TeamCity е сървър за непрекъсната интеграция и непрекъсната доставка, изграден в Java. Предлага се като облачна услуга и на място. Както можете да си представите, инструментите за непрекъсната интеграция и доставка са от решаващо значение за разработването на софтуер и тяхната наличност трябва да бъде незасегната. За щастие TeamCity може да бъде разгърнат в режим с висока достъпност.
Тази публикация в блога ще обхване подготовката и внедряването на високодостъпна среда за TeamCity.
Околната среда
TeamCity се състои от няколко елемента. Има приложение на Java и база данни, която го архивира. Той също така използва агенти, които комуникират с основния екземпляр на TeamCity. Високодостъпното внедряване се състои от няколко екземпляра на TeamCity, където единият действа като основен, а другите втори. Тези екземпляри споделят достъп до една и съща база данни и директорията с данни. Полезна схема е налична на страницата с документация на TeamCity, както е показано по-долу:

Както виждаме, има два споделени елемента — директорията с данни и базата данни. Трябва да гарантираме, че те също са много достъпни. Има различни опции, които можете да използвате, за да създадете споделено монтиране; обаче ще използваме GlusterFS. Що се отнася до базата данни, ще използваме една от поддържаните системи за управление на релационни бази данни – PostgreSQL, и ще използваме ClusterControl, за да изградим стек с висока наличност, базиран на нея.
Как да конфигурирам GlusterFS
Нека започнем с основите. Искаме да конфигурираме имена на хостове и /etc/hosts на нашите възли на TeamCity, където също ще внедряваме GlusterFS. За да направим това, трябва да настроим хранилището за най-новите пакети на GlusterFS на всички тях:
sudo add-apt-repository ppa:gluster/glusterfs-7
sudo apt updateСлед това можем да инсталираме GlusterFS на всичките ни възли на TeamCity:
sudo apt install glusterfs-server
sudo systemctl enable glusterd.service
example@sqldat.com:~# sudo systemctl start glusterd.service
example@sqldat.com:~# sudo systemctl status glusterd.service
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/lib/systemd/system/glusterd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2022-02-21 11:42:35 UTC; 7s ago
Docs: man:glusterd(8)
Process: 48918 ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=0/SUCCESS)
Main PID: 48919 (glusterd)
Tasks: 9 (limit: 4616)
Memory: 4.8M
CGroup: /system.slice/glusterd.service
└─48919 /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
Feb 21 11:42:34 node1 systemd[1]: Starting GlusterFS, a clustered file-system server...
Feb 21 11:42:35 node1 systemd[1]: Started GlusterFS, a clustered file-system server.GlusterFS използва порт 24007 за свързване между възлите; трябва да се уверим, че е отворен и достъпен за всички възли.
След като свързаността е на място, можем да създадем GlusterFS клъстер, като стартираме от един възел:
example@sqldat.com:~# gluster peer probe node2
peer probe: success.
example@sqldat.com:~# gluster peer probe node3
peer probe: success.Сега можем да тестваме как изглежда състоянието:
example@sqldat.com:~# gluster peer status
Number of Peers: 2
Hostname: node2
Uuid: e0f6bc53-d47d-4db6-843b-9feea111a713
State: Peer in Cluster (Connected)
Hostname: node3
Uuid: c7d285d1-bcc8-477f-a3d7-7e56ff6bfd1a
State: Peer in Cluster (Connected)Изглежда, че всичко е наред и свързаността е на мястото си.
След това трябва да подготвим блоково устройство, което да се използва от GlusterFS. Това трябва да се изпълни на всички възли. Първо създайте дял:
example@sqldat.com:~# echo 'type=83' | sudo sfdisk /dev/sdb
Checking that no-one is using this disk right now ... OK
Disk /dev/sdb: 30 GiB, 32212254720 bytes, 62914560 sectors
Disk model: VBOX HARDDISK
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
>>> Created a new DOS disklabel with disk identifier 0xbcf862ff.
/dev/sdb1: Created a new partition 1 of type 'Linux' and of size 30 GiB.
/dev/sdb2: Done.
New situation:
Disklabel type: dos
Disk identifier: 0xbcf862ff
Device Boot Start End Sectors Size Id Type
/dev/sdb1 2048 62914559 62912512 30G 83 Linux
The partition table has been altered.
Calling ioctl() to re-read partition table.
