Филтрирането се свързва единствено с помощта на WHERE може да бъде изключително неефективно в някои често срещани сценарии. Например:
SELECT * FROM people p, companies c
WHERE p.companyID = c.id AND p.firstName = 'Daniel'
Повечето бази данни ще изпълнят тази заявка доста буквално, като първо приемат декартовия продукт
на people и companies таблици и след това филтриране по тези, които имат съвпадащ companyID и id полета. Въпреки че напълно неограниченият продукт не съществува никъде, освен в паметта и след това само за момент, изчисляването му отнема известно време.
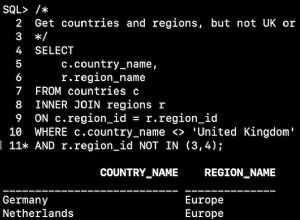
По-добър подход е да групирате ограниченията с JOIN когато е уместно. Това е не само субективно по-лесно за четене, но и много по-ефективно. По този начин:
SELECT * FROM people p JOIN companies c ON p.companyID = c.id
WHERE p.firstName = 'Daniel'
Това е малко по-дълго, но базата данни може да види ON клауза и я използвайте, за да изчислите напълно ограничения JOIN директно, вместо да започва с всичко и след това ограничаване. Това е по-бързо за изчисляване (особено при големи набори от данни и/или свързвания с много таблици) и изисква по-малко памет.
Променям всяка заявка, която виждам, която използва "запетая JOIN " синтаксис. Според мен единствената цел за съществуването му е сбитостта. Като се има предвид въздействието върху производителността, не мисля, че това е убедителна причина.