През последните няколко месеца ние от 2ndQuadrant работихме по обединяването на PostgreSQL 9.6 в Postgres-XL, което се оказа доста предизвикателно поради различни причини и отне повече време от първоначално планираното поради няколко инвазивни промени нагоре по веригата. Ако се интересувате, вижте официалното хранилище тук (засега вижте клона „главен“).
Все още има доста работа за вършене – обединяване на няколко оставащи битове от нагоре по веригата, коригиране на известни грешки и неуспехи при регресия, тестване и т.н. Ако обмисляте да допринесете за Postgres-XL, това е идеална възможност (изпратете ми e-mail и аз ще ви помогна с първите стъпки).
Но като цяло Postgres-XL 9.6 очевидно е голяма стъпка напред в редица важни области.
Нови функции в Postgres-XL 9.6
И така, какви нови функции придобива Postgres-XL от сливането на PostgreSQL 9.6? Бих могъл просто да ви насоча към бележките за версията нагоре по веригата – повечето от подобренията се отнасят директно за XL 9.6, с изключение на тези, свързани с функции, които не се поддържат в XL.
Основното видимо от потребителите подобрение в PostgreSQL 9.6 беше явно паралелна заявка и това важи и за Postgres-XL 9.6.
Вътрешен възел паралелизъм
Преди PostgreSQL 9.6, Postgres-XL беше един от начините за получаване на паралелни заявки (чрез поставяне на множество възли на Postgres-XL на една и съща машина). След PostgreSQL 9.6 това вече не е необходимо, но също така означава, че Postgres-XL получава възможност за паралелизъм в рамките на възела.
За сравнение, това е, което Postgres-XL 9.5 ви позволява да правите – да разпространявате заявка до множество възли с данни, но всеки възел на данни все още е обект на ограничението „един бекенд на заявка“, точно като обикновения PostgreSQL.
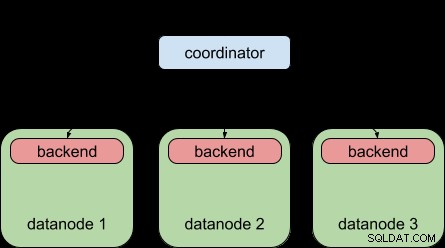
Благодарение на функцията за паралелни заявки на PostgreSQL 9.6, Postgres-XL 9.6 вече може да направи това:
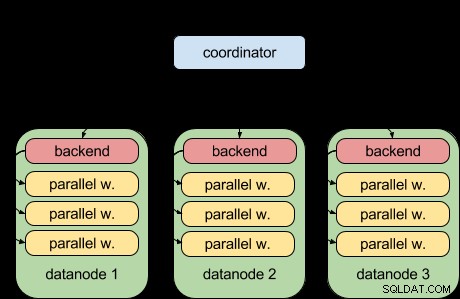
Тоест всеки възел на данни вече може да изпълнява своята част от заявката паралелно, като използва инфраструктурата за паралелни заявки нагоре по веригата. Това е страхотно и прави Postgres-XL много по-мощен, когато става въпрос за аналитични натоварвания.
Поддържане на вилица
Споменах, че това сливане се оказа по-предизвикателно, отколкото първоначално очаквахме, поради редица причини.
Първо, поддържането на разклонения като цяло е трудно, особено когато проектът нагоре по веригата се движи толкова бързо, колкото PostgreSQL. Трябва да разработите функции, специфични за вашата вилка, поради което на първо място съществуват вилки. Но вие също искате да сте в крак с горния поток, в противен случай ще изостанете безнадеждно. Ето защо някои от съществуващите разклонения все още са блокирани в PostgreSQL 8.x, като липсват всички екстри, извършени оттогава.
Второ, сливането беше направено в една голяма бучка, точно както всички предишни (9.5, 9.2, ...). Тоест, всички комити нагоре по веригата бяха обединени в една команда git merge. Това е доста гарантирано, че ще предизвика много конфликти при сливане, до степен, че кодът дори не се компилира, да не говорим за провеждане на регресионни тестове или нещо подобно.
