Виртуалният IP адрес е IP адрес, който не съответства на действителен физически мрежов интерфейс. Той плава между множество мрежови интерфейси и само един активен интерфейс ще държи IP адреса за отказоустойчивост и мобилност. ClusterControl използва Keepalived, за да осигури интеграция на виртуален IP адрес с балансьори на натоварване на базата данни, за да елиминира всяка една точка на повреда (SPOF) на ниво балансиране на натоварването.
В тази публикация в блога ще ви покажем как ClusterControl конфигурира виртуален IP адрес и какво можете да очаквате, когато се случи отказ или възстановяване. Разбирането на това поведение е жизненоважно, за да се сведе до минимум всяко прекъсване на услугата и да се изглади операциите по поддръжка, които трябва да се извършват от време на време.
Изисквания
Има някои изисквания за стартиране на Keepalived във вашата мрежа:
- IP протокол 112 (Virtual Router Redundancy Protocol - VRRP) трябва да се поддържа в мрежата. Някои мрежи деактивират поддръжката за VRRP, особено комуникациите между VLAN. Моля, проверете това при мрежовия администратор.
- Ако използвате мултикаст, мрежата трябва да поддържа заявка за мултикаст (използвайте ip a | grep -i мултикаст). В противен случай можете да използвате unicast чрез unicast_src_ip и unicast_peer настроики. Използването на мултикаст е полезно, когато имате динамична среда като облачна среда или когато присвояването на IP се извършва чрез DHCP.
- Набор от VRRP екземпляри трябва да използва уникален virtual_router_id стойност, която не може да бъде споделена между други случаи. В противен случай ще видите фалшиви пакети и вероятно ще прекъснете превключвателя на главния архив.
- Ако работите в облачна среда като AWS, вероятно трябва да използвате външен скрипт (подсказка:използвайте опцията „извести“), за да отделите и свържете виртуалния IP адрес (Еластичен IP), така че да бъде разпознат и маршрутизиран от рутера.
Разгръщане на Keepalived
За да инсталирате Keepalived чрез ClusterControl, имате нужда от два или повече балансира на натоварване, инсталирани от или импортирани в ClusterControl. За производствена употреба силно препоръчваме софтуерът за балансиране на натоварването да се изпълнява на самостоятелен хост и да не се намира съвместно с възлите на вашата база данни.
След като имате поне два балансьора на натоварване, управлявани от ClusterControl, за да инсталирате Keepalived и активирате виртуален IP адрес, просто отидете на ClusterControl -> изберете клъстера -> Управление -> Load Balancer -> Keepalived:
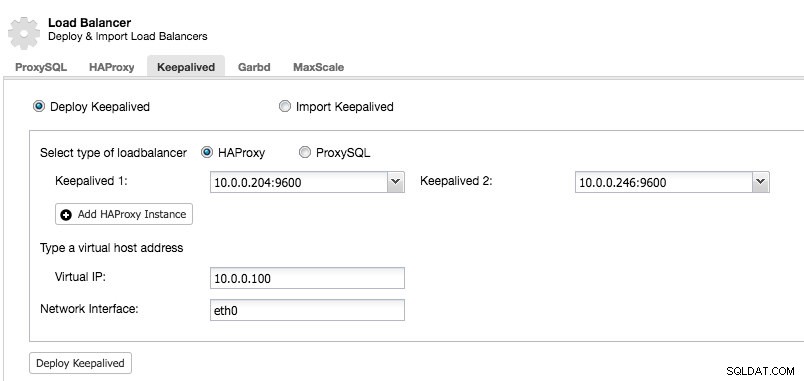
Повечето от полетата се обясняват сами. Можете да разположите нов набор от Keepalived или да импортирате съществуващи Keepalived екземпляри. Важните полета включват действителния виртуален IP адрес и мрежовия интерфейс, където ще съществува виртуалният IP адрес. Ако хостовете използват две различни имена на интерфейс, посочете името на интерфейса на хоста Keepalived 1, след което ръчно променете конфигурационния файл на Keepalived 2 с правилно име на интерфейса по-късно.
VRRP екземпляр
Към настоящия момент на писане, ClusterControl v1.5.1 инсталира Keepalived v1.3.5 (в зависимост от операционната система на хоста) и следното е конфигурирано за VRRP екземпляр:
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControl конфигурира VRRP инстанцията да комуникира чрез unicast. С unicast трябва да дефинираме всички еднопосочни партньори на другите Keepalived възли. Той е по-малко динамичен, но работи през повечето време. С мултикаст можете да премахнете тези линии (unicast_*) и да разчитате на IP адрес за мултикаст за откриване на хост и пиринг. По-лесно е, но обикновено се блокира от мрежовите администратори.
Следващата част е виртуалният IP адрес. Можете да посочите множество виртуални IP адреси за VRRP екземпляр, разделени с нов ред. Балансирането на натоварването в HAProxy/ProxySQL и Keepalived едновременно също изисква възможността за свързване към IP адрес, който не е локален, което означава, че не е присвоен на устройство в локалната система. Това позволява на работещ екземпляр за балансиране на натоварването да се свърже с IP, който не е локален за отказ. Така ClusterControl също така конфигурира net.ipv4.ip_nonlocal_bind=1 вътре в /etc/sysctl.conf.
Следващата директива е track_script , където можете да посочите скрипта за процеса на проверка на здравето, който е обяснен в следващия раздел.