Syncing disks.След това форматирайте този дял:
example@sqldat.com:~# mkfs.xfs -i size=512 /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=1966016 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=1, sparse=1, rmapbt=0
= reflink=1
data = bsize=4096 blocks=7864064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0, ftype=1
log =internal log bsize=4096 blocks=3839, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0Накрая, на всички възли трябва да създадем директория, която ще се използва за монтиране на дяла и редактиране на fstab, за да гарантираме, че ще бъде монтиран при стартиране:
example@sqldat.com:~# mkdir -p /data/brick1
echo '/dev/sdb1 /data/brick1 xfs defaults 1 2' >> /etc/fstabНека сега да проверим дали това работи:
example@sqldat.com:~# mount -a && mount | grep brick
/dev/sdb1 on /data/brick1 type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)Сега можем да използваме един от възлите, за да създадем и стартираме тома GlusterFS:
example@sqldat.com:~# sudo gluster volume create teamcity replica 3 node1:/data/brick1 node2:/data/brick1 node3:/data/brick1 force
volume create: teamcity: success: please start the volume to access data
example@sqldat.com:~# sudo gluster volume start teamcity
volume start: teamcity: successМоля, обърнете внимание, че използваме стойността на „3“ за броя на репликите. Това означава, че всеки том ще съществува в три копия. В нашия случай всяка тухла, всеки /dev/sdb1 том на всички възли ще съдържа всички данни.
След като томовете са стартирани, можем да проверим състоянието им:
example@sqldat.com:~# sudo gluster volume status
Status of volume: teamcity
Gluster process TCP Port RDMA Port Online Pid
------------------------------------------------------------------------------
Brick node1:/data/brick1 49152 0 Y 49139
Brick node2:/data/brick1 49152 0 Y 49001
Brick node3:/data/brick1 49152 0 Y 51733
Self-heal Daemon on localhost N/A N/A Y 49160
Self-heal Daemon on node2 N/A N/A Y 49022
Self-heal Daemon on node3 N/A N/A Y 51754
Task Status of Volume teamcity
------------------------------------------------------------------------------
There are no active volume tasksКакто виждате, всичко изглежда наред. Важното е, че GlusterFS избра порт 49152 за достъп до този том и трябва да гарантираме, че той е достъпен на всички възли, където ще го монтираме.
Следващата стъпка ще бъде да инсталирате клиентския пакет GlusterFS. За този пример се нуждаем от инсталиране на същите възли като сървъра GlusterFS:
example@sqldat.com:~# sudo apt install glusterfs-client
Reading package lists... Done
Building dependency tree
Reading state information... Done
glusterfs-client is already the newest version (7.9-ubuntu1~focal1).
glusterfs-client set to manually installed.
0 upgraded, 0 newly installed, 0 to remove and 0 not upgraded.След това трябва да създадем директория на всички възли, която да се използва като директория за споделени данни за TeamCity. Това трябва да се случи на всички възли:
example@sqldat.com:~# sudo mkdir /teamcity-storageНакрая, монтирайте тома GlusterFS на всички възли:
example@sqldat.com:~# sudo mount -t glusterfs node1:teamcity /teamcity-storage/
example@sqldat.com:~# df | grep teamcity
node1:teamcity 31440900 566768 30874132 2% /teamcity-storageТова завършва подготовката за споделено съхранение.
Създаване на високодостъпен PostgreSQL клъстер
След като настройката за споделено хранилище за TeamCity приключи, вече можем да изградим нашата високодостъпна инфраструктура на базата данни. TeamCity може да използва различни бази данни; обаче ще използваме PostgreSQL в този блог. Ще използваме ClusterControl за внедряване и след това за управление на средата на базата данни.
Ръководството на TeamCity за изграждане на внедряване с няколко възли е полезно, но изглежда пропуска високата наличност на всичко различно от TeamCity. Ръководството на TeamCity предлага NFS или SMB сървър за съхранение на данни, който сам по себе си няма излишък и ще се превърне в единична точка на отказ. Ние се справихме с това с помощта на GlusterFS. Те споменават споделена база данни, тъй като един възел на база данни очевидно не осигурява висока наличност. Трябва да изградим подходящ стек:

