp или можете да зададете тази глобална променлива на innodb_monitor_enable =all. Обикновено, за да избегнете подобни случаи и обърквания защо такава графика не показва никакви точки от данни, може да се наложи да използвате всичко, но внимателно. Може да има определени допълнителни разходи, когато тази променлива е включена и е зададена на всички.
Графи на схемата за производителност на MySQL
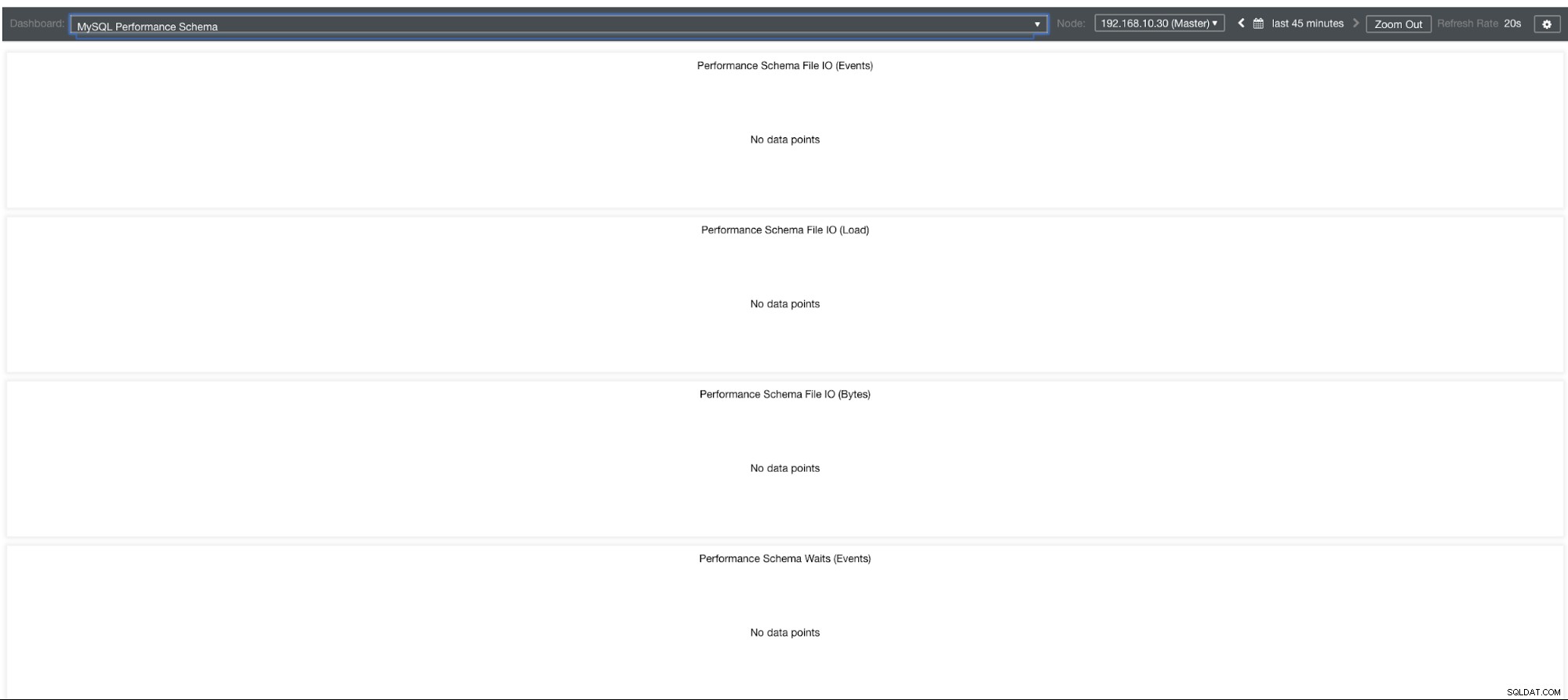
И така, защо тези графики показват „Няма точки от данни“? Когато създадете клъстер с помощта на ClusterControl с помощта на нашите шаблони, по подразбиране той ще дефинира променливи performance_schema. Например, тези променливи по-долу са зададени:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Ако обаче performance_schema =OFF, това е причината свързаните графики да показват „Няма точки от данни“.
Но имам активиран performance_schema, защо други графики все още са проблем?
