Няма перфектна система, хардуер или топология, за да се избегнат всички възможни проблеми, които биха могли да възникнат в производствена среда. Преодоляването на тези предизвикателства изисква ефективен DRP (план за възстановяване при бедствия), конфигуриран според вашето приложение, инфраструктура и бизнес изисквания. Ключът към успеха в този тип ситуации винаги е колко бързо можем да поправим проблема или да се възстановим от него.
В този блог ще разгледаме най-често срещаните сценарии за отказ на PostgreSQL и ще ви покажем как можете да разрешите или да се справите с проблемите. Ще разгледаме също как ClusterControl може да ни помогне да се върнем онлайн
Общата топология на PostgreSQL
За да разберете често срещаните сценарии на отказ, първо трябва да започнете с обща топология на PostgreSQL. Това може да бъде всяко приложение, свързано към първичен възел на PostgreSQL, което има свързана реплика към него.
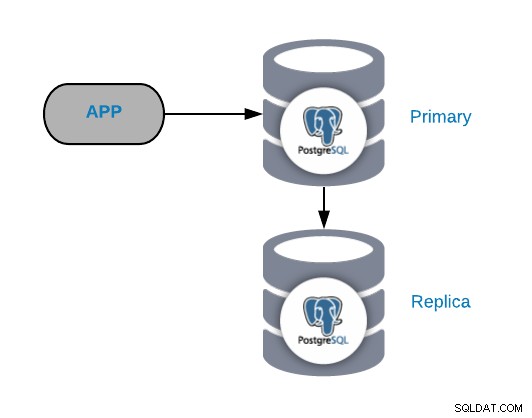
Винаги можете да подобрите или разширите тази топология, като добавите още възли или балансьори на натоварване , но това е основната топология, с която ще започнем да работим.
Основна повреда на PostgreSQL възел
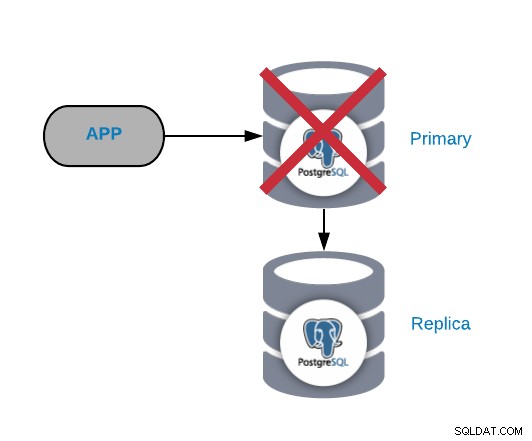
Това е един от най-критичните повреди, тъй като трябва да го поправим възможно най-скоро, ако искаме да запазим нашите системи онлайн. За този тип повреда е важно да има някакъв механизъм за автоматично преминаване при отказ. След неуспеха можете да разгледате причината за проблемите. След процеса на отказ се уверяваме, че неуспешният първичен възел все още не смята, че е първичен възел. Това се прави, за да се избегне несъответствието на данните при писане в него.
Най-честите причини за този вид проблеми са повреда на операционната система, хардуерна повреда или повреда на диска. Във всеки случай трябва да проверим базата данни и регистрационните файлове на операционната система, за да открием причината.
Най-бързото решение за този проблем е чрез изпълнение на задача за преодоляване на срив за намаляване на престоя. За да популяризираме реплика, можем да използваме командата pg_ctl promote на подчинения възел на базата данни и след това трябва да изпратим трафика от приложение към новия първичен възел. За тази последна задача можем да внедрим балансьор на натоварването между нашето приложение и възлите на базата данни, за да избегнем всяка промяна от страна на приложението в случай на неуспех. Можем също да конфигурираме балансира на натоварването да открие повреда на възела и вместо да изпраща трафик към него, да изпраща трафика към новия основен възел.
След процеса на отказ и се уверим, че системата работи отново, можем да разгледаме проблема и препоръчваме да поддържаме винаги работещ поне един подчинен възел, така че в случай на нов първичен повред, можем да изпълним отново задачата за преодоляване на срив.
Повреда на възела на репликата на PostgreSQL
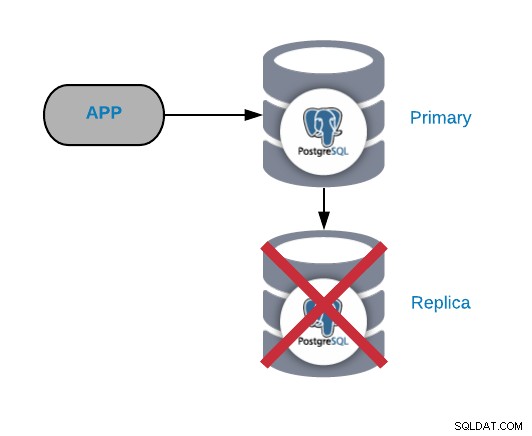
Това обикновено не е критичен проблем (стига да имате повече от една реплика и не я използват за изпращане на прочетения производствен трафик). Ако изпитвате проблеми с основния възел и нямате актуална реплика, ще имате истински критичен проблем. Ако използвате нашата реплика за отчитане или целите на големи данни, вероятно ще искате да я поправите бързо така или иначе.
