Може да сте чували за термина „failover“ в контекста на MySQL репликация. Може би сте се чудили какво е, докато започвате своето приключение с бази данни. Може би знаете какво е, но не сте сигурни за потенциалните проблеми, свързани с него и как могат да бъдат решени?
В тази публикация в блога ще се опитаме да ви дадем въведение в обработката на отказ в MySQL и MariaDB.
Ще обсъдим какво представлява отказът, защо е неизбежен, каква е разликата между отказ и превключване. Ще обсъдим процеса на отказ в най-общата форма. Ще засегнем и различни въпроси, с които ще трябва да се справите във връзка с процеса на отказ.
Какво означава „отказ“?
MySQL репликацията е съвкупност от възли, всеки от тях може да изпълнява една роля в даден момент. Може да стане майстор или реплика. Има само един главен възел в даден момент. Този възел получава трафик за запис и репликира записите към своите реплики.
Както можете да си представите, като единична входна точка за данни в клъстера за репликация, главният възел е доста важен. Какво би се случило, ако се провали и стане недостъпен?
Това е доста сериозно условие за клъстер за репликация. Не може да приеме никакви записи в даден момент. Както може да очаквате, една от репликите ще трябва да поеме задачите на капитана и да започне да приема записи. Останалата част от топологията на репликация също може да се наложи да се промени - останалите реплики трябва да сменят своя главен възел от стария, неуспешен възел на новоизбрания. Този процес на „промотиране“ на реплика, за да стане главен, след като старият главен код се е провалил, се нарича „failover“.
От друга страна, „превключването“ се случва, когато потребителят задейства популяризирането на репликата. Нов главен елемент се повишава от реплика, посочена от потребителя, а старият главен елемент обикновено става реплика на новия главен.
Най-важната разлика между „отказ“ и „превключване“ е състоянието на стария главен. Когато се извърши отказ, старият главен по някакъв начин не е достъпен. Може да се е сринал, може да е претърпял мрежово разделяне. Не може да се използва в даден момент и състоянието му обикновено е неизвестно.
От друга страна, когато се извърши превключване, старият майстор е жив и здрав. Това има сериозни последици. Ако главен е недостъпен, това може да означава, че някои от данните все още не са изпратени на подчинените (освен ако не е използвана полусинхронна репликация). Някои от данните може да са повредени или изпратени частично.
Съществуват механизми за избягване на разпространението на подобни корупции върху роби, но въпросът е, че някои от данните могат да бъдат загубени в процеса. От друга страна, докато се извършва превключване, старият главен код е наличен и последователността на данните се поддържа.
Процес при отказ
Нека отделим малко време в обсъждане как точно изглежда процесът на отказ.
Открит е главният срив
Като за начало, главен трябва да се срине, преди да се извърши отказът. След като не е наличен, се задейства отказ. Засега изглежда просто, но истината е, че вече сме на хлъзгав терен.
На първо място, как се тества здравето на майстора? Тествано ли е от едно място или тестовете се разпространяват? Софтуерът за управление на отказ само се опитва ли да се свърже с главния или прилага по-разширени проверки, преди да бъде обявена грешка на главния?
Нека си представим следната топология:
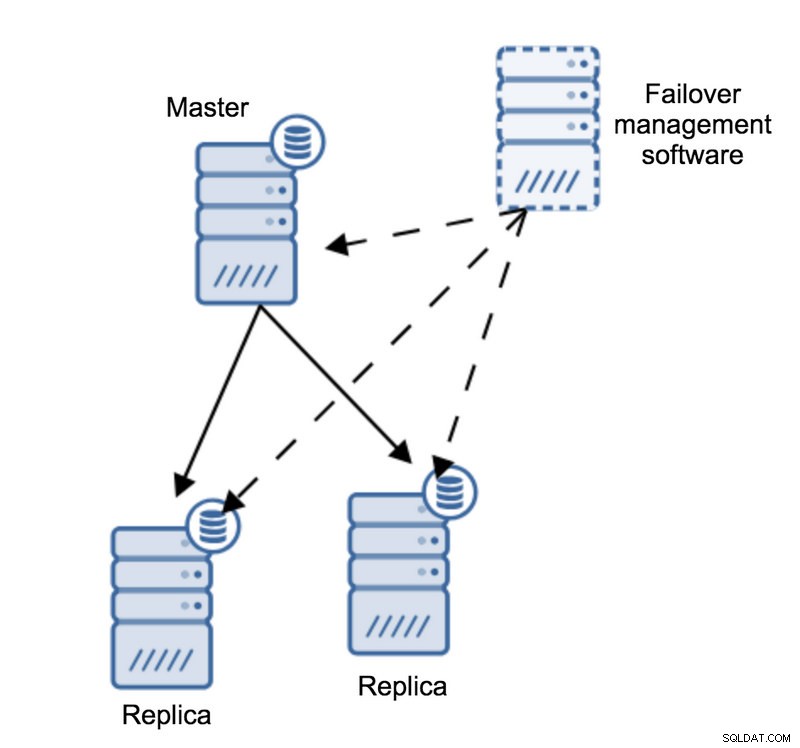
Имаме майстор и две реплики. Имаме и софтуер за управление на отказ, разположен на външен хост. Какво би се случило, ако мрежовата връзка между хоста със софтуер за преодоляване на отказ и главната се провали?
