Защо?
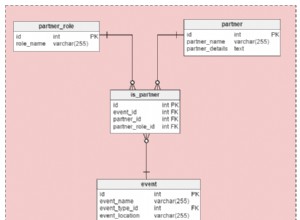
Заявката не може да използва индекса на принципала. Ще ви трябва индекс на таблицата locations , но този, който имате, е в таблицата адреси .
Можете да потвърдите твърдението ми, като зададете:
SET enable_seqscan = off;
(Само във вашата сесия и само за отстраняване на грешки. Никога не го използвайте в производството.) Не е като индексът да е по-скъп от последователно сканиране, просто няма начин Postgres да го използва за вашата заявка въобще .
Отстрани:[INNER] JOIN ... ON true е просто неудобен начин да се каже CROSS JOIN ...
Защо се използва индексът след премахване на ORDER и LIMIT ?
Тъй като Postgres може да пренапише тази проста форма на:
SELECT *
FROM addresses a
JOIN locations l ON a.address ILIKE '%' || l.postalcode || '%';
Ще видите абсолютно същия план за заявка. (Поне аз го правя в моите тестове на Postgres 9.5.)
Решение
Имате нужда от индекс на locations.postalcode . И докато използвате LIKE или ILIKE ще трябва да въведете и индексирания израз (postalcode ) на наляво страна на оператора. КАТО се реализира с оператора ~~* и този оператор няма COMMUTATOR (логическа необходимост), така че не е възможно да се обръщат операндите. Подробно обяснение в тези свързани отговори:
- Може ли PostgreSQL да индексира колони от масив?
- PostgreSQL - текстов масив съдържа стойност, подобна на
- Има ли начин за полезно индексиране на текстова колона, съдържаща модели на регулярен израз?
Решение е да се използва оператор за сходство на триграма %
или неговия обратен, оператор на разстояние <->
в най-близкия съсед вместо това заявка (всеки е комутатор сам за себе си, така че операндите могат да сменят местата си свободно):
SELECT *
FROM addresses a
JOIN LATERAL (
SELECT *
FROM locations
ORDER BY postalcode <-> a.address
LIMIT 1
) l ON address ILIKE '%' || postalcode || '%';
Намерете най-сходния пощенски код за всеки адрес и след това проверете дали този пощенски код всъщност съвпада напълно.
По този начин, по-дълъг пощенски код ще бъде предпочитан автоматично, тъй като е по-сходен (по-малко разстояние) от по-къс пощенски код това също съвпада.
Остава малко несигурност. В зависимост от възможните пощенски кодове може да има фалшиви положителни резултати поради съвпадение на триграми в други части на низа. Във въпроса няма достатъчно информация, за да се каже повече.
Тук , [INNER] JOIN вместо CROSS JOIN има смисъл, тъй като добавяме действително условие за присъединяване.
И така:
CREATE INDEX locations_postalcode_trgm_gist_idx ON locations
USING gist (postalcode gist_trgm_ops);