В предишните ни блогове за хибриден облак често споменаваме, че една от основните опции за използване на настройката на топологията на хибриден облак е да използвате това като цел за възстановяване при бедствия. Обичайно за организационната структура е планът за възстановяване при бедствия (DRP) винаги да се адресира преди архитектурното внедряване на настройката на вашата база данни, било в облака, или локално. Може да си помислите, че всичко ще се провали непредвидимо и може да се отрази трагично на вашия бизнес, ако не бъде адресирано и разбрано правилно. Преодоляването на тези предизвикателства изисква ефективен DRP (план за възстановяване при бедствия), за който вашата система е добре конфигурирана според вашето приложение, инфраструктура и бизнес изисквания. Ключът към успеха в този тип ситуации е колко бързо можем да поправим проблема или да се възстановим от него.
Докато DRP се справя с обстоятелствата при бедствие, Business Continuity ще се увери, че DRP се тества и работи по всяко време, когато е необходимо. Вашите опции за възстановяване след бедствие за вашите бази данни трябва да гарантират непрекъснати операции и граници до границите на очакванията. Тя трябва да е в съответствие с желания от вас RTO и RPO. Наложително е да се гарантира, че производствените бази данни са налични за приложенията дори по време на бедствия; в противен случай това може да се окаже скъпа сделка. DBA, архитектите, трябва да гарантират, че среди на база данни могат да издържат на бедствия и са съвместими с SLA за възстановяване при бедствия. Внедряването на база данни трябва да бъде конфигурирано правилно, за да се гарантира, че бедствията няма да влияят на наличността на базата данни и непрекъснатостта на бизнеса.
Опции за аварийно възстановяване
Вашият PostgreSQL клъстер трябва да бъде конфигуриран със систематичен подход, който се ангажира с най-добрите практики и е приемлив за индустриалните стандарти. Наред със систематичните подходи, следните процеси или механизми ви помагат да гарантирате, че вашият PostgreSQL, разгърнат в хибриден облак, има следните присъствие:
-
Отказ/Превключване
-
Автоматично архивиране
-
Висока достъпност
-
Балансиране на натоварването
-
Силно разпространена среда
Отказ/Превключване
Отказът е автоматизиран процес в случай, че главната ви се провали; Сървърът в режим на гореща готовност или топъл резерв се повишава до ролята на основен/главен. Това е най-добрата практика, която предоставя среда с висока наличност да има поне вторичен възел, който да действа като кандидат за възел за преодоляване на срив. След като основният сървър се повреди, резервният сървър трябва да започне процедурите за преодоляване на срив, а след това вторичният или резервният сървър трябва да поеме ролята на главен. Системата за отказване използва минимум два сървъра в обичайната практика, които служат като основен и резервен. Проверката на свързаността му се подпомага от механизъм за сърдечен ритъм, който извършва непрекъснати проверки и проверява дали и двете са в добро състояние и комуникацията е жива. Въпреки това, в някои случаи връзката може да даде фалшива аларма. Следователно, в някои настройки и среди, наличието на трета система, като възел за наблюдение, се намира в отделна мрежа или център за данни. Това е надеждна опция за предотвратяване на неподходящо или нежелано преминаване при отказ. Един защитен възел за проверка може да притежава допълнителни функции и проверки, което добавя сложност. Тази настройка изисква пълно и стриктно тестване, за да се гарантира, че преодоляването на отказ е извършено точно, когато има промяна в реализацията. Също така това е важно, за да предотвратите влошаване на вашия PostgreSQL
Да приемем, че имате своя вторичен или резервен клъстер в различен център за данни с различна хардуерна настройка; може да не искате да превключвате внезапно, особено ако не е идеален случай само поради фалшиво положително. В този сценарий обаче целевият възел или клъстер за възстановяване на данни трябва да има същите ресурси и спецификации като основния възел или клъстер. Ако целта ви за възстановяване на данни е в публичен облак и основната е локална, уверете се, че вече е обхваната в планирането на капацитета ви и ресурсите имат почти същите спецификации, за да избегнете нежелани резултати.
Когато използвате и се подготвяте за своя механизъм за преодоляване на срив във вашия PostgreSQL клъстер в рамките на хибриден облак, трябва да се уверите, че инструментът ви е идеален за изпълнение на работата, която трябва да постигне. Има инструменти на трети страни, които не са включени в PostgreSQL по отношение на предварителното преминаване на отказ. Например, има ClusterControl, pg_auto_failover от CitusData (c/o Microsoft), Pgpool-II, Bucardo и други. Тези усъвършенствани помощни инструменти осигуряват ограждане на възли или известни като STONITH (застреляйте другия възел в главата). Това гарантира, че вашият неуспешен първичен или главен възел ще избегне приемането на записи или връщането онлайн като предишно състояние, за да обслужва нормални транзакции. Този проблем е известен като сценарий с разделен мозък. Той губи синхронизиране на данните поради повреда (хардуер или ниво на ресурс), но все пак основните ви сървъри, за които се предполага, че е само един основен сървър, действат така, сякаш изпълняват нормални получатели на заявки за запис на данни, причинявайки повреда на данните в целия клъстер.
Автоматично архивиране
Резервните копия винаги осигуряват висока сигурност и предпазни мерки срещу загуба на данни. Архивирането увеличава максимално вашето RPO, тъй като помага да се сведе до минимум загубата на данни при бедствие. Нещата, които трябва да имате предвид и да подготвите за вашето автоматизирано архивиране, обхващат вашето устройство/хардуер за архивиране, резервиране на данни, сигурност, производителност, скорост и съхранение на данни.
Резервно устройство
Тук трябва да имате най-добрия избор за вашето резервно устройство. Скоростта, значителният обем за съхранение и високата достъпност могат да бъдат желаният от вас избор. Някои разчитат на SAN или NAS съхранение или разпространяват своите данни до други доставчици на резервно копие от трети страни. От съществено значение е вашето резервно копие да предлага скорост за запис и четене на данни, особено ако прилагате компресиране и криптиране за вашите данни в покой. Декомпресията и декриптирането изискват ресурси, така че трябва да помислите кога трябва да използвате възстановяване на данни. По време на това състояние трябва да определите, че трябва да постигнете максималното си RPO и да ангажирате постижимото SLA (Споразумение за ниво на обслужване) на клиентите си. Също така е идеално, че може да се наложи да изолирате резервното си копие от локалната си мрежа или да го съхранявате на отдалечено място. Алтернативен подход е да се ангажирате с доставчици от трети страни. Например съхраняването на резервното ви копие в облака може да бъде опция, а тяхното средство е много сложно и удовлетворява вашите изисквания.
Резервно копие на данни
Разпространението на вашите данни на множество местоположения е идеално решение. Това увеличава шансовете ви за възстановяване на данни, например човешка грешка или софтуерна логическа грешка, която ви кара да изтриете стари копия на архива, но погрешно изтривате всички важни архивни копия. В някои сложни среди, като например съхранение в облачна среда като Amazon S3, Cloud Storage от Google или Azure Blob Storage, предлага репликация на съхранения ви файл. Това осигурява повече излишък и може да бъде настроено по гъвкав начин, който отговаря на вашите изисквания.
Висока достъпност
Високо достъпният PostgreSQL клъстер в хибриден облак винаги гарантира, че комуникацията с вашата база данни гарантира време за работа. Идеалният случай на висока наличност зависи от измерването на вашата наличност. В този случай общата настройка за PostgreSQL, разгърнат в хибриден облак, може да бъде или вашата база данни, хоствана в публичен облак, може да бъде вашият вторичен клъстер, действащ като вашия клъстер за възстановяване на данни, в случай че основният клъстер се повреди или претърпи мрежово бедствие и може да отнеме много престой. При някои настройки е възможно вторичният клъстер, лежащ в публичния облак, да не е точно толкова сложен, колкото основния, да кажем, че това е вашият локален или частен облак. Вашето приложение може да играе, за да ограничи посетителите или трафика, които могат да се свържат с вашата база данни. Този тип сценарии може да намали разходите ви за настройка, но разбира се, това зависи само от вашите изисквания. Ако вашият тип приложение е масивен и трябва непрекъснато да получава нормални и натоварени ситуации на трафика, уверете се, че ресурсите на вторичния клъстер трябва да са толкова мощни, колкото и основните, за да гарантирате висока наличност, т.е. 99,9999999%.
