Единична точка на отказ (SPOF) е често срещана причина, поради която организациите работят за разпространение на присъствието на техните среди на база данни на друго географско местоположение. Това е част от стратегическите планове за възстановяване при бедствия и непрекъснатост на бизнеса.
Планирането за възстановяване при бедствия (DR) включва технически процедури, които обхващат подготовката за непредвидени проблеми като природни бедствия, аварии (като човешка грешка) или инциденти (като престъпни деяния).
През последното десетилетие разпространението на вашата среда на база данни в множество географски местоположения беше доста често срещана настройка, тъй като публичните облаци предлагат много начини за справяне с това. Предизвикателството идва в настройването на среди на база данни. Създава предизвикателства, когато се опитвате да управлявате базата данни, да преместите данните си на друго географско местоположение или да приложите сигурност с високо ниво на наблюдаемост.
В този блог ще покажем как можете да направите това с MySQL репликация. Ще разгледаме как можете да копирате данните си в друг възел на базата данни, разположен в друга държава, отдалечена от текущата география на клъстера MySQL. За този пример нашият целеви регион е базиран на нас-изток, докато моят on-prem е в Азия, разположен във Филипините.
Защо ми трябва клъстер от база данни за геолокация?
Дори Amazon AWS, най-добрият доставчик на публичен облак, твърди, че страдат от прекъсвания или непредвидени прекъсвания (като този, който се случи през 2017 г.). Да приемем, че използвате AWS като вторичен център за данни, освен вашия on-prem. Не можете да имате вътрешен достъп до основния хардуер или до онези вътрешни мрежи, които управляват вашите изчислителни възли. Това са напълно управлявани услуги, за които сте платили, но не можете да избегнете факта, че може да пострада от прекъсване по всяко време. Ако такова географско местоположение претърпи прекъсване, тогава може да имате дълъг престой.
Този тип проблем трябва да се предвиди по време на планирането Ви за непрекъснатост на бизнеса. Трябва да е анализиран и приложен въз основа на това, което е дефинирано. Непрекъсваемостта на бизнеса за вашите MySQL бази данни трябва да включва високо време на работа. Някои среди правят сравнителни показатели и задават висока лента от строги тестове, включително слабата страна, за да разкрият всяка уязвимост, колко устойчива може да бъде и колко мащабируема е вашата технологична архитектура, включително вашата инфраструктура на базата данни. За бизнеса, особено за тези, които обработват големи транзакции, е наложително да се гарантира, че производствените бази данни са налични за приложенията през цялото време, дори когато настъпи катастрофа. В противен случай може да възникне престой и това може да ви струва голяма сума пари.
С тези идентифицирани сценарии организациите започват да разширяват своята инфраструктура до различни доставчици на облак и да поставят възли на различни геолокации, за да имат по-високо време на работа (ако е възможно при 99.99999999999), по-ниско RPO и няма SPOF.
За да се гарантира, че производствените бази данни ще оцелеят при бедствие, трябва да бъде конфигуриран сайт за възстановяване след бедствие (DR). Производствените и DR сайтовете трябва да са част от два географски отдалечени центъра за данни. Това означава, че резервната база данни трябва да бъде конфигурирана на сайта на DR за всяка производствена база данни, така че промените в данните, настъпващи в производствената база данни, незабавно да се синхронизират към резервната база данни чрез регистрационни файлове за транзакции. Някои настройки също използват своите DR възли за обработка на четения, за да осигурят балансиране на натоварването между приложението и слоя данни.
Желаната архитектурна настройка
В този блог желаната настройка е проста и все пак много често срещана реализация в днешно време. Вижте по-долу желаната архитектурна настройка за този блог:
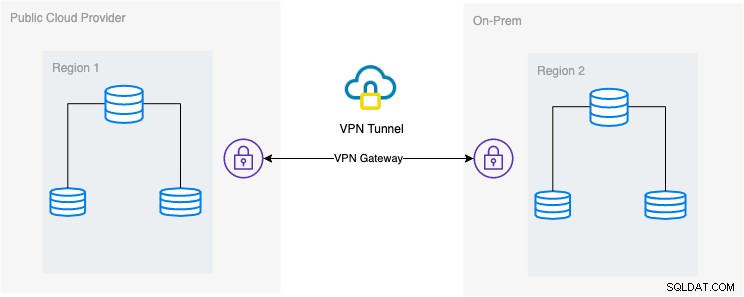
В този блог избирам Google Cloud Platform (GCP) като обществена облачен доставчик и използвам моята локална мрежа като моя локална среда на база данни.
Задължително е, когато използвате този тип дизайн, винаги имате нужда както от среда, така и от платформа, за да комуникирате по много сигурен начин. Използване на VPN или използване на алтернативи като AWS Direct Connect. Въпреки че тези публични облаци днес предлагат управлявани VPN услуги, които можете да използвате. Но за тази настройка ще използваме OpenVPN, тъй като не се нуждая от сложен хардуер или услуга за този блог.
Най-добрият и най-ефективен начин
За среди на база данни MySQL/Percona/MariaDB, най-добрият и ефикасен начин е да направите резервно копие на вашата база данни, да изпратите до целевия възел, за да бъде разгърнат или инстанциран. Има различни начини да използвате този подход или можете да използвате mysqldump, mydumper, rsync или да използвате Percona XtraBackup/Mariabackup и да предавате поточно данните към целевия възел.
Използване на mysqldump
mysqldump създава логическо архивиране на цялата ви база данни или можете избирателно да изберете списък с бази данни, таблици или дори конкретни записи, които искате да изхвърлите.
