lower()
/ upper()
Използвайте един от тях, за да сгънете знаците в малки или главни букви. Специалните символи не са засегнати:
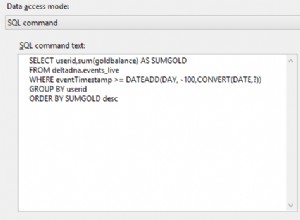
SELECT count(*), lower(name), number
FROM tbl
GROUP BY lower(name), number
HAVING count(*) > 1;
unaccent()
Ако наистина искате да игнорирате диакритичните знаци, както подсказват вашите коментари, инсталирайте допълнителния модул без ударение
, който предоставя речник за търсене на текст, който премахва ударенията, както и функцията с общо предназначение unaccent() :
CREATE EXTENSION unaccent;
Прави го много просто:
SELECT lower(unaccent('Büßercafé'));
Резултат:
busercafe
Това не премахва небукви. Добавете regexp_replace() като @Craig спомена за това:
SELECT lower(unaccent(regexp_replace('$s^o&f!t Büßercafé', '\W', '', 'g') ));
Резултат:
softbusercafe
Можете дори да създадете функционален индекс върху това: