Моят PostgreSQL сортира както искате. Начинът, по който PostgreSQL сравнява низове, се определя от локал и сортиране. Когато създавате база данни с помощта на createdb има -l опция за задаване на локал. Също така можете да проверите как е конфигуриран във вашата среда, като използвате psql -l :
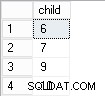
[example@sqldat.com]$ psql -l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
---------+----------+----------+------------+------------+-----------------------
mn_test | postgres | UTF8 | pl_PL.UTF8 | pl_PL.UTF8 |
Както виждате моята база данни използва полско сортиране.
Ако сте създали база данни, използвайки друго сортиране, тогава можете да използвате друго сортиране в заявката точно като:
SELECT * FROM sort_test ORDER BY name COLLATE "C";
SELECT * FROM sort_test ORDER BY name COLLATE "default";
SELECT * FROM sort_test ORDER BY name COLLATE "pl_PL";
Можете да изброите наличните съпоставки чрез:
SELECT * FROM pg_collation;
РЕДАКТИРАНО:
О, пропуснах, че 'a11' трябва да е преди 'a2'.
Не мисля, че стандартното сортиране може да реши буквено-цифровото сортиране. За такова сортиране ще трябва да разделите низа на части точно както в отговора на Clodoaldo Neto. Друга полезна опция, ако често ви се налага да поръчвате по този начин, е да разделите полето за име на две колони. Можете да създадете тригер на INSERT и UPDATE, който разделя name в name_1 и name_2 и след това:
SELECT name FROM sort_test ORDER BY name_1 COLLATE "en_EN", name_2;
(Промених сортирането от полски на английски, трябва да използвате родното си сортиране, за да сортирате букви като aącć и т.н.)