Проста команда, която можете да използвате, за да направите пълно архивиране, може да бъде,
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | mysql -h <target-host-db-node -u<user> -p<password> -vvv --show-warningsС тази проста команда тя ще изпълни директно MySQL операторите към целевия възел на базата данни, например вашия целеви възел на базата данни на Google Compute Engine. Това може да бъде ефективно, когато данните са по-малки или имате бърза честотна лента. В противен случай опаковането на вашата база данни във файл и след това изпращането й до целевия възел може да бъде вашата опция.
$ mysqldump --single-transaction --all-databases --triggers --routines --events --master-data | gzip > mydata.db
$ scp mydata.db <target-host>:/some/pathСлед това стартирайте mysqldump към целевия възел на базата данни като такъв,
zcat mydata.db | mysqlНедостатъкът при използването на логическо архивиране с mysqldump е, че е по-бавен и консумира дисково пространство. Той също така използва една нишка, така че не можете да изпълнявате това паралелно. По желание можете да използвате mydumper, особено когато данните ви са твърде големи. mydumper може да се изпълнява паралелно, но не е толкова гъвкав в сравнение с mysqldump.
Използване на xtrabackup
xtrabackup е физическо архивиране, където можете да изпращате потоците или двоичен файл към целевия възел. Това е много ефективно и се използва най-вече при поточно предаване на архивиране през мрежата, особено когато целевият възел е с различна география или различен регион. ClusterControl използва xtrabackup, когато осигурява или създава инстанция на нов подчинен, независимо къде се намира, стига достъпът и разрешението да са настроени преди действието.
Ако използвате xtrabackup, за да го стартирате ръчно, можете да изпълните командата като такава,
## Целеви възел
$ socat -u tcp-listen:9999,reuseaddr stdout 2>/tmp/netcat.log | xbstream -x -C /var/lib/mysql## Изходен възел
$ innobackupex --defaults-file=/etc/my.cnf --stream=xbstream --socket=/var/lib/mysql/mysql.sock --host=localhost --tmpdir=/tmp /tmp | socat -u stdio TCP:192.168.10.70:9999За да се разработят тези две команди, първата команда трябва да се изпълни или изпълни първа на целевия възел. Командата на целевия възел слуша на порт 9999 и ще запише всеки поток, който е получен от порт 9999 в целевия възел. Зависи от командите socat и xbstream, което означава, че трябва да сте сигурни, че тези пакети са инсталирани.
На изходния възел той изпълнява innobackupex perl скрипта, който извиква xtrabackup на заден план и използва xbstream за поточно предаване на данните, които ще бъдат изпратени по мрежата. Командата socat отваря порт 9999 и изпраща неговите данни до желания хост, който е 192.168.10.70 в този пример. Все пак се уверете, че имате инсталирани socat и xbstream, когато използвате тази команда. Алтернативен начин за използване на socat е nc, но socat предлага по-разширени функции в сравнение с nc, като сериализация, като множество клиенти могат да слушат на порт.
ClusterControl използва тази команда, когато възстановява подчинен или изгражда нов подчинен. Той е бърз и гарантира, че точното копие на вашите изходни данни ще бъде копирано във вашия целеви възел. Когато предоставяте нова база данни в отделна геолокация, използването на този подход предлага по-голяма ефективност и ви предлага повече скорост за завършване на работата. Въпреки че може да има плюсове и минуси при използване на логическо или двоично архивиране при поточно предаване по кабела. Използването на този метод е много често срещан подход при настройване на нов клъстер от база данни за геолокация в различен регион и създаване на точно копие на средата на вашата база данни.
Ефективност, наблюдаемост и скорост
Въпросите, оставени от повечето хора, които не са запознати с този подход, винаги обхващат проблемите "КАК, КАКВО, КЪДЕ". В този раздел ще покрием как можете ефективно да настроите вашата база данни за геолокация с по-малко работа и с видимост защо тя се проваля. Използването на ClusterControl е много ефективно. В тази текуща настройка имам следната среда, както първоначално е внедрена:
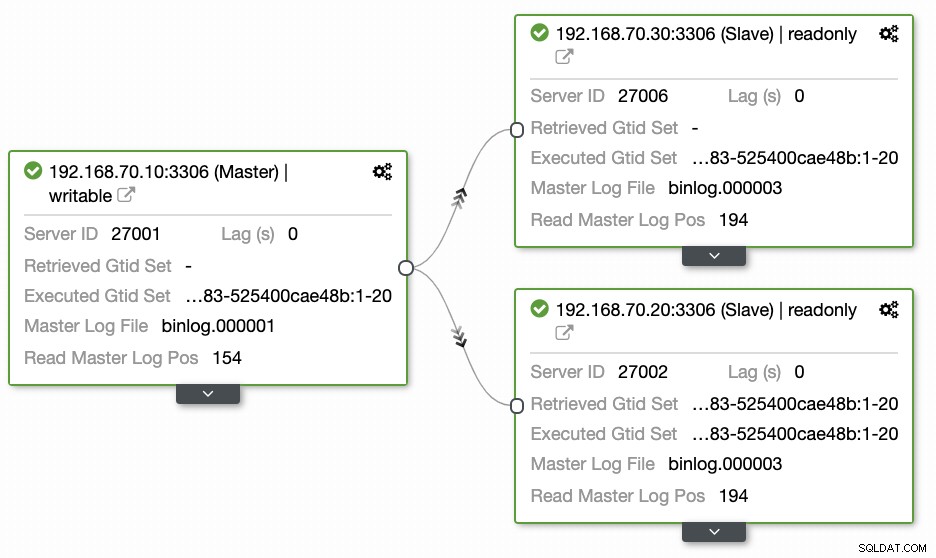
Разширяване на възел до GCP
Започвайки да настройвате своя клъстер от база данни за географско местоположение, за да разширите своя клъстер и да създадете копие на моментна снимка на вашия клъстер, можете да добавите нов подчинен. Както споменахме по-рано, ClusterControl ще използва xtrabackup (mariabackup за MariaDB 10.2 по-нататък) и ще разгърне нов възел във вашия клъстер. Преди да можете да регистрирате своите GCP изчислителни възли като целеви възли, трябва първо да настроите съответния системен потребител, същият като системния потребител, който сте регистрирали в ClusterControl. Можете да проверите това във вашия /etc/cmon.d/cmon_X.cnf, където X е cluster_id. Например, вижте по-долу:
# grep 'ssh_user' /etc/cmon.d/cmon_27.cnf
ssh_user=maximusmaximus (в този пример) трябва да присъства във вашите GCP изчислителни възли. Потребителят във вашите GCP възли трябва да има привилегии на sudo или супер администратор. Той също така трябва да бъде настроен с SSH достъп без парола. Моля, прочетете нашата документация повече за потребителя на системата и необходимите му привилегии.