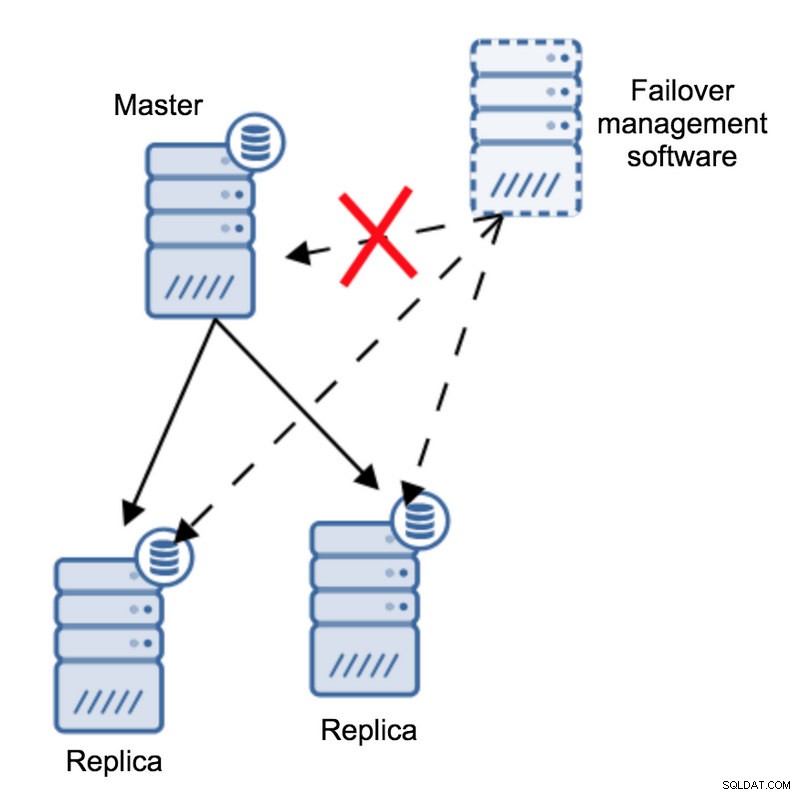
Според софтуера за управление на отказ, главният кадър се е сринал - няма връзка с него. Все пак самата репликация работи добре. Това, което трябва да се случи тук, е софтуерът за управление на отказ да се опита да се свърже с реплики и да види каква е тяхната гледна точка.
Оплакват ли се от счупена репликация или се възпроизвеждат с удоволствие?
Нещата може да станат още по-сложни. Ами ако добавим прокси (или набор от прокси сървъри)? Той ще се използва за маршрутизиране на трафика – записва към master и чете към реплики. Ами ако проксито не може да получи достъп до главния? Ами ако нито един от прокситата няма достъп до главния?
Това означава, че приложението не може да функционира при тези условия. Трябва ли да се задейства превключването (всъщност това би било по-скоро превключване, тъй като главният е технически жив)?
Технически капитана е жив, но не може да се използва от приложението. Тук трябва да влезе бизнес логиката и да се вземе решение.
Предотвратяване на Стария майстор да работи
Без значение как и защо, ако има решение да се повиши една от репликите, за да стане нов майстор, старият майстор трябва да бъде спрян и в идеалния случай не би трябвало да може да започне отново.
Как може да се постигне това зависи от детайлите на конкретната среда; следователно тази част от процеса на отказ обикновено се подсилва от външни скриптове, интегрирани в процеса на отказ чрез различни кукички.