Така че първата партида от корекции е свързана с привеждането й в компилируемо състояние, следващата партида е за това да я накарате да работи действително без непосредствени сег-погрешки и след това накрая започва „редовното“ коригиране (изпълнете регресионни тестове, коригирайте проблеми, изплакнете и повторете) .
Тези сложности са присъщи на поддръжката на форк (и причина, поради която вероятно трябва да преосмислите стартирането на още един форк и вместо това да допринесете директно или за Postgres и/или Postgres-XL).
Но има начини за значително намаляване на въздействието – например планираме да направим следващото сливане (с PostgreSQL 10) на по-малки парчета. Това трябва да сведе до минимум степента на конфликтите при сливане и да ни позволи да разрешаваме неуспехите много по-бързо.
По-близо до PostgreSQL
Интересното е, че приемането на паралелизъм от горния поток също ни позволи да се отървем от много код от кодовата база XL – отличен пример за това е паралелният обобщен код, който лесно замени специфичния за XL код.
Друг пример за промяна нагоре по веригата, която значително повлия на XL кода, е „патификацията“ на горния плановик, избутана в края на цикъла на разработка на 9.6. Това се оказа много инвазивна промяна (всъщност редица открити грешки вероятно са свързани с нея), но в крайна сметка ни позволи да опростим кода за планиране (по същество да изградим правилни пътища, вместо да променяме получения план).
Когато казвам, че сливането ни позволи да опростим XL кода и да го направим по-близо до PostgreSQL, какво имам предвид с това? Най-простият начин за количествено определяне на промяната е да направите „git diff –stat“ срещу съответстващия клон нагоре по веригата и да сравните числата. За клоновете 9.5 и 9.6 резултатите изглеждат така:
| версия | файловете са променени | допълнения | изтривания |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| делта | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Ясно е, че сливането на 9.6 значително намалява делтата спрямо нагоре по течението (общо с ~ 14%). Откъде идва тази разлика?
Първо, част от това намаление се дължи на истинско опростяване на кода. Отличен пример за това е паралелният агрегат, който е почти 1:1 замяна на оригиналната реализация на Postgres-XL. Така че току-що го извадихме и вместо това използвахме внедряването нагоре по веригата. Надяваме се да намерим повече такива места в бъдеще и да използваме внедряване нагоре по веригата, вместо да поддържаме собствено.
Второ, голяма част от намалението идва от премахването на мъртвия код. Не само, че сме намалили някои мъртви/недостъпни битове код, ние също така открихме доста изходни файлове, които дори не бяха компилирани и т.н.
Какво следва?
В този момент ние обединихме промените до b5bce6c1, което е мястото, където PostgreSQL 9.6 се разделя от master. Така че, за да настигнем PostgreSQL 9.6.2, трябва да обединим останалите промени в клона 9.6. Като се има предвид, че трябва да има предимно само корекции на грешки, това би трябвало да е (надявам се) доста проста работа в сравнение с пълното сливане.
Разбира се, ще има грешки. Всъщност в този момент все още има няколко неуспешни регресионни теста. Това трябва да се коригира, преди да се направи официална версия на XL 9.6. И трябва да направим повече тестове, така че ако се интересувате да помогнете на Postgres-XL, това би било изключително полезно.
Едно дразнене, за което продължаваме да чуваме, са пакетите или липсата им. Може да сте забелязали, че последните налични пакети са доста стари и има само .rpm, нищо друго. Планираме да се справим с това и да започнем да предлагаме актуални пакети в множество варианти (напр. .rpm и .deb).
Планираме също така да направим някои промени в начина, по който е организиран процеса на разработка, за да улесним приноса и участието в процеса на разработка. Това наистина е отделна тема, която не е свързана с клона 9.6, така че ще публикувам повече подробности за това след няколко дни.