Нека имаме примерен списък със сървъри по-долу (от GCP конзолата:таблото за управление на Compute Engine):
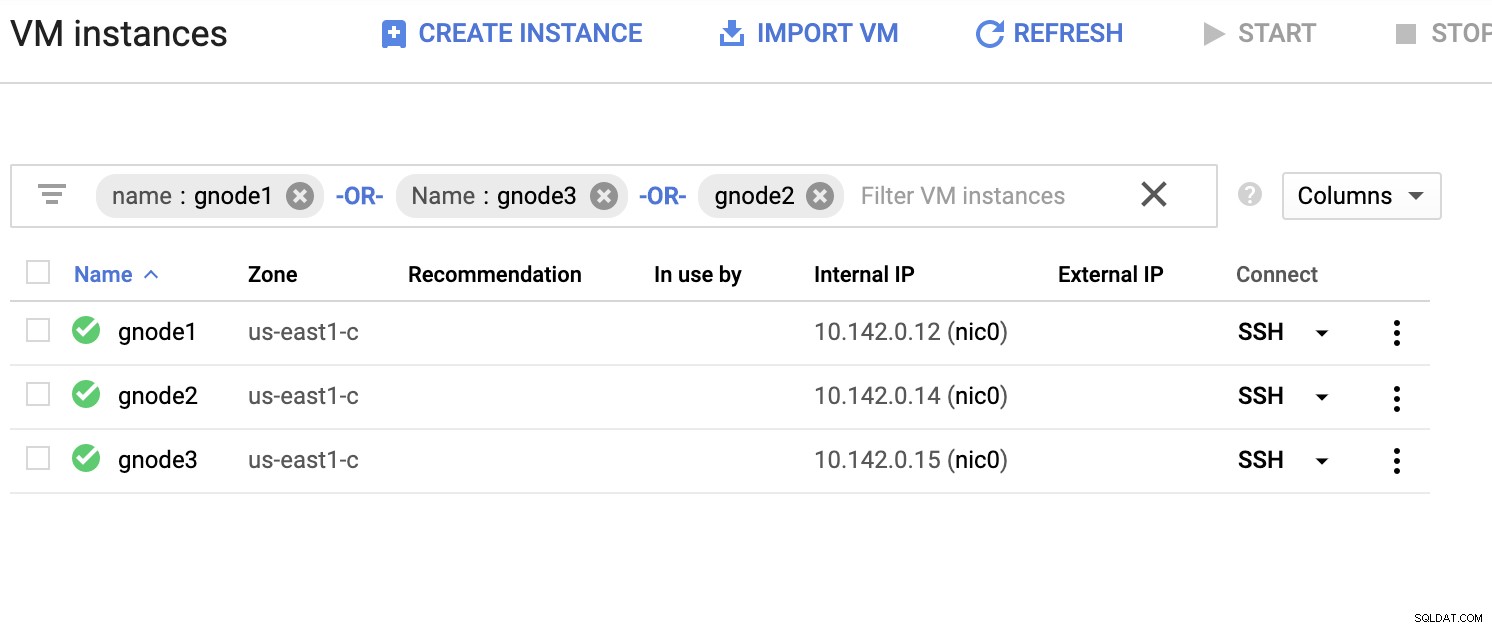
На екранната снимка по-горе нашият целеви регион се основава на изток от САЩ регион. Както беше отбелязано по-рано, моята локална мрежа е настроена през защитен слой, преминаващ през GCP (обратно) с помощта на OpenVPN. Така че комуникацията от GCP, която отива към моята локална мрежа, също е капсулирана през VPN тунела.