Най-честите причини за този вид проблеми са същите, които видяхме за основния възел, повреда на операционната система, хардуерна повреда или повреда на диска. Трябва да проверите базата данни и регистрационните файлове на операционната система за да откриете причината.
Не се препоръчва системата да работи без реплика, тъй като в случай на повреда нямате бърз начин да се върнете онлайн. Ако имате само един роб, трябва да разрешите проблема възможно най-скоро; най-бързият начин е чрез създаване на нова реплика от нулата. За това ще трябва да направите последователно резервно копие и да го възстановите на подчинения възел, след което да конфигурирате репликацията между този подчинен възел и основния възел.
Ако искате да знаете причината за неуспеха, трябва да използвате друг сървър, за да създадете новата реплика и след това да погледнете в старата, за да я откриете. Когато завършите тази задача, можете също да преконфигурирате старата реплика и да продължите да работят и двете като бъдеща опция за преодоляване на срив.
Ако използвате репликата за отчитане или за целите на големи данни, трябва да промените IP адреса, за да се свържете с новия. Както в предишния случай, един от начините да избегнете тази промяна е да използвате балансьор на натоварване, който ще знае състоянието на всеки сървър, което ви позволява да добавяте/премахвате реплики, както желаете.
Отказ при репликация на PostgreSQL
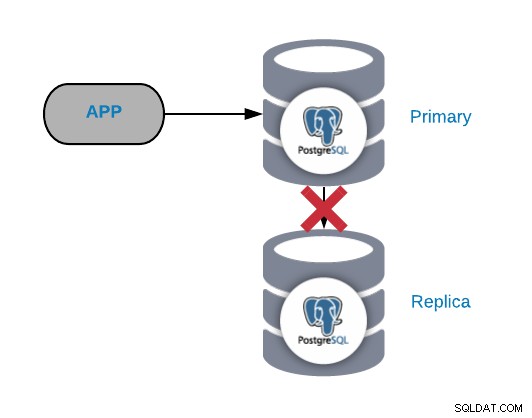
По принцип този вид проблем се генерира поради мрежа или конфигурация проблем. Това е свързано със загуба на WAL (записване напред) в първичния възел и начина, по който PostgreSQL управлява репликацията.
Ако имате важен трафик, правите контролни точки твърде често или съхранявате WALS само за няколко минути; ако имате проблем с мрежата, ще имате малко време да го разрешите. Вашите WAL ще бъдат изтрити, преди да можете да ги изпратите и приложите към репликата.
Ако WAL, от който репликата трябва да продължи да работи, е бил изтрит, трябва да го изградите отново, така че, за да избегнем тази задача, трябва да проверим конфигурацията на нашата база данни, за да увеличим wal_keep_segments (количествата WALS, които да запазим в pg_xlog директория) или параметрите max_wal_senders (максимален брой едновременно работещи процеси на изпращач на WAL).
Друга препоръчителна опция е да конфигурирате archive_mode и да изпратите WAL файловете по друг път с параметъра archive_command. По този начин, ако PostgreSQL достигне лимита и изтрие WAL файла, така или иначе ще го имаме в друг път.
Повреда на PostgreSQL данни/Несъответствие на данните/Случайно изтриване

Това е кошмар за всеки DBA и може би най-сложният проблем коригирано, в зависимост от това колко широко разпространен е проблемът.
Когато вашите данни са засегнати от някои от тези проблеми, най-често срещаният начин за отстраняването им (и вероятно единственият) е чрез възстановяване на резервно копие. Ето защо резервните копия са основната форма на всеки план за възстановяване при бедствия и се препоръчва да имате поне три архива, съхранявани на различни физически места. Най-добрата практика диктува, че архивните файлове трябва да имат един съхраняван локално на сървъра на базата данни (за по-бързо възстановяване), друг в централизиран сървър за архивиране и последният в облака.
Можем също така да създадем комбинация от пълни/инкрементални/диференциални съвместими с PITR архиви, за да намалим нашата цел за точка на възстановяване.
Управление на отказ на PostgreSQL с ClusterControl
Сега, когато разгледахме тези често срещани сценарии за откази на PostgreSQL, нека да разгледаме какво би се случило, ако управлявахме вашите PostgreSQL бази данни от централизирана система за управление на база данни. Един, който е страхотен по отношение на достигането до бърз и лесен начин за отстраняване на проблема, възможно най-скоро, в случай на неуспех.