В нашия случай. той ще се състои от три възела на PostgreSQL, един основен и две реплики. Ще използваме HAProxy като балансьор на натоварването и ще използваме Keepalived за управление на виртуален IP, за да предоставим единна крайна точка, с която приложението да се свързва. ClusterControl ще се справя с неуспехите, като следи топологията на репликацията и извършва необходимото възстановяване, ако е необходимо, като рестартиране на неуспешни процеси или преминаване към една от репликите, ако основният възел се повреди.
За да започнем, ще разположим възлите на базата данни. Моля, имайте предвид, че ClusterControl изисква SSH свързаност от възела ClusterControl към всички възли, които управлява.

След това избираме потребител, който ще използваме за свързване към база данни, нейната парола и версията на PostgreSQL за внедряване:

След това ще дефинираме кои възли да използваме за разполагане на PostgreSQL :
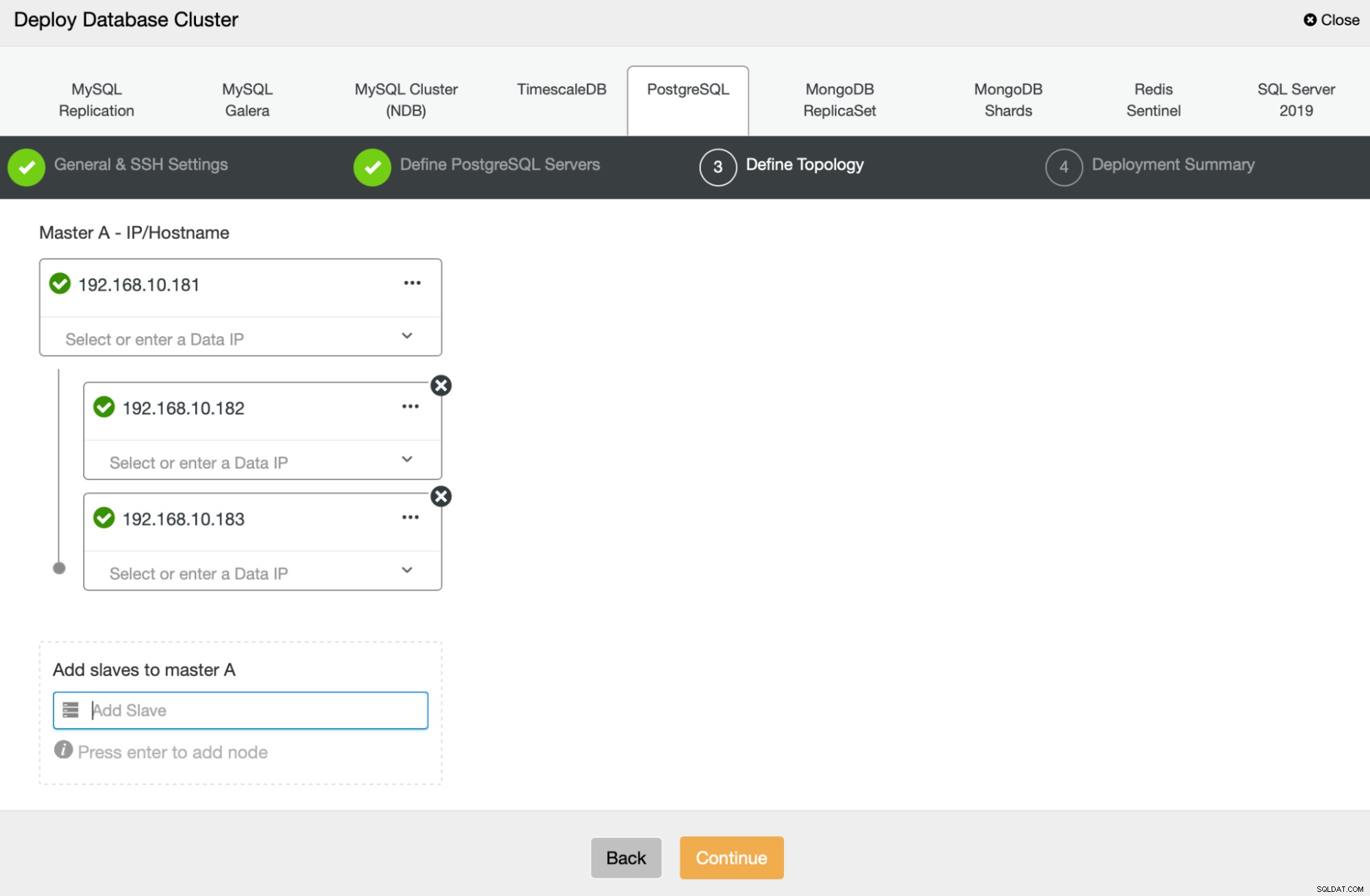
Накрая можем да дефинираме дали възлите трябва да използват асинхронна или синхронна репликация. Основната разлика между тези две е, че синхронната репликация гарантира, че всяка транзакция, изпълнена на основния възел, винаги ще бъде репликирана на репликата. Синхронната репликация обаче също забавя комита. Препоръчваме да активирате синхронна репликация за най-добра издръжливост, но трябва да проверите по-късно дали производителността е приемлива.