Добавяне на подчинен възел към GCP
Екранната снимка по-долу разкрива как можете да направите това. Вижте изображенията по-долу:
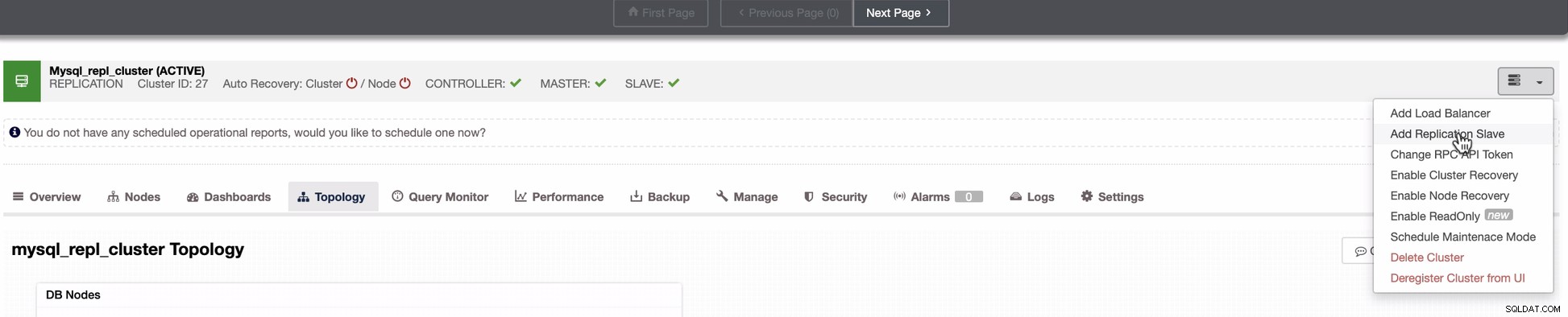
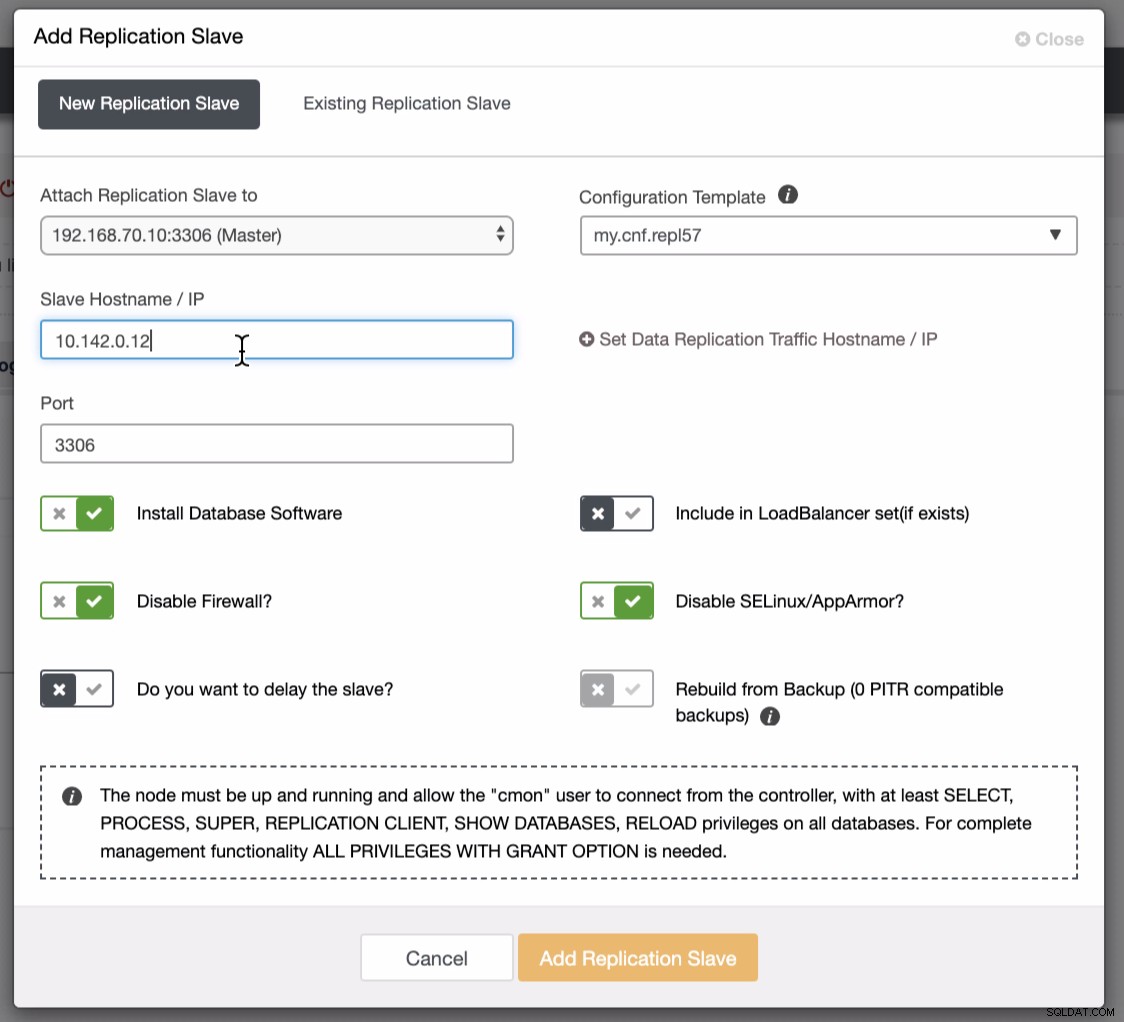
Както се вижда на втората екранна снимка, ние сме насочени към възел 10.142.0.12 и главният му източник е 