За да постигнете високодостъпен PostgreSQL клъстер в хибридна облачна среда, трябва да имате механизъм за превключване при отказ. В случай на повреда и първичен клъстер или първичен сървър се повреди, вторичен или резервен сървър може да поеме ролята на главен, независимо от местоположението му. Най-важното нещо е функционалността и производителността, особено от гледна точка на приложението или клиента, изобщо не се засяга или поне много минимално.
Балансиране на натоварването
Механизмът за балансиране на натоварването за вашия PostgreSQL клъстер подпомага вашата настройка на хибриден облак, която е по-управляема и по-малко рискова, особено когато има голямо натоварване от трафик. В много ситуации сървърът получава тежко високо натоварване, което причинява паника на сървъра. Това води до неизползваемо състояние на сървъра поради заети ресурси, консумирани от много нишки, работещи във фонов режим. Тази ситуация може да бъде подобрена чрез коригиране на лоши заявки и архитектурата на дизайна на вашата база данни. Това трябва да включва как разпределяте четенето спрямо натоварването при запис и задълбочено разбиране на изискванията на вашето приложение, като настройка на главен-главен или само един главен, но да го мащабирате вертикално, за да осигурите по-високи изчислителни и паметови ресурси. Има и голям избор от инструменти на трети страни като pgbouncer и Pgpool II, които да подпомогнат внедряването на PostgreSQL в хибридна облачна среда.
Силно разпространена среда
По отношение на мащабируемостта, силното разпространение на множество местоположения или различни доставчици на облак (on-prem или частен и публичен облак) осигурява повече гъвкавост и поносимост в хибридна облачна среда и това е чудесно за възстановяване при бедствия. Той е гъвкав, когато трябва да премине при отказ на определено място в облак, благоприятно за природно бедствие или катастрофа, особено ако определеният от вас регион, където се намира основният ви клъстер, в момента е опустошен или засегнат от естествена причина. Това е неизбежна причина, която трябва да разберете и да бъдете надеждни за настоящата ситуация. Вашето приложение и клиентите трябва да се обслужват непрекъснато без прекъсване. Това служи за целта да бъде публично достъпно в облака, като същевременно обслужва в частна или локална среда. Тази настройка добавя по-висока сложност и изисква напреднали познания по отношение на базата данни и сигурността и работата в мрежа. Оптимизацията и настройката са от решаващо значение за успеха тук, тъй като е много важно, докато обслужват засилена сигурност за капсулиране на вашите данни, докато пътувате в интернет, производителността трябва да се докаже, че се стабилизира и да не се влияе от внедрената настройка.
Поради сложността на настройката, наличието на инструмент е идеален за управление на внедряването и улесняване на цялостното състояние на вашите бази данни, като се наблюдава един аспект на вашия клъстер, но на цялото ниво от локален частен облак, и относно аспекта на публичния облак. Всички настройки трябва да се поддържат на управляемо и ясно ниво, така че в случай на аларми и сигнали да е лесно да се коригира и адресира проблема правилно и навреме.
ClusterControl за аварийно възстановяване в хибридна облачна среда
ClusterControl позволява на организацията или компаниите да управляват базата данни с гъвкавост и да намалят цялостната сложност на настройката. ClusterControl предлага отказ, автоматично архивиране, осигурява високодостъпна настройка, балансиране на натоварването и поддържа внедряване на разпределена среда, което улеснява добавянето на възли в публичен облак или частно или локално.