Тези скриптове могат да бъдат проектирани да използват инструменти, налични в конкретната среда, за да спрат стария мастер. Това може да бъде CLI или API повикване, което ще спре виртуална машина; това може да бъде шел код, който изпълнява команди през някакво устройство за управление на светлините; може да е скрипт, който изпраща SNMP капани към блока за разпределение на захранването, който деактивира захранващите контакти, които използва старият главен (без електрическо захранване можем да сме сигурни, че няма да започне отново).
Ако софтуерът за управление на отказ е част от по-сложен продукт, който също обработва възстановяването на възли (както в случая с ClusterControl), старият главен код може да бъде маркиран като изключен от рутинните процедури за възстановяване.
Може да се чудите защо е толкова важно да попречите на стария господар да стане достъпен още веднъж?
Основният проблем е, че при настройките за репликация само един възел може да се използва за запис. Обикновено гарантирате това, като активирате променлива само за четене (и super_read_only, ако е приложимо) за всички реплики и я поддържате деактивирана само на главния.
След като нов главен елемент бъде повишен, той ще бъде деактивиран само за четене. Проблемът е, че ако старият master е недостъпен, не можем да го превключим обратно на read_only=1. Ако MySQL или хост се срине, това не е голям проблем, тъй като добрите практики са my.cnf да бъде конфигуриран с тази настройка, така че, след като MySQL стартира, той винаги стартира в режим само за четене.
Проблемът се показва, когато не е срив, а проблем с мрежата. Старият главен код все още работи с деактивиран read_only, просто не е наличен. Когато мрежите се сближат, ще се окажете с два възела за запис. Това може да е проблем или да не е. Някои от прокси сървърите използват настройката read_only като индикатор дали даден възел е главен или реплика. Показването на два главни устройства в дадения момент може да доведе до огромен проблем, тъй като данните се записват и на двата хоста, но репликите получават само половината от трафика за запис (частта, която е ударила новия главен файл).
Понякога става въпрос за твърдо кодирани настройки в някои от скриптовете, които са конфигурирани да се свързват само с даден хост. Обикновено те се провалят и някой ще забележи, че капитана се е променил.
Тъй като старият главен е наличен, те с радост ще се свържат с него и ще възникне несъответствие в данните. Както можете да видите, да се уверите, че старият главен код няма да стартира, е елемент с доста висок приоритет.
Вземете решение за магистърски кандидат
Старият господар е свален и няма да се върне от гроба си, сега е време да решим кой хост да използваме като нов господар. Обикновено има повече от една реплика, от която да избирате, така че трябва да се вземе решение. Има много причини, поради които една реплика може да бъде избрана пред друга, поради което трябва да се извършат проверки.
Бели и черни списъци
Като начало, екип, управляващ бази данни, може да има своите причини да избере една реплика пред друга, когато взема решение за главен кандидат. Може би използва по-слаб хардуер или има определена задача (тази реплика изпълнява архивиране, аналитични заявки, разработчиците имат достъп до нея и изпълняват персонализирани, ръчно направени заявки). Може би това е тестова реплика, при която нова версия преминава тестове за приемане, преди да продължи с надстройката. Повечето софтуери за управление на откази поддържат бели и черни списъци, които могат да се използват за точно определяне кои реплики трябва или не трябва да се използват като главни кандидати.
Полусинхронна репликация
Настройката за репликация може да бъде комбинация от асинхронни и полусинхронни реплики. Има огромна разлика между тях - полусинхронната реплика гарантирано съдържа всички събития от главния. Една асинхронна реплика може да не е получила всички данни, така че неуспехът към нея може да доведе до загуба на данни. Предпочитаме да видим полусинхронни реплики, които да бъдат популяризирани.
Закъснение при репликация
Въпреки че полусинхронната реплика ще съдържа всички събития, тези събития все още могат да се намират само в регистрационните файлове на релето. При натоварен трафик всички реплики, независимо дали са полусинхронни или асинхронни, може да изостават.
Проблемът с забавянето на репликацията е, че когато популяризирате реплика, трябва да нулирате настройките за репликация, така че тя да не се опитва да се свърже със стария главен файл. Това също така ще премахне всички релейни регистрационни файлове, дори ако все още не са приложени – което води до загуба на данни.
Дори и да не нулирате настройките за репликация, все още не можете да отворите нов главен файл за връзки, ако той не е приложил всички събития от своя регистър на релето. В противен случай ще рискувате новите заявки да повлияят на транзакциите от регистрационния файл на релето, задействайки всякакви проблеми (например, приложение може да премахне някои редове, до които се осъществява достъп от транзакции от регистрационния файл на релето).