192.168.70.10. ClusterControl е достатъчно умен, за да определи защитни стени, модули за сигурност, пакети, конфигурация и настройка, която трябва да се направи. Вижте по-долу пример за дневник на работните дейности:
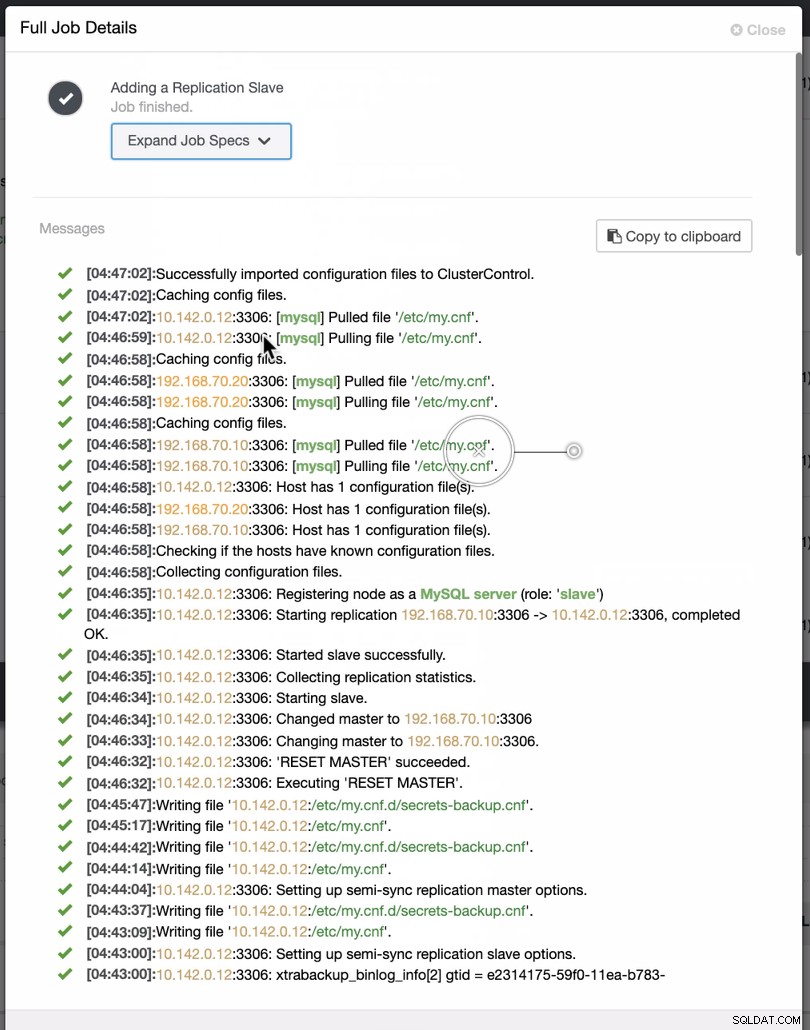
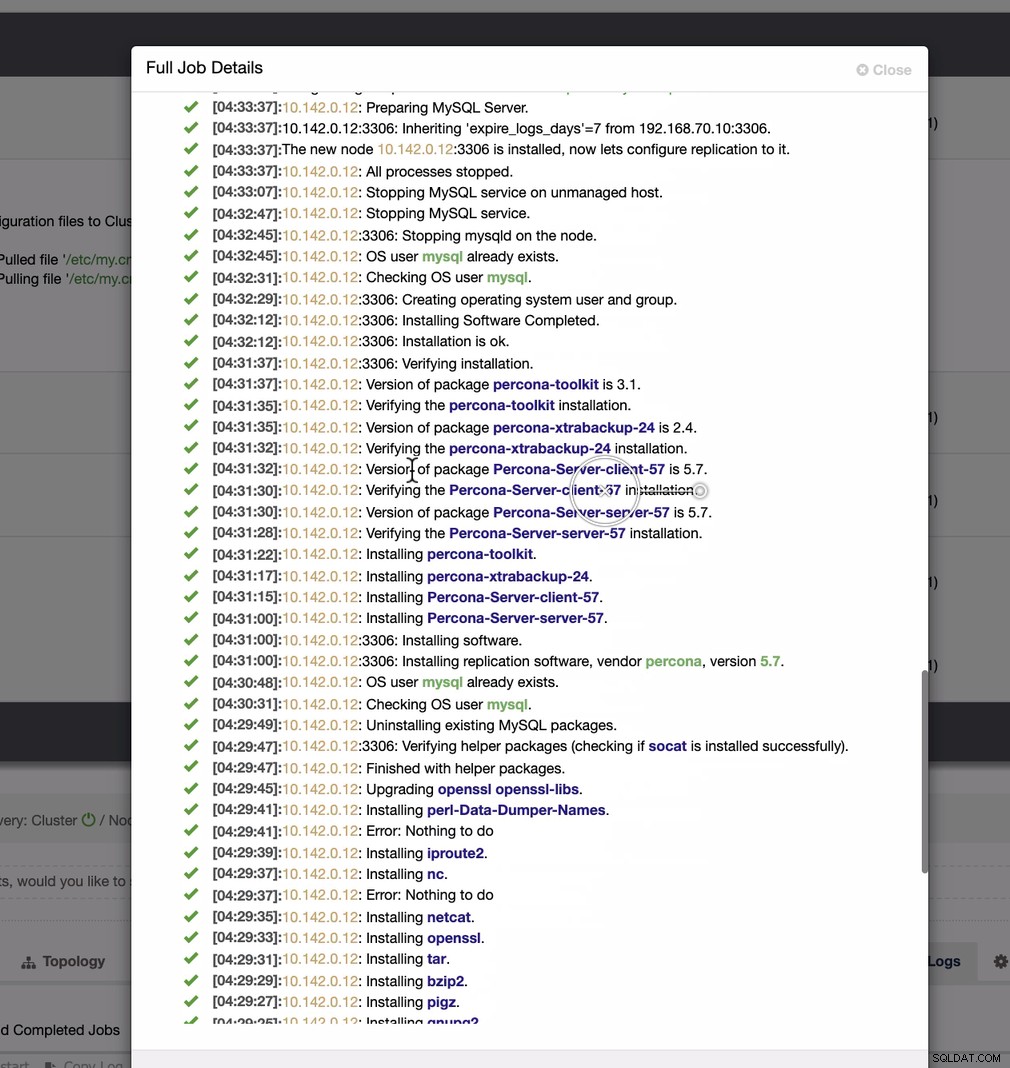
Доста проста задача, нали?