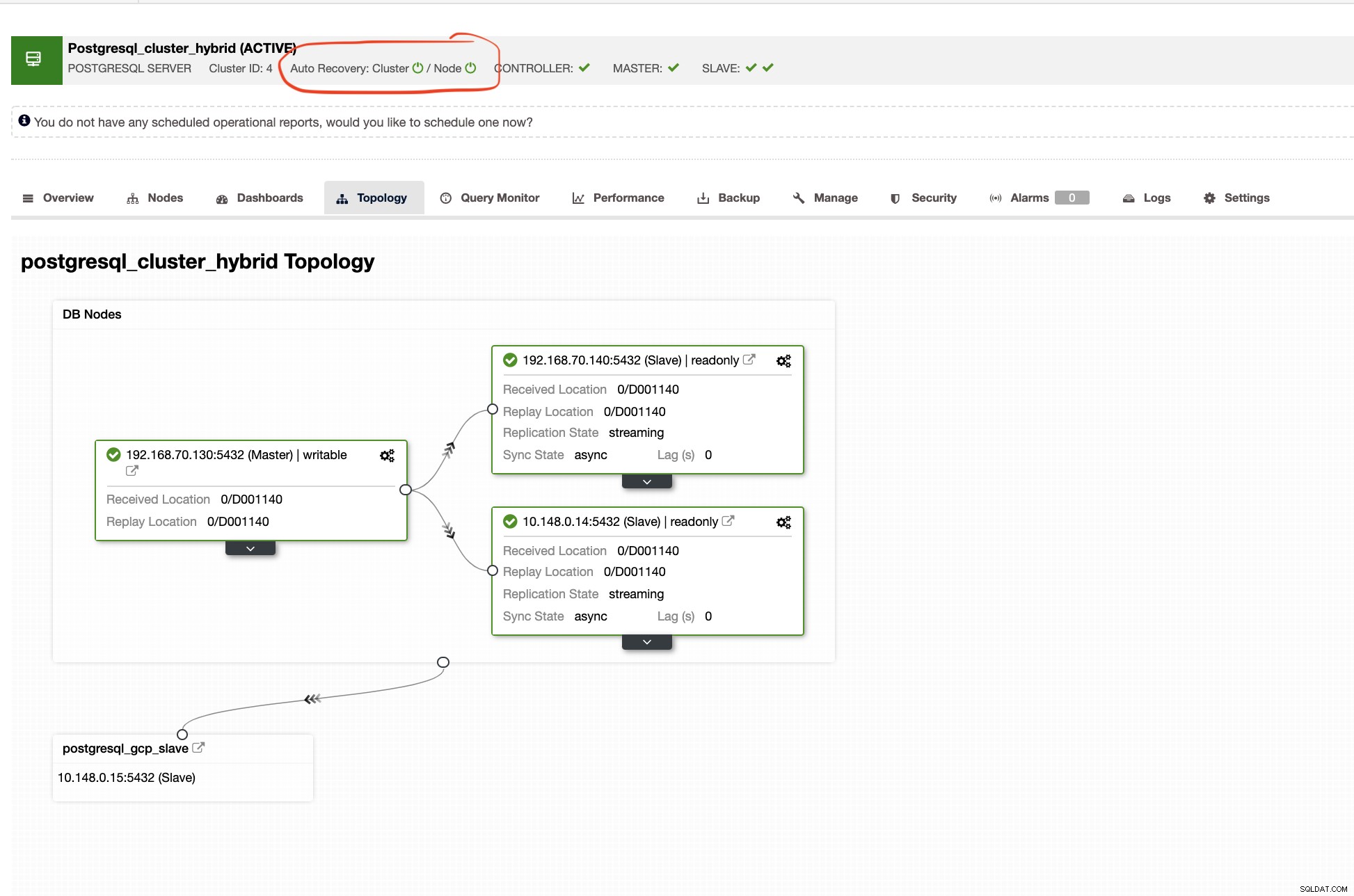
Автоматично възстановяване на ClusterControl
Автоматичното възстановяване на ClusterControl представлява множество механизми за преодоляване при отказ и характеристики за възстановяване, особено когато възелът се повреди или клъстерът премине в влошено състояние. Това може лесно да се направи, както е показано на екранната снимка по-долу:
Архивиране и възстановяване
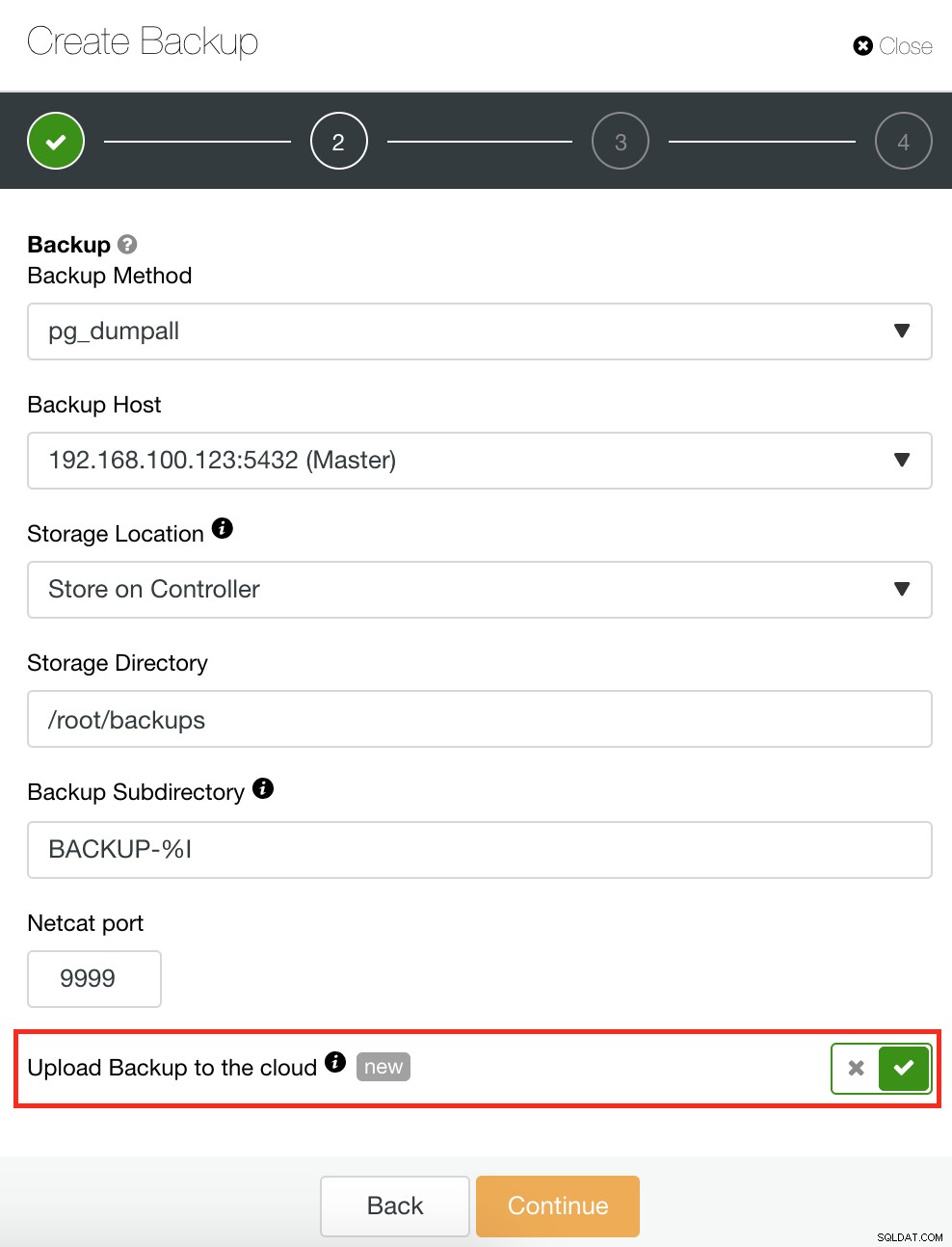
ClusterControl също има функция за архивиране и възстановяване, която ви позволява да управлявате архива си, да създавате резервно копие, да планирате архивиране и да възстановявате резервно копие. Управлението