Въведение
Наскоро се сблъскахме с интересен проблем с производителността на една от нашите бази данни на SQL Server, които обработват транзакции със сериозна скорост. Таблицата на транзакциите, използвана за улавяне на тези транзакции, се превърна в гореща таблица. В резултат на това проблемът се появи в слоя на приложението. Беше периодично изчакване на сесията за публикуване на транзакции.
Това се случи, защото сесията обикновено „задържа“ таблицата и причинява поредица от фалшиви заключвания в базата данни.
Първата реакция на типичния администратор на база данни би била да идентифицира основната блокираща сесия и да я прекрати безопасно. Това беше безопасно, защото обикновено беше оператор SELECT или неактивна сесия.
Имаше и други опити за решаване на проблема:
- Прочистване на масата. Очакваше се това да осигури добра производителност, дори ако заявката трябваше да сканира цяла таблица.
- Активиране на нивото на изолация READ COMMITTED SNAPSHOT, за да се намали въздействието от блокирането на сесиите.
В тази статия ще се опитаме да пресъздадем опростена версия на сценария и да я използваме, за да покажем как простото индексиране може да адресира ситуации като тази, когато е направено правилно.
Две свързани таблици
Разгледайте Списък 1 и Списък 2. Те показват опростените версии на таблици, включени в разглеждания сценарий.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Списък 3 показва тригер, който вмъква четири реда в TranDetails таблица за всеки ред, вмъкнат в TranLog таблица.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Заявка за присъединяване
Типично е да намерите таблици за транзакции, поддържани от големи таблици. Целта е да се съхраняват много по-стари транзакции или да се съхраняват детайлите на записите, обобщени в първата таблица. Мислете за това като заповеди и подробности за поръчката таблици, които са типични в примерните бази данни на SQL Server. В нашия случай разглеждаме TranLog и TranDetails таблици.
При нормални обстоятелства транзакциите попълват тези две таблици с течение на времето. По отношение на отчитането или простите заявки, заявката ще извърши обединяване на тези две таблици. Това присъединяване ще се възползва от обща колона между таблиците.
Първо, попълваме таблицата с помощта на заявката в листинг 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
В нашата извадка общата колона, използвана от присъединяването, е TranID колона:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
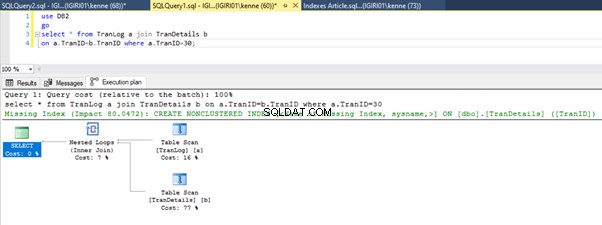
Можете да видите двете прости примерни заявки, които използват присъединяване за извличане на записи от TranLog и TranDetails .
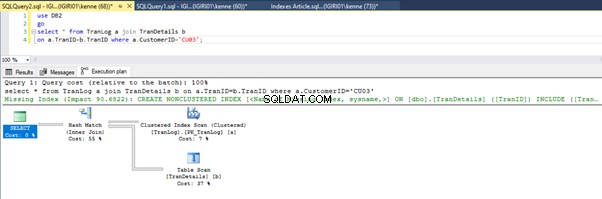
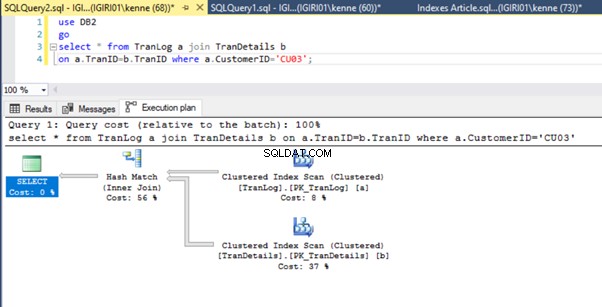
Когато изпълняваме заявките в листинг 5, и в двата случая трябва да направим пълно сканиране на таблицата и на двете таблици (вижте фигури 1 и 2). Доминиращата част от всяка заявка са физическите операции. И двете са вътрешни съединения. Списък 5a обаче използва Съвпадение на хеш join, докато листинг 5b използва вложен цикъл присъединяване. Забележка:Списък 5a връща 4000 реда, докато листинг 4b връща 4 реда.