След като щракнем върху „Разгръщане“, ще започне работа по внедряване. Можем да наблюдаваме напредъка му в раздела Активност в потребителския интерфейс на ClusterControl. В крайна сметка трябва да видим че задачата е завършена и клъстерът е успешно разгърнат.

Разгръщане на HAProxy екземпляри, като отидете на Управление -> Балансиране на натоварване. Изберете HAProxy като балансьор на натоварването и попълнете формуляра. Най-важният избор е къде искате да разположите HAProxy. В този случай използвахме възел на базата данни, но в производствена среда най-вероятно ще искате да разделите балансьорите на натоварване от екземпляри на база данни. След това изберете кои PostgreSQL възли да включите в HAProxy. Ние искаме всички.

Сега ще започне внедряването на HAProxy. Искаме да го повторим поне още веднъж, за да създадем две екземпляра на HAProxy за резервиране. При това внедряване решихме да използваме три балансира на натоварването HAProxy. По-долу е екранна снимка на екрана с настройки, докато конфигурирате внедряването на втори HAProxy:
Когато всички наши HAProxy екземпляри са стартирани и работят, можем да внедрим Keepalived . Идеята тук е, че Keepalived ще бъде свързан с HAProxy и ще наблюдава процеса на HAProxy. Един от екземплярите с работещ HAProxy ще има присвоен виртуален IP. Този VIP трябва да се използва от приложението за свързване с базата данни. Keepalived ще открие дали този HAProxy стане недостъпен и ще премине към друг наличен HAProxy екземпляр.
Помощникът за внедряване изисква от нас да предаваме екземпляри на HAProxy, които искаме Keepalived да наблюдава. Трябва също да предадем IP адреса и мрежовия интерфейс за VIP.

Последната и последна стъпка ще бъде създаването на база данни за TeamCity:

С това приключихме внедряването на високодостъпния PostgreSQL клъстер.
Разгръщане на TeamCity като мулти-възел
Следващата стъпка е да разположите TeamCity в среда с множество възли. Ще използваме три възела на TeamCity. Първо, трябва да инсталираме Java JRE и JDK, които отговарят на изискванията на TeamCity.
apt install default-jre default-jdkСега на всички възли трябва да изтеглим TeamCity. Ще инсталираме в локална, а не споделена директория.
example@sqldat.com:~# cd /var/lib/teamcity-local/
example@sqldat.com:/var/lib/teamcity-local# wget https://download.jetbrains.com/teamcity/TeamCity-2021.2.3.tar.gzСлед това можем да стартираме TeamCity на един от възлите:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh start
Spawning TeamCity restarter in separate process
TeamCity restarter running with PID 83162
Starting TeamCity build agent...
Java executable is found: '/usr/lib/jvm/default-java/bin/java'
Starting TeamCity Build Agent Launcher...
Agent home directory is /var/lib/teamcity-local/TeamCity/buildAgent
Agent Launcher Java runtime version is 11
Lock file: /var/lib/teamcity-local/TeamCity/buildAgent/logs/buildAgent.properties.lock
Using no lock
Done [83731], see log at /var/lib/teamcity-local/TeamCity/buildAgent/logs/teamcity-agent.logСлед като TeamCity стартира, можем да получим достъп до потребителския интерфейс и да започнем внедряването. Първоначално трябва да предадем местоположението на директорията с данни. Това е споделеният том, който създадохме в GlusterFS.