Като се има предвид всичко това, единствената безопасна опция е да се изчака прилагането на регистрационния файл на релето. Все пак може да отнеме известно време, ако репликата изоставаше силно. Трябва да се вземат решения коя реплика би направила по-добър мастер – асинхронна, но с малко забавяне или полусинхронна, но със забавяне, което ще изисква значително време за прилагане.
Грешни транзакции
Въпреки че не трябва да се пишат реплики, все пак може да се случи някой (или нещо) да му е писал.
Може да е бил само един начин на транзакция в миналото, но все пак може да има сериозен ефект върху способността за извършване на отказ. Проблемът е строго свързан с Global Transaction ID (GTID), функция, която присвоява отделен идентификатор на всяка транзакция, изпълнена на даден MySQL възел.
В днешно време това е доста популярна настройка, тъй като носи големи нива на гъвкавост и позволява по-добра производителност (с многонишкови реплики).
Проблемът е, че докато се подчинява отново на нов главен, GTID репликацията изисква всички събития от този главен обект (които не са били изпълнени на реплика) да бъдат репликирани в репликата.
Нека разгледаме следния сценарий:в някакъв момент в миналото се случи запис на реплика. Беше много отдавна и това събитие беше изчистено от двоичните регистрационни файлове на репликата. В един момент капитана се е провалила и репликата е назначена като нов главен. Всички останали реплики ще бъдат подчинени на новия главен. Те ще попитат за транзакции, извършени на новия главен. Той ще отговори със списък с GTID, които идват от стария главен код и единичния GTID, свързан с това старо записване. GTID от стария главен код не представляват проблем, тъй като всички останали реплики съдържат поне по-голямата част от тях (ако не всички) и всички липсващи събития трябва да са достатъчно скорошни, за да бъдат налични в двоичните регистрационни файлове на новия главен файл.
В най-лошия случай някои липсващи събития ще бъдат прочетени от двоичните регистрационни файлове и ще бъдат прехвърлени в реплики. Проблемът е с това старо записване - това се случи само на нов главен файл, докато все още беше реплика, така че не съществува на останалите хостове. Това е старо събитие, така че няма начин да го извлечете от двоични регистрационни файлове. В резултат на това нито една от репликите няма да може да подчинява новия главен. Единственото решение тук е да предприемете ръчно действие и да инжектирате празно събитие с този проблемен GTID във всички реплики. Това също така ще означава, че в зависимост от случилото се репликите може да не са в синхрон с новия главен файл.
Както можете да видите, е доста важно да се проследяват грешните транзакции и да се определи дали е безопасно да се популяризира дадена реплика, за да стане нов главен. Ако съдържа грешни транзакции, може да не е най-добрият вариант.
Обработка при отказ за приложението
От решаващо значение е да се има предвид, че главният превключвател, принуден или не, има ефект върху цялата топология. Записванията трябва да бъдат пренасочени към нов възел. Това може да се направи по много начини и е изключително важно да се гарантира, че тази промяна е възможно най-прозрачна за приложението. В този раздел ще разгледаме някои от примерите за това как преминаването на отказ може да стане прозрачно за приложението.
DNS
Един от начините, по които приложение може да бъде насочено към главен, е чрез използване на DNS записи. С нисък TTL е възможно да промените IP адреса, към който сочи DNS запис като „master.dc1.example.com“. Такава промяна може да бъде извършена чрез външни скриптове, изпълнявани по време на процеса на отказ.
Откриване на услуга
Инструменти като Consul или etc.d също могат да се използват за насочване на трафика към правилното място. Такива инструменти може да съдържат информация, че IP адресът на текущия капитан е зададен на някаква стойност. Някои от тях също така дават възможност за използване на търсене на имена на хост, за да насочат към правилен IP. Отново, записите в инструментите за откриване на услуги трябва да се поддържат и един от начините да направите това е да направите тези промени по време на процеса на отказ, като се използват кукички, изпълнявани на различни етапи от отказ.
Прокси
Проксита могат също да се използват като източник на истина за топологията. Най-общо казано, без значение как откриват топологията (това може да бъде или автоматичен процес, или проксито трябва да бъде преконфигурирано, когато топологията се промени), те трябва да съдържат текущото състояние на веригата за репликация, тъй като в противен случай не биха могли да запитвания за маршрут правилно.