Попълнете GCP MySQL клъстер
Трябва да добавим още два възела към GCP клъстера, за да имаме топология на баланса, каквато имахме в локалната мрежа. За втория и третия възел се уверете, че главният трябва да сочи към вашия GCP възел. В този пример главният е 10.142.0.12. Вижте по-долу как да направите това,
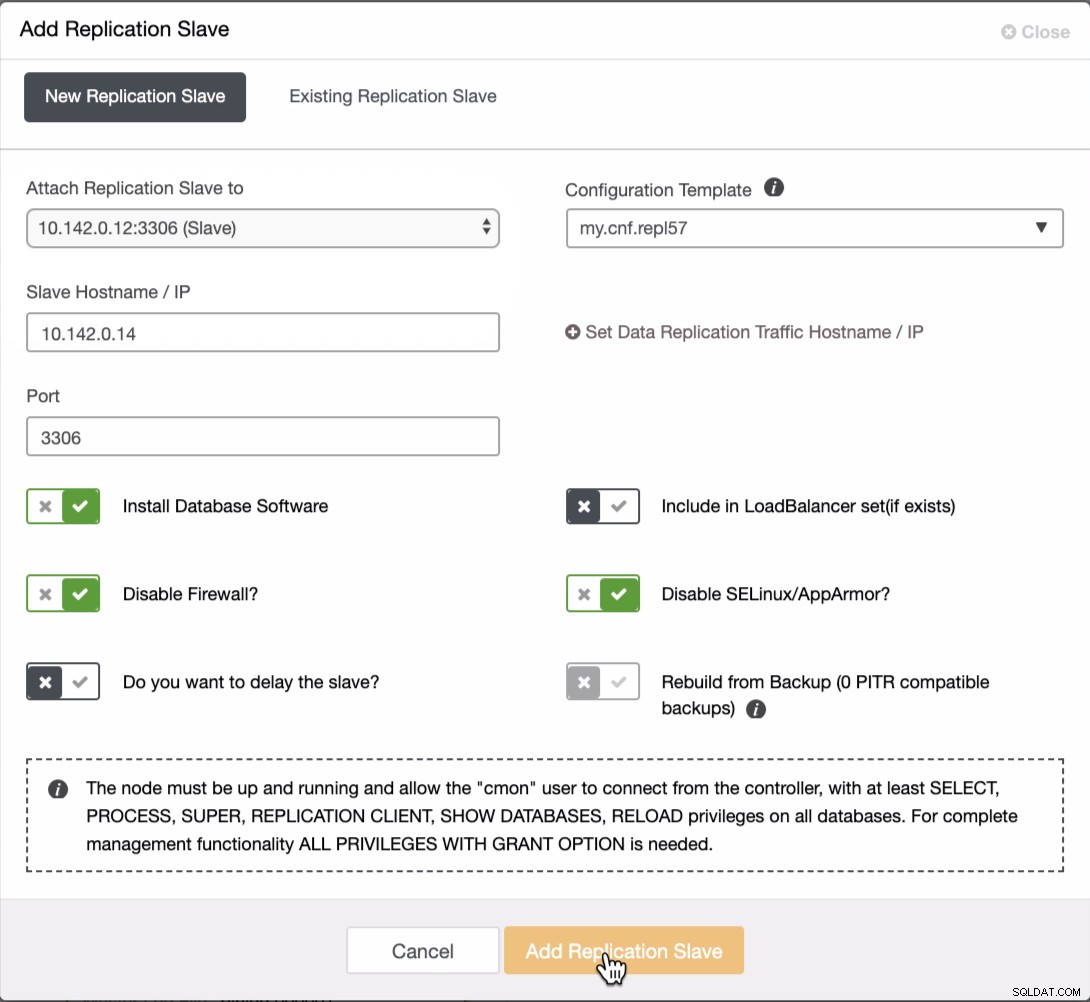
Както се вижда на екранната снимка по-горе, избрах 10.142.0.12 (подчинен ), който е първият възел, който добавихме в клъстера. Пълният резултат се показва, както следва,
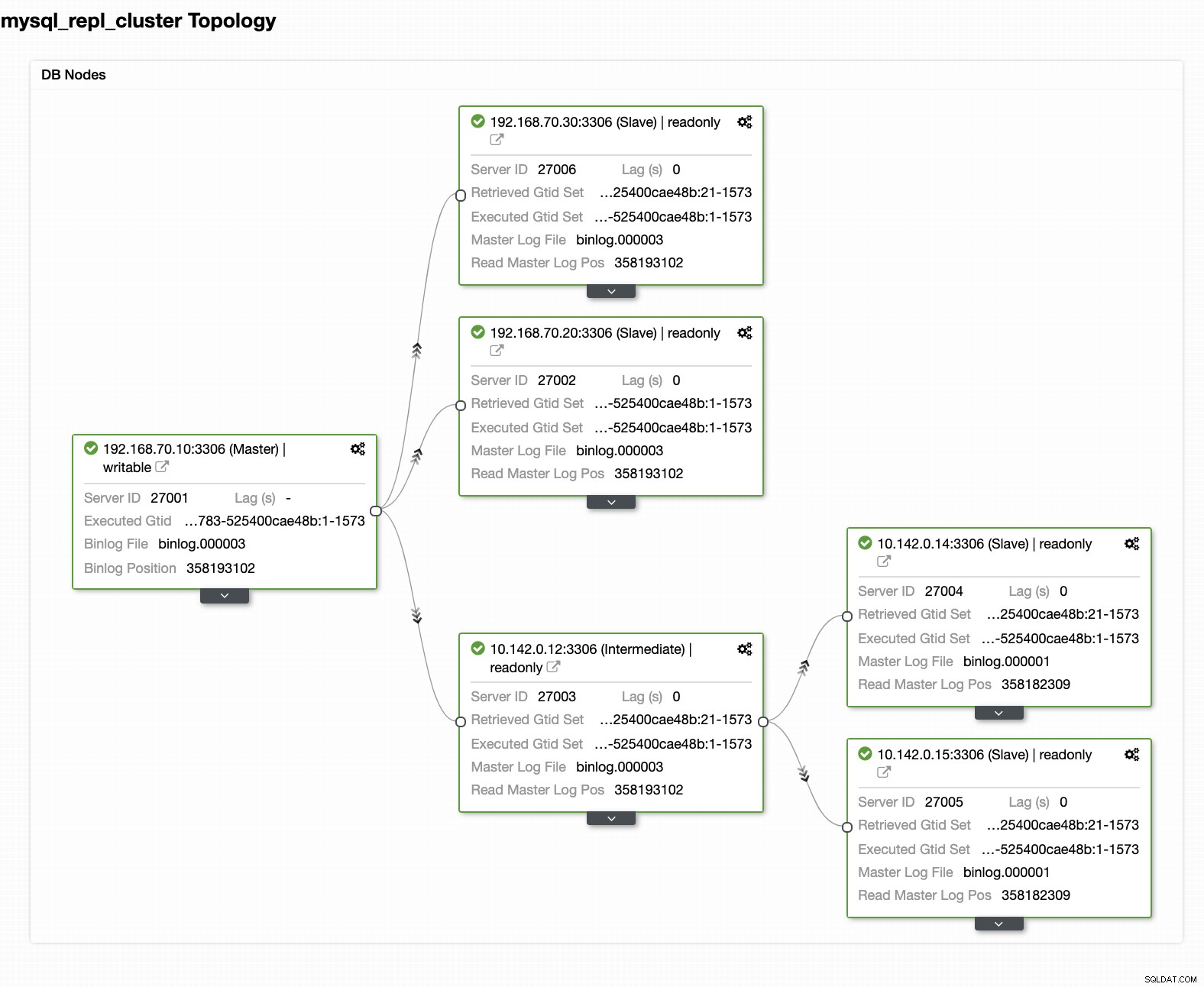
Вашата окончателна настройка на клъстер с база данни за геолокация