на вашето архивиране е много лесно, а създаването или планирането на архивиране е просто, но предлага и разширени опции. Той също така предлага опции за архивиране в облак, които ви позволяват да имате резервно копие на данни, засилвайки вашите опции за възстановяване след бедствие. Вижте по-долу:
Както е показано по-долу, управлението на архива ви предоставя прост потребителски интерфейс, за да изберете кой архив искате да възстановите, или може да се наложи да го откажете. Архивирането на ClusterControl ви позволява да изберете период на запазване, така че в случай, че имате дълъг списък, някои от тях могат да бъдат изтрити, когато достигне своя период на запазване. 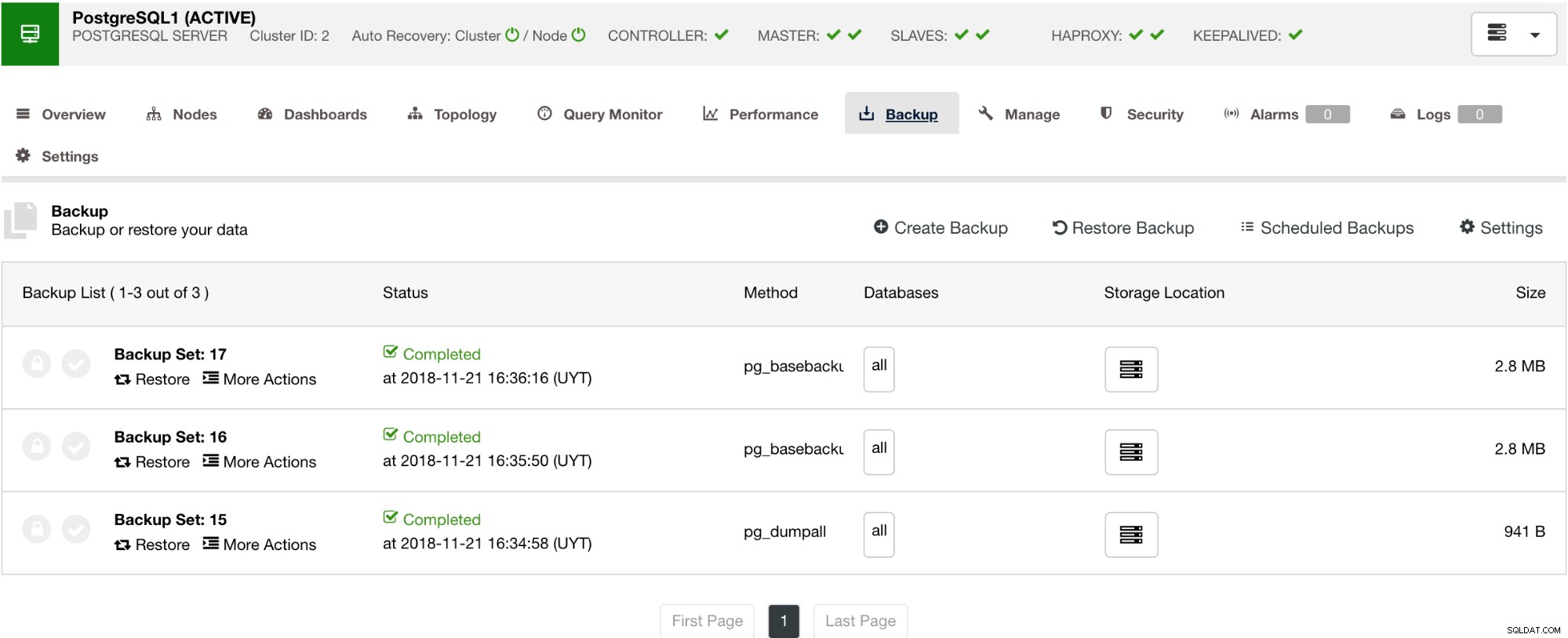