Здравни прегледи
ClusterControl конфигурира Keepalived да извършва проверки на здравето, като проверява кода за грешка, върнат от track_script. В конфигурационния файл Keepalived, който по подразбиране се намира в /etc/keepalived/keepalived.conf, трябва да видите нещо подобно:
track_script {
chk_proxysql
}Където извиква chk_proxysql, който съдържа:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}Командата "killall -0" връща код за изход 0, ако има процес, наречен "proxysql", работещ на хоста. В противен случай екземплярът ще трябва да се понижи и да започне да инициира отказ, както е обяснено в следващия раздел. Обърнете внимание, че Keepalived също поддържа компоненти на Linux Virtual Server (LVS) за извършване на проверки на здравето, където също така може да балансира натоварването TCP/IP връзки, подобно на HAProxy, но това е извън обхвата на тази публикация в блога.
Симулиране на отказ
За VRRP компоненти, Keepalived използва VRRP протокол (IP протокол 112) за комуникация между VRRP екземпляри. По-високата стойност на приоритет на MASTER означава, че главният винаги ще има по-висока привилегия да държи виртуалния IP адрес, освен ако не конфигурирате екземпляра с "nopreempt". Нека използваме пример, за да обясним по-добре потока за превключване и връщане на отказ. Помислете за следната диаграма:
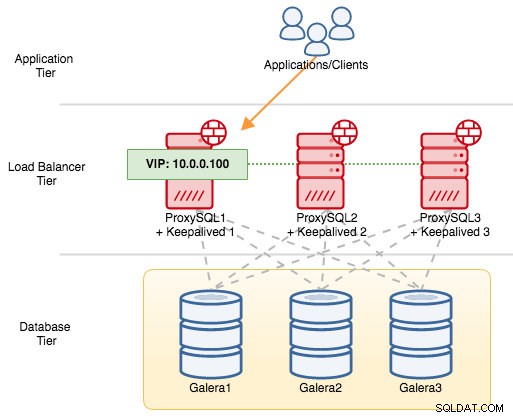
Има три екземпляра на ProxySQL пред три възела на MySQL Galera. Всеки ProxySQL хост е конфигуриран с Keepalived като MASTER със следния номер на приоритет:
- ProxySQL1 – приоритет 101
- ProxySQL2 – приоритет 100
- ProxySQL3 – приоритет 99
Когато Keepalived бъде стартиран като MASTER, той първо ще обяви приоритетния номер на членовете и след това ще се асоциира с виртуалния IP адрес. За разлика от екземпляра BACKUP, той ще наблюдава само рекламата и ще присвои виртуалния IP адрес само след като е потвърдил, че може да се издигне до MASTER.
Обърнете внимание, че ако убиете процеса "proxysql" или "haproxy" ръчно чрез командата kill, мениджърът на процесите на systemd по подразбиране ще се опита да възстанови процеса, който е бил спрян неуместно. Освен това, ако имате включено автоматично възстановяване на ClusterControl, ClusterControl винаги ще се опитва да стартира процеса, дори ако извършите чисто изключване чрез systemd (systemctl stop proxysql). За да симулира най-добре грешката, предлагаме на потребителя да изключи функцията за автоматично възстановяване на ClusterControl или просто да изключи ProxySQL сървъра, за да прекъсне комуникацията.
Ако изключим ProxySQL1, виртуалният IP адрес ще бъде прехвърлен към следващия хост, който има по-висок приоритет в този конкретен момент (който е ProxySQL2):
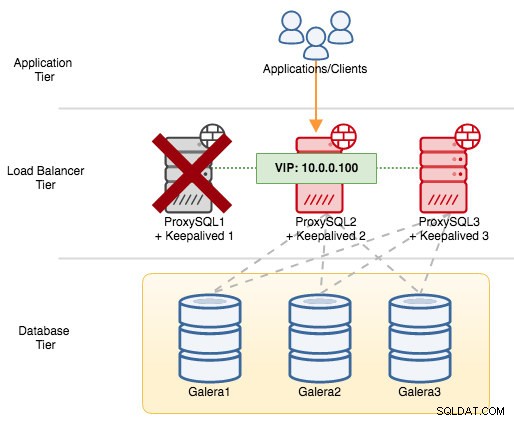
Ще видите следното в системния журнал на неуспешния възел:
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.Докато сте на вторичния възел, се случи следното:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.В този случай преминаването при отказ отне около 3 секунди, като максималното време за превключване ще бъде интервал + advert_int . Зад кулисите крайната точка на базата данни се промени и трафикът на базата данни се насочва през ProxySQL2, без приложенията да забелязват.
Когато ProxySQL1 се върне онлайн, той ще наложи нов избор на МАСТЕР и ще поеме IP адреса поради по-висок приоритет:
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.В същото време ProxySQL2 се понижава до състояние BACKUP и премахва виртуалния IP адрес от мрежовия интерфейс:
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.В този момент ProxySQL1 е отново онлайн и се превръща в активен балансьор на натоварване, който обслужва връзките от приложения и клиенти. VRRP обикновено изпреварва сървър с по-нисък приоритет, когато сървър с по-висок приоритет се появи онлайн. Ако искате да накарате IP адреса да остане на ProxySQL2, след като ProxySQL1 се върне онлайн, използвайте опцията "nopreempt". Това позволява на машината с по-нисък приоритет да поддържа главната роля, дори когато машина с по-висок приоритет се върне онлайн. Въпреки това, за да работи това, първоначалното състояние на този запис трябва да бъде BACKUP. В противен случай ще забележите следния ред:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERТъй като по подразбиране ClusterControl конфигурира всички възли като MASTER, трябва съответно да конфигурирате следната опция за конфигуриране за съответния VRRP екземпляр:
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}Рестартирайте процеса Keepalived, за да заредите тези промени. Виртуалният IP адрес ще бъде прехвърлен само към ProxySQL1 или ProxySQL3 (в зависимост от приоритета и кой възел е наличен в този момент), ако проверката на здравето е неуспешна на ProxySQL2. В много случаи стартирането на Keepalived на два хоста ще бъде достатъчно.