ClusterControl осигурява автоматизация за повечето от задачите на PostgreSQL, описани по-горе; всичко по централизиран и удобен за потребителя начин. С тази система ще можете лесно да конфигурирате неща, които ръчно биха отнели време и усилия. Сега ще прегледаме някои от основните му характеристики, свързани със сценарии за отказ на PostgreSQL.
Разгръщане/импортиране на PostgreSQL клъстер
След като влезем в интерфейса на ClusterControl, първото нещо, което трябва да направите, е да разположите нов клъстер или да импортирате съществуващ. За да извършите внедряване, просто изберете опцията Разгръщане на клъстер от база данни и следвайте инструкциите, които се появяват.
Мащабиране на вашия PostgreSQL клъстер
Ако отидете на Cluster Actions и изберете Add Replication Slave, можете или да създадете нова реплика от нулата, или да добавите съществуваща PostgreSQL база данни като реплика. По този начин можете да стартирате новата си реплика за няколко минути и ние можем да добавим толкова реплики, колкото искаме; разпространяване на трафика за четене между тях с помощта на балансьор на натоварване (който също можем да приложим с ClusterControl).
Автоматично отказване на PostgreSQL
ClusterControl управлява преодоляването на отказ при настройката ви за репликация. Той открива неизправности на главния и представя подчинен с най-актуалните данни като нов главен. Освен това автоматично се проваля - над останалите подчинени устройства, за да се репликират от новия главен. Що се отнася до клиентските връзки, той използва два инструмента за задачата:HAProxy и Keepalived.
HAProxy е средство за балансиране на натоварването, което разпределя трафика от един източник към една или повече дестинации и може да дефинира специфични правила и/или протоколи за задачата. Ако някоя от дестинациите спре да отговаря, тя се маркира като офлайн и трафикът се изпраща към една от наличните дестинации. Това предотвратява изпращането на трафик към недостъпна дестинация и загубата на тази информация, като я насочва към валидна дестинация.
Keepalived ви позволява да конфигурирате виртуален IP в рамките на активна/пасивна група сървъри. Този виртуален IP се присвоява на активен „главен“ сървър. Ако този сървър не успее, IP адресът автоматично се мигрира към „Вторичния“ сървър, за който е установено, че е пасивен, което му позволява да продължи да работи със същия IP по прозрачен начин за нашите системи.
Добавяне на PostgreSQL Load Balancer
Ако отидете на Cluster Actions и изберете Добавяне на Load Balancer (или от изгледа на клъстера - отидете на Manage -> Load Balancer), можете да добавите балансиращи устройства към нашата топология на базата данни.
Конфигурацията, необходима за създаване на вашия нов балансьор на натоварване, е доста проста. Трябва само да добавите IP/име на хост, порт, политика и възлите, които ще използваме. Можете да добавите два балансира на натоварването с Keepalived между тях, което ни позволява да имаме автоматичен отказ на нашия балансьор на натоварване в случай на повреда. Keepalived използва виртуален IP адрес и го мигрира от един балансьор на натоварването към друг в случай на повреда, така че нашата настройка може да продължи да функционира нормално.
Архивни копия на PostgreSQL
Вече обсъдихме колко е важно да имаме резервни копия. ClusterControl предоставя функционалността или за генериране на незабавно архивиране, или за планиране на такова.
Можете да избирате между три различни резервни метода, pgdump, pg_basebackup или pgBackRest. Можете също да посочите къде да се съхраняват архивите (на сървъра на базата данни, на сървъра на ClusterControl или в облака), нивото на компресия, необходимото криптиране и периода на съхранение.
Наблюдение и предупреждение на PostgreSQL
Преди да можете да предприемете действие, трябва да знаете какво се случва, така че ще трябва да наблюдавате клъстера си от база данни. ClusterControl ви позволява да наблюдавате нашите сървъри в реално време. Има графики с основни данни като процесор, мрежа, диск, RAM, IOPS, както и специфични за базата данни показатели, събрани от екземплярите на PostgreSQL. Заявките към базата данни могат да се разглеждат и от Монитора на заявките.
По същия начин, по който активирате наблюдението от ClusterControl, можете също да настроите сигнали, които да ви информират за събития във вашия клъстер. Тези сигнали са конфигурируеми и могат да бъдат персонализирани според нуждите.
Заключение
В крайна сметка всеки ще трябва да се справи с проблемите и неуспехите на PostgreSQL. И тъй като не можете да избегнете проблема, трябва да можете да го поправите възможно най-скоро и да поддържате системата да работи. Също така видяхме как използването на ClusterControl може да помогне с тези проблеми; всичко от една и удобна за потребителя платформа.
Това са някои от най-често срещаните сценарии на отказ за PostgreSQL. Ще се радваме да чуем за вашия собствен опит и как сте го поправили.