Поддържа механизми за висока наличност (HA) и балансиране на натоварването (LB)
Не е нужно да настройвате ръчно или дори да проучвате някои начини за добавяне на висока наличност във вашия PostgreSQL клъстер. Има лесен и удобен начин да свършите работата с ClusterControl. Ако можете да видите примерната екранна снимка, тя има настройка на HAProxy и Keepalived. Вижте екранната снимка по-долу:
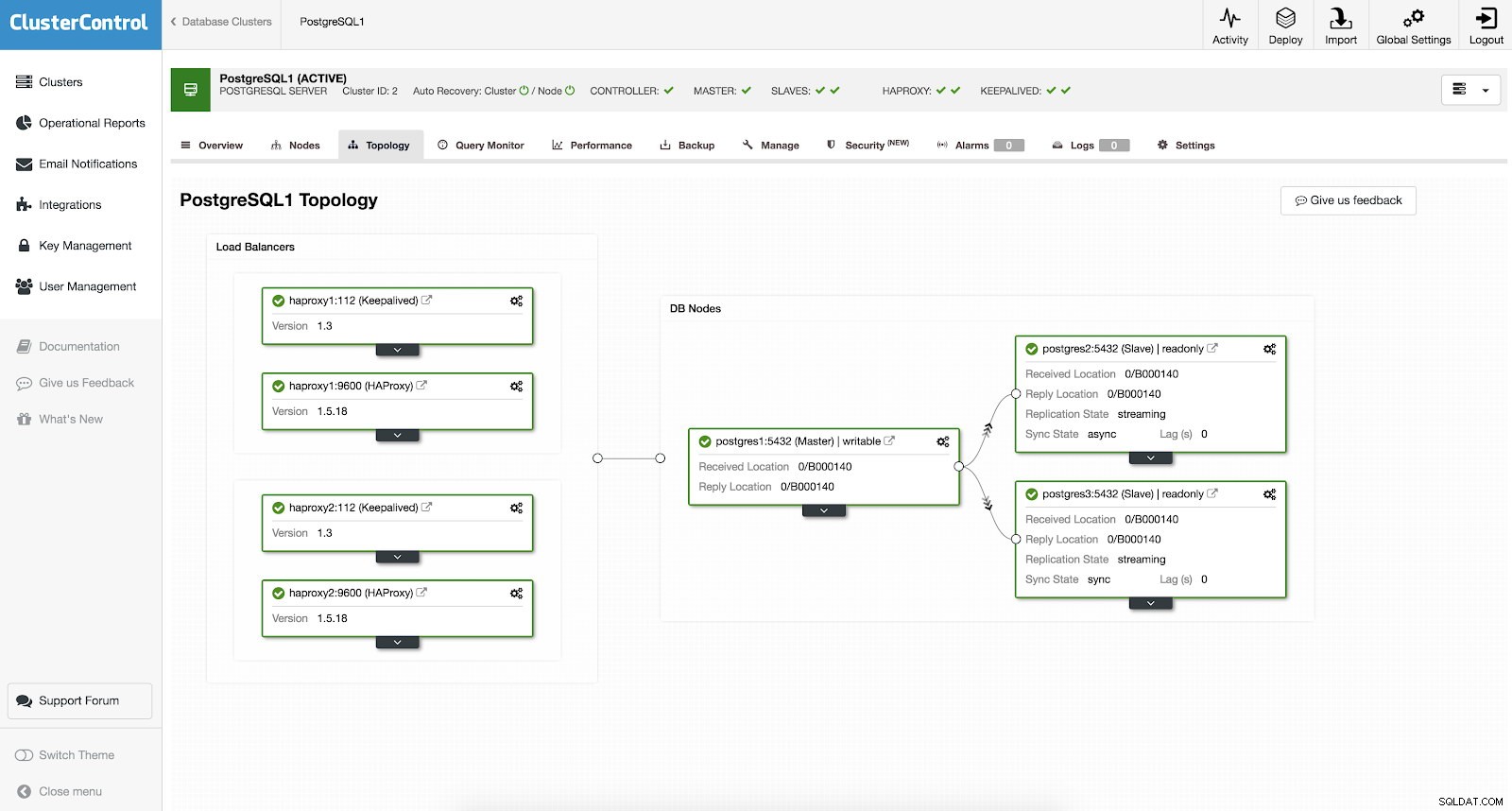
Настройването на висока наличност с ClusterControl може да стане, като преминете през
Поддържа разпределена среда