Е, все още има графики, които изискват да бъдат зададени множество променливи. Това вече беше разгледано в предишния ни блог. По този начин трябва да зададете innodb_monitor_enable =all и userstat=1. Резултатът ще изглежда така:
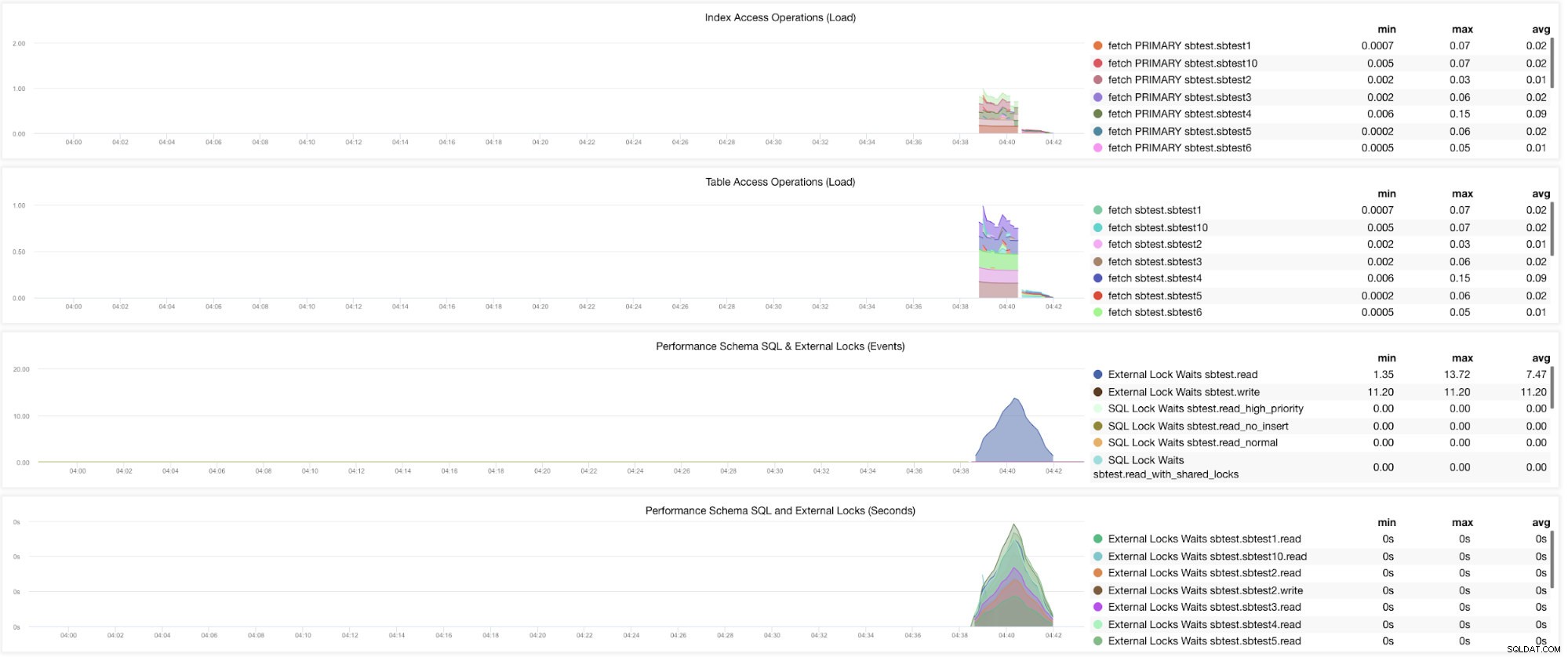
Забелязвам обаче, че във версията на MariaDB 10.3 (особено 10.3.11), настройката performance_schema=ON ще попълни метриките, необходими за таблото на MySQL Performance Schema Dashboard. Това е голямо предимство, защото не е необходимо да задава innodb_monitor_enable=ON, което би добавило допълнителни разходи за сървъра на базата данни.
