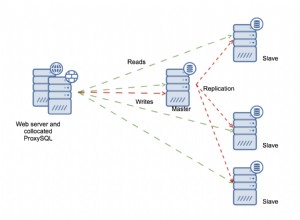
По принцип стратегията по подразбиране на Oracle за скорошни ojdbc буркани е да "предварително разпредели" масив на "предварително извличане" на ред, който се приспособява за възможно най-големия възможен размер за връщане от тази заявка. За всички редове. Така че в моя случай имах малко VARCHAR2(4000) там и 50 нишки (изявления) * 3 колони от varchar2 * 4000 добавяха повече от гигабайта RAM с setFetchSize от няколкостотин [yikes]. Изглежда, че няма опция да се каже „не разпределяйте предварително този масив, просто използвайте размера, когато идват“. Ojdbc дори поддържа тези предварително разпределени буфери около между подготвените изрази (кеширани/връзка), за да може да ги използва повторно. Определено грабвам паметта.
Едно решение:използвайте setFetchSize до някаква разумна сума. По подразбиране е 10, което може да бъде доста бавно при връзки с висока латентност. Профилирайте и използвайте само толкова високо от setFetchSize, колкото действително води до значителни подобрения на скоростта.
Друго решение е да се определи максималния действителен размер на колоната, след което да се замени заявката с (приемайки, че 50 е известният максимален действителен размер) select substr(column_name, 0, 50)
Други неща, които можете да направите:намалете броя на редовете за предварително извличане, увеличете java -Xmx изберете само колоните, от които наистина се нуждаете.
След като успяхме да използваме поне предварително извличане на 400 [уверете се, че профилирате, за да видите кои числа са подходящи за вас, с висока латентност видяхме подобрения до размер на предварително извличане 3-4K] за всички заявки, производителността се подобри драстично.
Предполагам, че ако искате да бъдете наистина агресивен срещу оскъдни „наистина дълги“ редове, може да можете да направите повторна заявка, когато попаднете на тези [редки] големи редове.
Подробности и гадене тук