Редактиране, 2016 г. — Защо не и двете?
Ако се интересувате от Postgres срещу Lucene, защо не и двете? Вижте ZomboDB разширение за Postgres, което интегрира Elasticsearch като първокласен тип индекс. Все още е доста ранен проект, но ми изглежда наистина обещаващ.
(Технически не се предлага на Heroku, но все пак си струва да се разгледа.)
Разкриване:Аз съм съосновател на Websolr и бонсаи Heroku добавки, така че моята гледна точка е малко предубедена към Lucene.
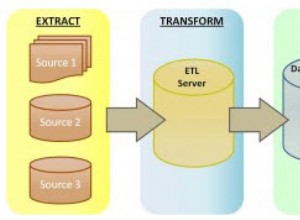
Моето четене за пълнотекстово търсене в Postgres е, че е доста стабилно за прости случаи на употреба, но има редица причини, поради които Lucene (и следователно Solr и ElasticSearch) превъзхожда както по отношение на производителност, така и на функционалност.
Като начало, jpountz предоставя наистина отличен технически отговор на въпроса, Защо Solr е толкова по-бърз от Postgres? Струва си да се прочетат няколко пъти, за да се усвои наистина.
Също така коментирах скорошен епизод на RailsCast сравняване на относителните предимства и недостатъци на търсенето в пълен текст на Postgres спрямо Solr. Нека повторя това тук:
Прагматични предимства на Postgres
- Използвайте повторно съществуваща услуга, която вече изпълнявате, вместо да настройвате и поддържате (или плащате за) нещо друго.
- Далеч превъзхожда фантастично бавния SQL
LIKEоператор. - По-малко проблеми при поддържане на данни в синхрон, тъй като всички те са в една и съща база данни — без интеграция на ниво приложение с API за външни услуги за данни.
Предимства пред Solr (или ElasticSearch)
От върха на главата ми, без определен ред...
- Мащабирайте натоварването си при индексиране и търсене отделно от редовното натоварване на базата данни.
- По-гъвкав анализ на термини за неща като нормализиране на акцента, лингвистичен корен, N-грами, премахване на маркиране… Други готини функции като проверка на правописа, извличане на „богато съдържание“ (напр. PDF и Word)…
- Solr/Lucene може да прави всичко в списък TODO за пълнотекстово търсене на Postgres добре.
- Много по-добро и по-бързо класиране по уместност на термина, ефективно адаптивно по време на търсене.
- Вероятно по-бързо търсене за общи термини или сложни заявки.
- Вероятно по-ефективно индексиране от Postgres.
- По-добра толерантност към промяна във вашия модел на данни чрез отделяне на индексирането от основното ви хранилище на данни
Очевидно смятам, че специална търсачка, базирана на Lucene, е по-добрият вариант тук. По принцип можете да мислите за Lucene като де факто хранилище с отворен код на опит в търсенето.
Но ако единствената ви друга опция е LIKE оператор, тогава търсенето в пълен текст на Postgres е определено предимство.