Подходът за използване на прокси като източник на истина може да бъде доста често срещан във връзка с подхода за колокиране на прокси сървъри на хостове на приложения. Има много предимства за колокиране на прокси и уеб сървъри:бърза и сигурна комуникация с помощта на Unix сокет, поддържане на кеширащ слой (тъй като някои от прокси сървърите, като ProxySQL също могат да извършват кеширане) близо до приложението. В такъв случай има смисъл приложението просто да се свърже с прокси сървъра и да приеме, че ще насочва заявките правилно.
Отказ при ClusterControl
ClusterControl прилага най-добрите практики в индустрията, за да се увери, че процесът на отказ се изпълнява правилно. Той също така гарантира, че процесът ще бъде безопасен - настройките по подразбиране са предназначени за прекратяване на отказ, ако бъдат открити възможни проблеми. Тези настройки могат да бъдат отменени от потребителя, ако иска да даде приоритет на преминаването при отказ пред безопасността на данните.
След като главната грешка бъде открита от ClusterControl, се инициира процес на отказ и незабавно се изпълнява първата кука за превключване при отказ:

След това се тества главната наличност.

ClusterControl прави обширни тестове, за да се увери, че главната програма наистина е недостъпна. Това поведение е активирано по подразбиране и се управлява от следната променлива:
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.Като следваща стъпка, ClusterControl гарантира, че старият главен файл не работи и ако не, ClusterControl няма да се опита да го възстанови:

Следващата стъпка е да се определи кой хост може да се използва като главен кандидат. ClusterControl проверява дали е дефиниран бял или черен списък.
Можете да направите това, като използвате следните променливи в конфигурационния файл на cmon:
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.Възможно е също така да конфигурирате ClusterControl да търси разлики в филтрите за двоични регистрационни файлове във всички реплики. Това може да се направи с помощта на променлива replication_check_binlog_filtration_bf_failover. По подразбиране тези проверки са деактивирани. ClusterControl също така потвърждава, че няма грешни транзакции, които могат да причинят проблеми.

Можете също така да помолите ClusterControl да възстановява автоматично реплики, които не могат да се репликират от новия главен файл, като използвате следната настройка в конфигурационния файл cmon:
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
След това се изпълнява втори скрипт:той се дефинира в настройката replication_pre_failover_script. След това кандидатът преминава през подготвителен процес.


ClusterControl изчаква прилагането на регистрационните файлове за повторно изпълнение (като се гарантира, че загубата на данни е минимална). Той също така проверява дали има други налични транзакции за останалите реплики, които не са били приложени към главен кандидат. И двете поведения могат да се контролират от потребителя, като се използват следните настройки в конфигурационния файл cmon:
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.Както можете да видите, можете да наложите принудително преминаване при отказ, въпреки че не са били приложени всички събития в регистъра за повторно изпълнение - това позволява на потребителя да реши кое има по-висок приоритет - последователност на данните или скорост на превключване при отказ.


Накрая се избира главният и се изпълнява последният скрипт (скрипт, който може да бъде дефиниран като replication_post_failover_script.
Ако все още не сте изпробвали ClusterControl, препоръчвам ви да го изтеглите (безплатно е) и да го опитате.
Основно откриване в ClusterControl
ClusterControl ви дава възможност да разгръщате пълен стек с висока достъпност, включително слоеве за база данни и прокси. Основното откриване винаги е един от проблемите, с които трябва да се справите.
Как работи в ClusterControl?