Разширено отстраняване на неизправности
Има ли някакво предварително отстраняване на неизправности, което мога да препоръчам? Да, има! Въпреки това, имате нужда поне от някои умения за JavaScript. Тъй като SCUMM Dashboards, използващи Prometheus, разчитат на високи диаграми, начинът, по който показателите, които се използват за PromQL заявки, могат да бъдат определени чрез app.js скрипт, който е показан по-долу:
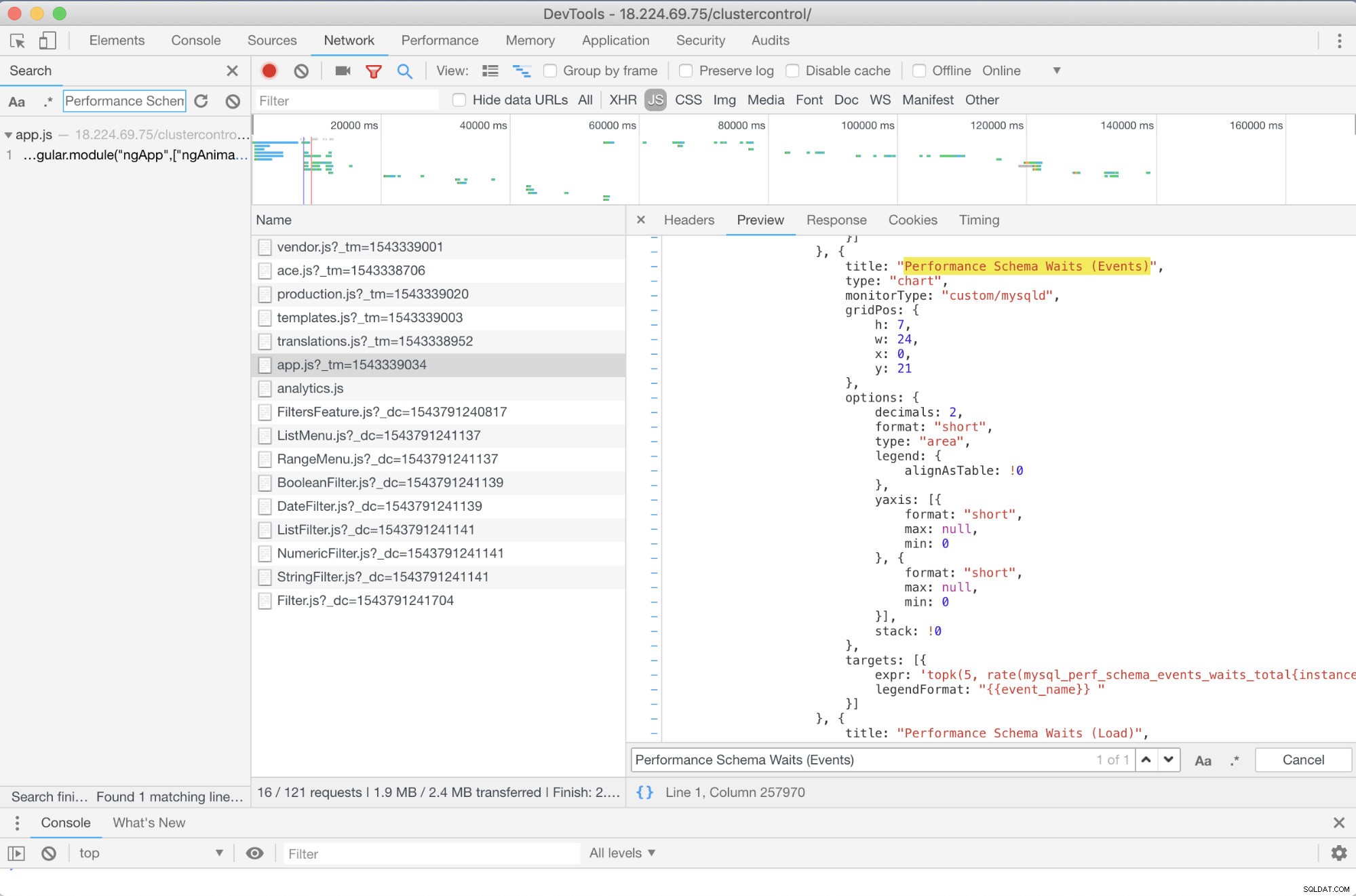
Така че в този случай използвам DevTools на Google Chrome и се опитах да потърся Изчакване на схемата за изпълнение (събития) . Как това може да помогне? Е, ако погледнете целите, ще видите:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Сега можете да използвате заявените показатели, които са mysql_perf_schema_events_waits_total. Можете да проверите това, например, като преминете през https://
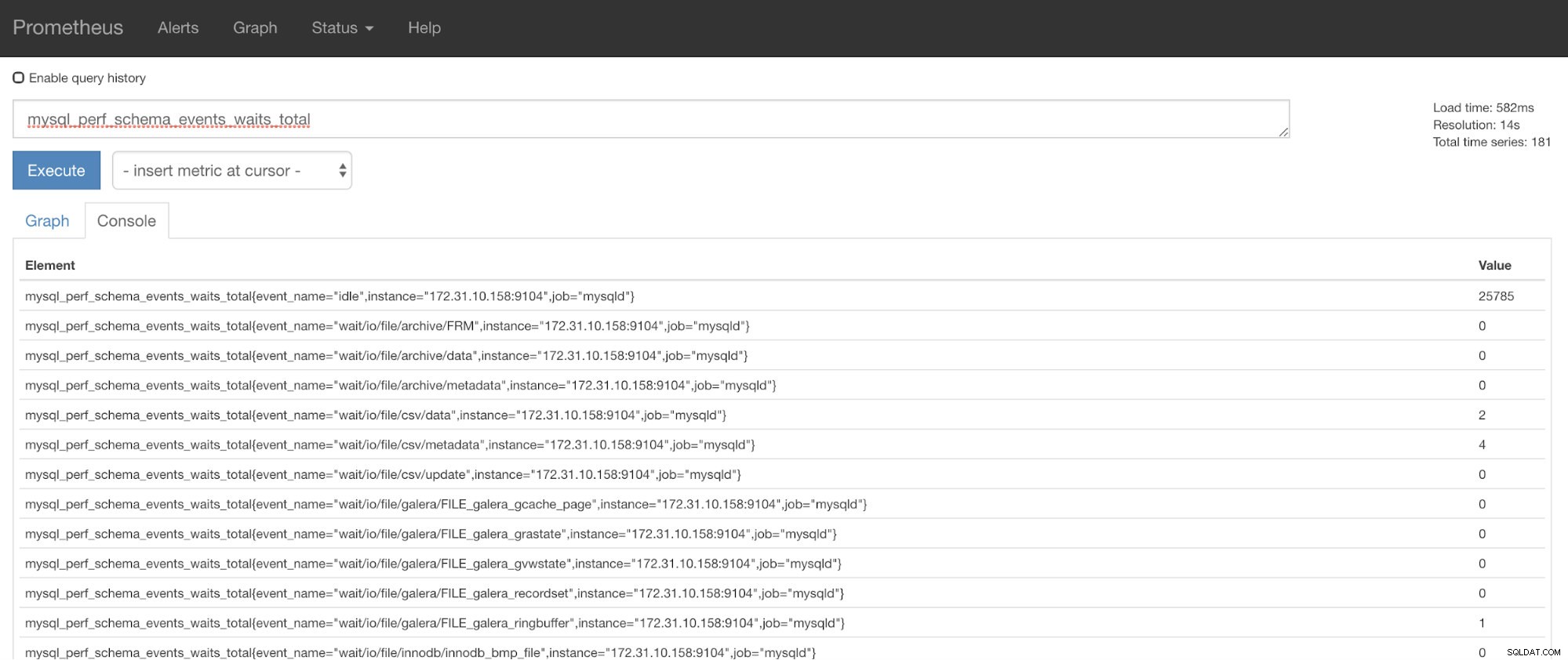
Автоматично възстановяване на ClusterControl на помощ!
И накрая, основният въпрос е, има ли лесен начин за рестартиране на неуспешни износители? Да! По-рано споменахме, че ClusterControl следи състоянието на експортираните и ги рестартира, ако е необходимо. В случай, че забележите, че таблата за управление на SCUMM не зареждат графиките нормално, уверете се, че сте активирали автоматичното възстановяване. Вижте изображението по-долу:

Когато това е активирано, това ще гарантира, че
Възможно е също така да преинсталирате или преконфигурирате експортерите.
Заключение
В този блог видяхме как ClusterControl използва Prometheus, за да предлага табла за управление на SCUMM. Той предоставя мощен набор от функции, от данни за мониторинг с висока разделителна способност и богати графики. Научихте, че с PromQL можете да определите и отстраните неизправности в нашите табла за управление на SCUMM, които ви позволяват да агрегирате данни от времеви серии в реално време. Можете също така да генерирате графики или да преглеждате през конзолата за всички събрани показатели.
Освен това научихте как да отстранявате грешки в нашите табла за управление на SCUMM, особено когато не се събират данни.
Ако имате въпроси, моля, добавете в коментарите си или ни уведомете чрез нашите форуми на общността.