Ако искате да имате равномерно разпределение от локален или частен облак към публичен облак, ClusterControl също поддържа внедряване в облак. Но за PostgreSQL клъстер и планирате да имате вторичен подчинен, намиращ се в различен облак, можете да създадете подчинен клъстер, както е показано по-долу,
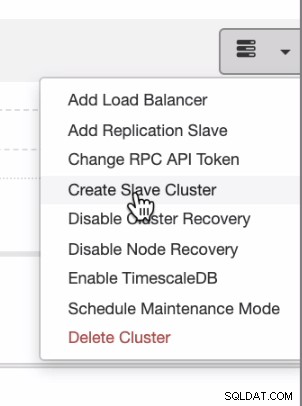
и можете да стигнете с крайния резултат, както е показано по-долу,

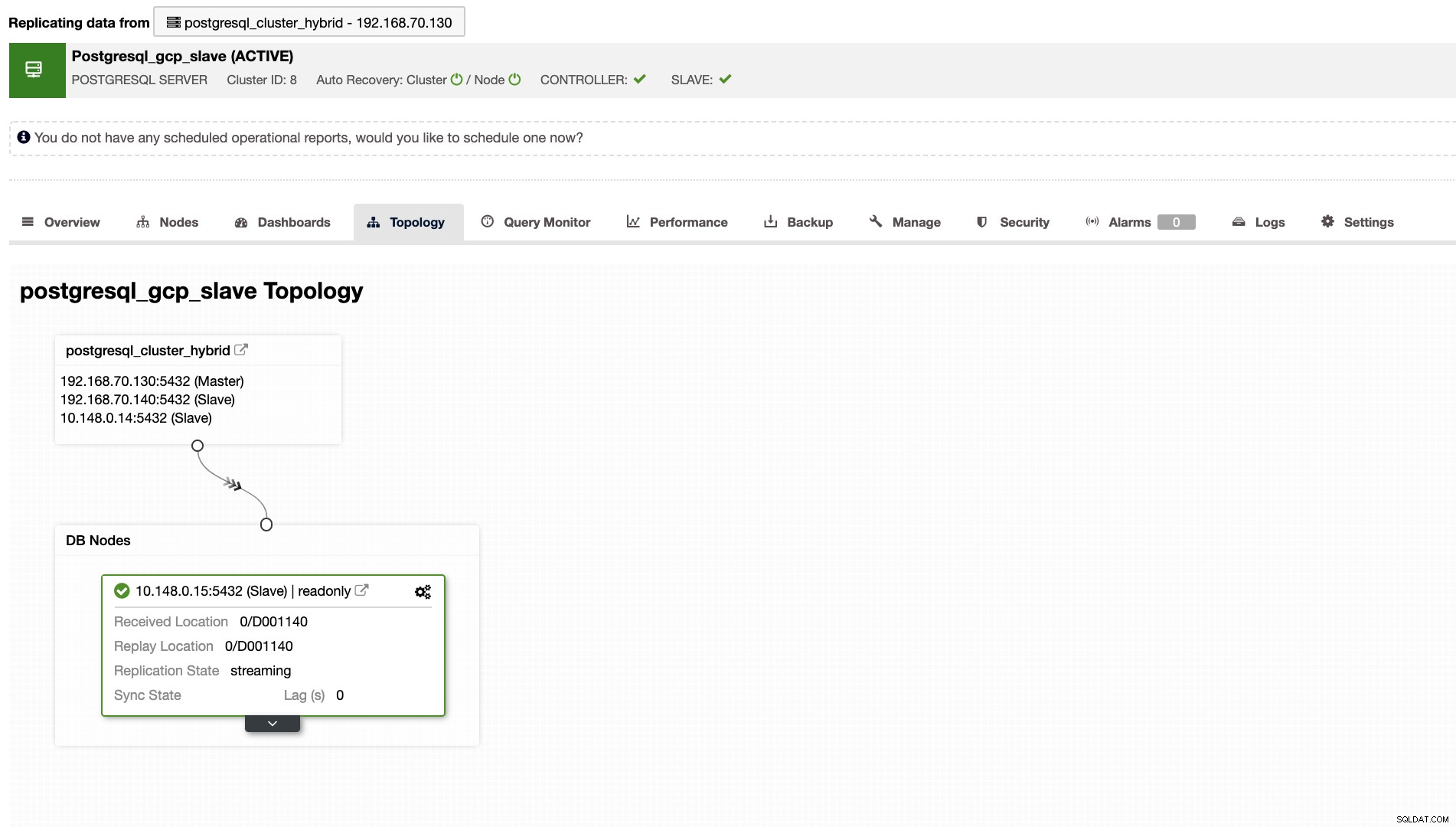
ClusterControl също така ще ви покаже правилната топология на вашия клъстер винаги, когато имате настройка на хибридна облачна среда. Вижте следното по-долу,
Като има предвид, че в подчинения клъстер топологията ще показва своето дърво на произход, разкриващо неговия господар. Подчинението тук се показва, тъй като се намира в отделна мрежа, разположена предимно в Google Cloud, докато главният е на премиум.
Заключение
Приемливо е да се признае, че настройката на хибриден облак, особено с PostgreSQL клъстер, добавя сложност. Трябва да разполагате с подходящия инструмент с налични опции, за да поддържате планирането ви за възстановяване след бедствие. Те са много важни, за да спасите и избегнете вашия бизнес от потенциална катастрофа от финансови щети и загуба на доверие на клиентите. Инвестирайте в правилните инструменти и умения на вашата технология и ще спасите бизнеса си от отрицателно въздействие.