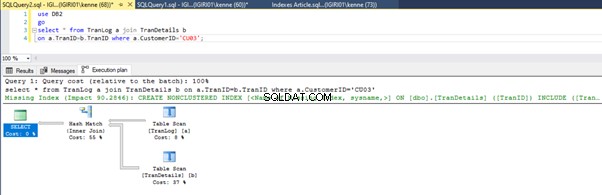
Три стъпки за настройка на производителността
Първата оптимизация, която правим, е въвеждането на индекс (първичен ключ, за да бъдем точни) в TranID колона на TranLog таблица:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
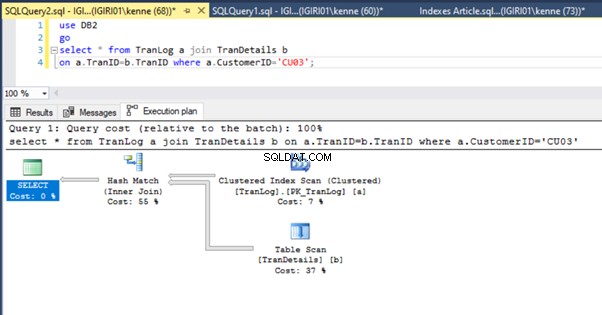
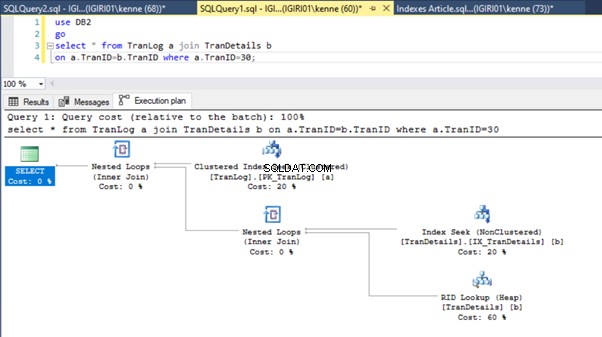
Фигури 3 и 4 показват, че SQL Server използва този индекс и в двете заявки, като прави сканиране в листинг 5a и търсене в листинг 5b.
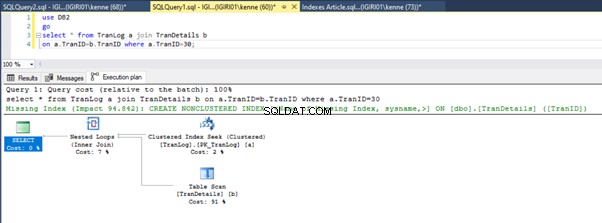
Имаме търсене на индекс в листинг 5b. Това се случва заради колоната, включена в предиката на клаузата WHERE – TranID. Това е колоната, към която сме приложили индекс.
След това въвеждаме външен ключ в TranID колона на TranDetails таблица (листинг 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Това не променя много в плана за изпълнение. Ситуацията е почти същата, както е показано по-рано на фигури 3 и 4.
След това въвеждаме индекс в колоната с външен ключ:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
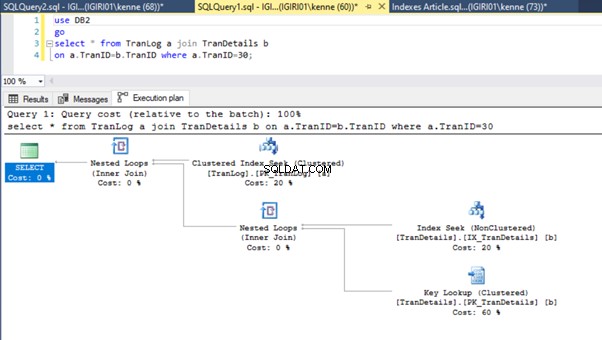
Това действие променя драстично плана за изпълнение на листинг 5b (вижте фигура 6). Виждаме да се случват повече търсения на индекс. Също така, обърнете внимание на търсенето на RID на фигура 6.
Проверките на RID на купища обикновено се случват при липса на първичен ключ. Хийп е таблица без първичен ключ.
Накрая добавяме първичен ключ към TranDetails маса. Това премахва сканирането на таблицата и търсенето на RID heap съответно в листинги 5a и 5b (вижте фигури 7 и 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Заключение
Подобрението на производителността, въведено от индексите, е добре познато дори на начинаещите DBA. Въпреки това искаме да отбележим, че трябва да разгледате внимателно как заявките използват индекси.
Освен това идеята е да се установи решението в конкретния случай, когато имаме заявки за присъединяване между Журнал на транзакциите таблици и Подробности за транзакцията таблици.
По принцип има смисъл да се наложи връзката между такива таблици с помощта на ключ и да се въведат индекси към колоните с първичен и външен ключ.
При разработването на приложения, които използват такъв дизайн, разработчиците трябва да имат предвид необходимите индекси и връзки на етапа на проектиране. Съвременните инструменти за специалистите по SQL Server правят тези изисквания много по-лесни за изпълнение. Можете да профилирате заявките си с помощта на специализирания инструмент за профилиране на заявки. Той е част от многофункционалното професионално решение dbForge Studio за SQL Server, разработено от Devart, за да направи живота на DBA по-опростен.