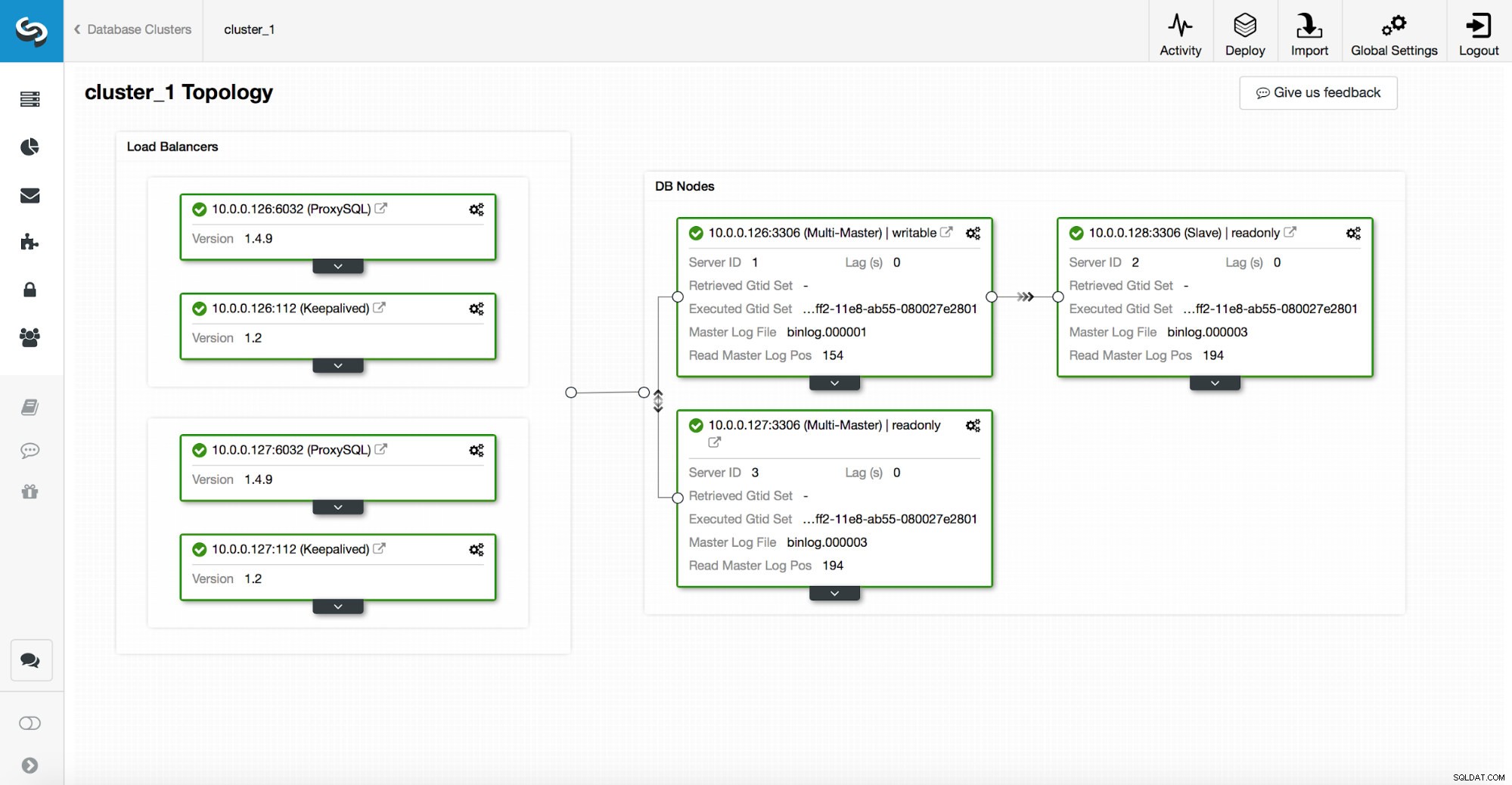
Стек с висока наличност, разгърнат чрез ClusterControl, се състои от три части:
- слой на базата данни
- прокси слой, който може да бъде HAProxy или ProxySQL
- поддържан слой, който с използването на виртуален IP, гарантира висока наличност на прокси слоя
Прокситата разчитат на променливи само за четене на възлите.
Както можете да видите на екранната снимка по-горе, само един възел в топологията е маркиран като „записващ“. Това е главният и това е единственият възел, който ще получава записи.
Прокси (в този пример ProxySQL) ще наблюдава тази променлива и тя ще се преконфигурира автоматично.
От другата страна на това уравнение ClusterControl се грижи за промените в топологията:откази и превключвания. Той ще направи необходимите промени в стойността read_only, за да отрази състоянието на топологията след промяната. Ако бъде повишен нов главен, той ще стане единственият възел за запис. Ако след преодоляването на отказ е избран главен, той ще бъде деактивиран само за четене.
Върху прокси слоя, keepalived се разполага. Той разгръща VIP и следи състоянието на основните прокси възли. VIP сочи към един прокси възел в даден момент. Ако този възел падне, виртуалният IP се пренасочва към друг възел, като се гарантира, че трафикът, насочен към VIP, ще достигне до здрав прокси възел.
За да обобщим, приложение се свързва с базата данни, използвайки виртуален IP адрес. Този IP сочи към един от прокси сървърите. Прокситата пренасочват трафика в съответствие със структурата на топологията. Информацията за топологията се извлича от състоянието само за четене. Тази променлива се управлява от ClusterControl и се задава въз основа на промените в топологията, поискани от потребителя, или ClusterControl, извършени автоматично.