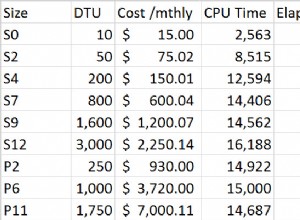
Това изглежда е недоразумение.
Вашият цитат от моя отговор е малко подвеждащ, тъй като се прилага само ако създадете и допълнителния частичен индекс, както е описано тук:
Как да добавите условен уникален индекс на PostgreSQL
Ако не добавите този втори индекс (както не сте го направили), вече имате своето решение , изглежда. Само с многоколонния уникален индекс можете да въведете (1, NULL) няколко пъти, но (1,2) или (1,3) само веднъж.
Празни низове
Ако по погрешка сте обмисляли празни низове ('' ) (за тип знаци
) вместо NULL стойности:те се обработват като всяка друга стойност. Вие можете справете се с тази ситуация, като използвате многоколонен, частично функционален уникален индекс (индексиране на израз
):
CREATE UNIQUE INDEX predictions _dim_tat_uni_idx
ON predictions (tat, NULLIF(dim, ''));
По този начин можете да въведете (1, 'a') , (1, 'b') само веднъж.
Но (1, NULL) и (1, '') няколко пъти.
Странични ефекти
Индексът пак ще поддържа напълно обикновени заявки в първата колона (tat ).
Но заявките и в двете колони ще трябва да съответстват на израза, за да се използва пълният потенциал. Това би било по-бързо, дори и да изглежда безсмислено:
SELECT * FROM predictions
WHERE tat = 1
AND NULLIF(dim, '') = 'foo';
.. от това:
SELECT * FROM predictions
WHERE tat = 1
AND dim = 'foo';
.. защото първата заявка може да използва и двете индексни колони. Резултатът ще бъде същият (освен при търсене на '' или NULL ). Подробности в този свързан отговор на dba.SE
.