След това изберете базата данни. Ще използваме PostgreSQL клъстер, който вече сме създали.

Изтеглете и инсталирайте JDBC драйвера:

След това попълнете данните за достъп. Ние ще използваме виртуалния IP предоставен от Keepalived. Моля, обърнете внимание, че използваме порт 5433. Това е портът, използван за бекенда за четене/запис на HAProxy; той винаги ще сочи към активния първичен възел. След това изберете потребител и база данни, които да използвате с TeamCity.

След като това стане, TeamCity ще започне да инициализира структурата на базата данни.

Съгласен съм с лицензионното споразумение:

Накрая създайте потребител за TeamCity:

Това е! Вече трябва да можем да видим графичния интерфейс на TeamCity:

Сега трябва да настроим TeamCity в режим на няколко възли. Първо, трябва да редактираме скриптовете за стартиране на всички възли:
example@sqldat.com:~# vim /var/lib/teamcity-local/TeamCity/bin/runAll.shТрябва да се уверим, че следните две променливи са експортирани. Моля, проверете дали използвате правилното име на хост, IP и правилните директории за локално и споделено хранилище:
export TEAMCITY_SERVER_OPTS="-Dteamcity.server.nodeId=node1 -Dteamcity.server.rootURL=https://192.168.10.221 -Dteamcity.data.path=/teamcity-storage -Dteamcity.node.data.path=/var/lib/teamcity-local"
export TEAMCITY_DATA_PATH="/teamcity-storage"След като това стане, можете да стартирате останалите възли:
example@sqldat.com:~# /var/lib/teamcity-local/TeamCity/bin/runAll.sh startТрябва да видите следния изход в Администриране -> Конфигурация на възли:Един основен възел и два възела в готовност.

Моля, имайте предвид, че преминаването при отказ в TeamCity не е автоматизирано. Ако главният възел спре да работи, трябва да се свържете с един от вторичните възли. За да направите това, отидете на „Конфигурация на възли“ и го повишете до „Основния“ възел. От екрана за вход ще видите ясна индикация, че това е вторичен възел:

В „Конфигурация на възли“ ще видите, че единият възел има изпуснат от клъстера:

Ще получите съобщение, че не можете да пишете на този възел. Не се притеснявайте; записът, който се изисква за повишаване на този възел до статус „основен“ ще работи добре:

Щракнете върху „Активиране“ и успешно популяризирахме вторичен възел на TimeCity:

Когато node1 стане достъпен и TeamCity се стартира отново на този възел, ние ще вижте как се присъединява отново към клъстера:

Ако искате да подобрите още повече производителността, можете да разположите HAProxy + Keepalived пред потребителския интерфейс на TeamCity, за да осигурите единна входна точка към GUI. Можете да намерите подробности за конфигурирането на HAProxy за TeamCity в документацията.
Приключване
Както можете да видите, разгръщането на TeamCity за висока наличност не е толкова трудно — повечето от него са разгледани подробно в документацията. Ако търсите начини да автоматизирате част от това и да добавите високодостъпен бекенд на база данни, помислете за оценка на ClusterControl безплатно за 30 дни. ClusterControl може бързо да разгръща и наблюдава бекенда, като осигурява автоматично преминаване при отказ, възстановяване, наблюдение, управление на архивиране и други.
За повече съвети относно инструменти за разработка на софтуер и най-добри практики, вижте как да подкрепите своя DevOps екип с техните нужди от база данни.
За да получите най-новите новини и най-добрите практики за управление на вашата инфраструктура на база данни с отворен код, не забравяйте да ни последвате в Twitter или LinkedIn и да се абонирате за нашия бюлетин. До скоро!