От последната екранна снимка този вид топология може да не е идеалната ви настройка. Най-често това трябва да бъде настройка с няколко главни, където вашият DR клъстер служи като резервен клъстер, където вашият on-prem служи като основен активен клъстер. За да направите това, в ClusterControl е доста просто. Вижте следните екранни снимки, за да постигнете тази цел.
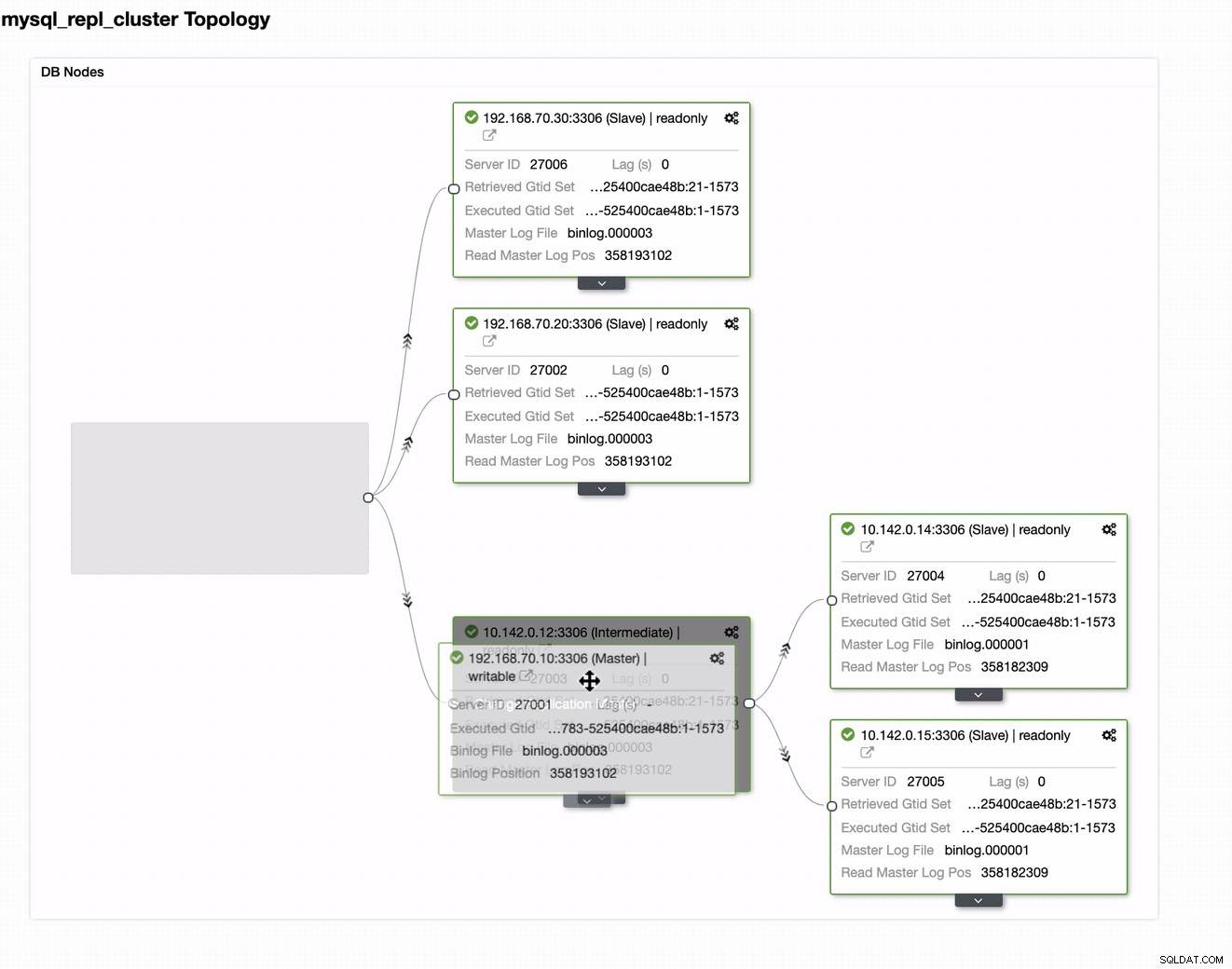
Можете просто да плъзнете текущия си мастер към целевия главен файл, който трябва да бъде настройте като първичен записващо устройство в режим на готовност само в случай, че се нараните на премиум. В този пример плъзгаме насочващ хост 10.142.0.12 (GCP изчислителен възел). Крайният резултат е показан по-долу:
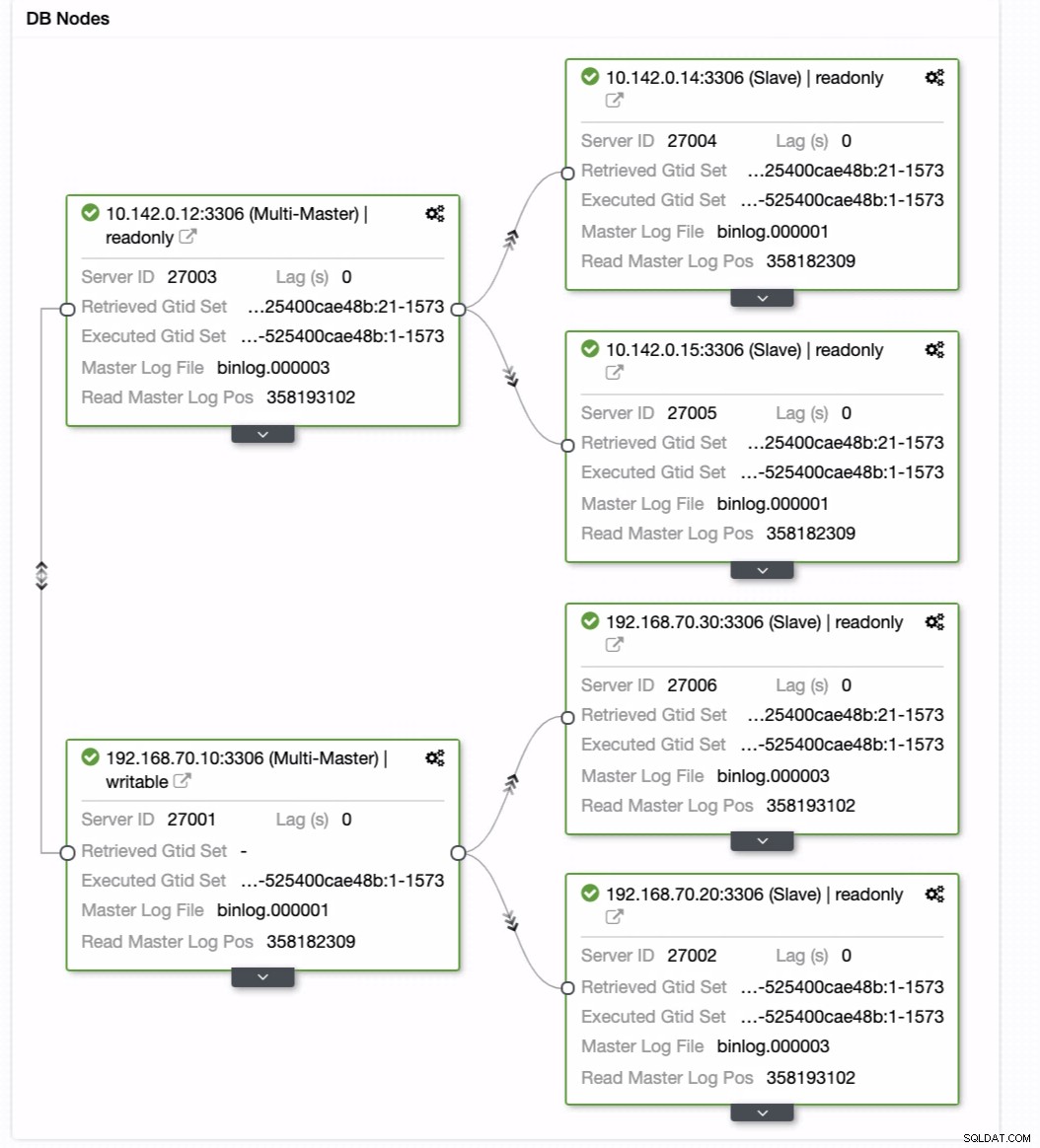
След това постига желания резултат. Лесно и много бързо да създадете своя клъстер от база данни за геолокация с помощта на MySQL репликация.
Заключение
Наличието на клъстер от база данни за геолокация не е новост. Това беше желана настройка за компании и организации, избягващи SPOF, които искат устойчивост и по-ниско RPO.
Основните изводи за тази настройка са сигурността, резервирането и устойчивостта. Той също така обхваща колко осъществимо и ефективно можете да разгърнете своя нов клъстер в различен географски регион. Въпреки че ClusterControl може да предложи това, очаквайте, че можем да подобрим това по-рано, където можете да създадете ефективно от резервно копие и да създадете своя нов различен клъстер в ClusterControl, така че следете за новости.