Ще започна с втория въпрос, който е по-лесен. Използване на dplyr пакет, можете да използвате top_n за да получите n-те най-големи реда за дадена колона. Например:
> top_n(p_ash_r_100a, 3, SMPL_CNT) %>% arrange(desc(SMPL_CNT))
# A tibble: 3 × 5
SMPL_TIME SQL_ID MODULE EVENT SMPL_CNT
<dttm> <chr> <chr> <chr> <int>
1 2017-04-11 09:01:00 NO_SQL GoldenGate CPU 7
2 2017-04-11 09:00:00 dgzp3at57cagd GoldenGate db file sequential read 2
3 2017-04-11 09:01:00 37cspa0acgqxp GoldenGate db file sequential read 2
Обърнете внимание, че ще получите повече от n реда, ако има равенства за n-то място. Така top_n(p_ash_r_100, 10, SMPL_CNT) ще върне целия примерен набор от данни поради 17-посочно равенство за 4-ти.
Що се отнася до първия въпрос, документацията за geom_area дава следа:
Това предполага, че geom_area очаква колоната, съпоставена с x, да бъде числова. Въз основа на списъка за p_ash_r_100 , SMPL_TIME изглежда като символен вектор. С lubridate пакет, можем да конвертираме SMPL_TIME към дата-час с dmy_hm :
p_ash_r_100a <- p_ash_r_100 %>%
mutate_at(vars(SMPL_TIME), dmy_hm)
Това обаче не е достатъчно, за да получите графиката, която искате, тъй като има множество стойности на y за всяка комбинация от x и fill (което е правилната естетика за geom_area , а не „col "). Трябва да обобщим данните, преди да начертаем:
p_ash_r_100a %>%
group_by(SMPL_TIME, EVENT) %>%
summarise(total = sum(SMPL_CNT)) %>%
ggplot(aes(SMPL_TIME, total, fill = EVENT)) +
geom_area()
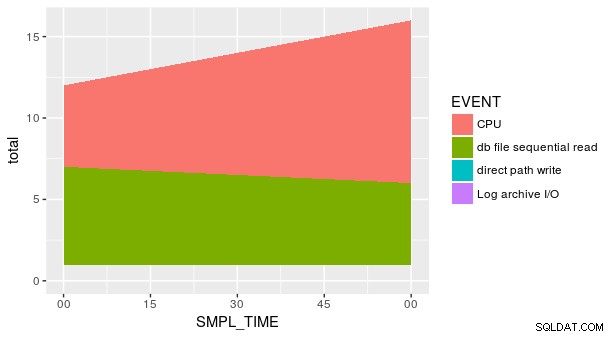
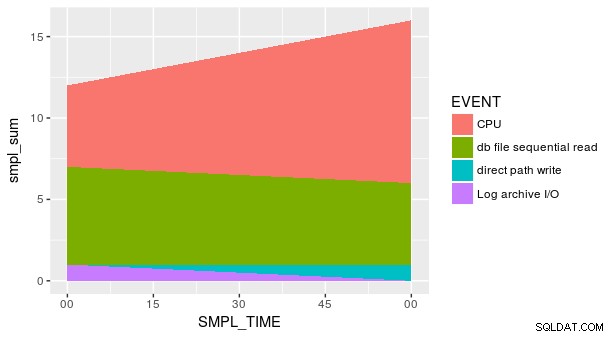
И все пак сюжетът все още не е правилен. Това е така, защото всяка комбинация от SMPL_TIME и EVENT не е представен в набора от данни. Трябва изрично да кажем geom_area че y е равно на нула за тези липсващи редове. Един от начините е да използвате удобния fill аргумент в tidyr::spread .
group_by(p_ash_r_100a, SMPL_TIME, EVENT) %>%
summarise(smpl_sum = sum(SMPL_CNT)) %>%
spread(EVENT, smpl_sum, fill = 0) %>%
gather(EVENT, smpl_sum, CPU, `db file sequential read`,
`direct path write`,
`Log archive I/O`) %>%
ggplot(aes(x = SMPL_TIME, y = smpl_sum, fill = EVENT)) +
geom_area()