PostgreSQL е страхотен проект и се развива с невероятна скорост. Ще се съсредоточим върху развитието на възможностите за отказоустойчивост в PostgreSQL във всичките му версии с поредица от публикации в блога. Това е втората публикация от поредицата и ще говорим за репликацията и нейното значение за отказоустойчивостта и надеждността на PostgreSQL.
Ако искате да наблюдавате напредъка на еволюцията от самото начало, моля, проверете първата публикация в блога от поредицата:Еволюция на отказоустойчивостта в PostgreSQL
Репликация на PostgreSQL
Репликация на база данни е терминът, който използваме, за да опишем технологията, използвана за поддържане на копие на набор от данни на дистанционно система. Поддържането на надеждно копие на работеща система е една от най-големите притеснения на излишъка и всички ние харесваме поддържани, лесни за използване и стабилни копия на нашите данни.
Нека разгледаме основната архитектура. Обикновено отделните сървъри на база данни се наричат възли . Цялата група сървъри на бази данни, участващи в репликацията, е известна като клъстер . Сървър на база данни, който позволява на потребителя да прави промени, е известен като главен или основен , или може да бъде описан като източник на промени. Сървър на база данни, който само позволява достъп само за четене, известен като горещ режим на готовност . (Терминът за горещ режим на готовност е обяснен подробно под заглавието Режими на готовност. )
Ключовият аспект на репликацията е, че промените в данните се улавят на главен обект и след това се прехвърлят към други възли. В някои случаи възелът може да изпраща промени в данните към други възли, което е процес, известен като каскадиране илиреле . По този начин главният е изпращащ възел, но не всички изпращащи възли трябва да бъдат главни. Репликацията често се категоризира по това дали е разрешено повече от един главен възел, в който случай ще бъде известно като многостранна репликация .
Нека видим как PostgreSQL се справя с репликацията с течение на времето и какво е състоянието на техниката за толерантност към грешки според условията на репликация.
История на репликация на PostgreSQL
Исторически (около 2000-2005 г.) Postgres е концентриран само в толерантност/възстановяване на грешки в един възел, което се постига най-вече чрез WAL, регистър на транзакциите. Толерантността на грешки се обработва частично от MVCC (система за едновременно съгласуване с няколко версии), но това е основно оптимизация.
Регистрирането с предварителна запис беше и все още е най-големият метод за толерантност към грешки в PostgreSQL. По принцип, просто имате WAL файлове, където пишете всичко и можете да се възстановите от гледна точка на неуспех, като ги възпроизвеждате отново. Това беше достатъчно за архитектури с един възел и репликацията се счита за най-доброто решение за постигане на отказоустойчивост с множество възли.
Общността на Postgres е вярвала дълго време, че репликацията е нещо, което Postgres не трябва да предоставя и трябва да се обработва от външни инструменти, ето защо инструменти като Slony и Londiste започнаха да съществуват. (Ще разгледаме базирани на тригер решения за репликация в следващите публикации в блога от поредицата.)
В крайна сметка стана ясно, че една толерантност към сървъра не е достатъчна и повече хора поискаха правилна отказоустойчивост на хардуера и правилен начин на превключване, нещо вградено в Postgres. Това е моментът, когато физическото (тогава физическото поточно предаване) репликация оживява.
Ще преминем през всички методи за репликация по-късно в публикацията, но нека видим хронологичните събития от историята на репликацията на PostgreSQL по основни версии:
- PostgreSQL 7.x (~2000)
- Репликацията не трябва да е част от основния Postgres
- Londiste – Slony (логическа репликация, базирана на тригер)
- PostgreSQL 8.0 (2005)
- Възстановяване в момента (WAL)
- PostgreSQL 9.0 (2010)
- Поточно репликация (физическа)
- PostgreSQL 9.4 (2014)
- Логическо декодиране (извличане на набор от промени)
Физическа репликация
PostgreSQL реши основната нужда от репликация с това, което правят повечето релационни бази данни; взе WAL и направи възможно изпращането му по мрежата. След това тези WAL файлове се прилагат в отделен екземпляр на Postgres, който работи само за четене.
Екземплярът в режим на готовност само за четене просто прилага промените (от WAL) и единствените операции за запис идват отново от същия дневник на WAL. Това е основно начинът за поточно репликация механизъм работи. В началото репликацията първоначално доставяше всички файлове –доставка на регистрационни файлове- , но по-късно се превърна в стрийминг.
При изпращането на регистрационни файлове изпращахме цели файлове чрез archive_command . Там логиката е доста проста:просто изпращате архива илога до някъде – като целия 16MB WAL файл – и след това прилагате до някъде и след това извличате следващия иприложи онзи и върви така. По-късно се превърна в стрийминг през мрежа чрез използване на libpq протокол в PostgreSQL версия 9.0.
Съществуващата репликация е по-известна като Репликация на физическо поточно предаване тъй като предаваме поредица от физически промени от един възел в друг. Това означава, че когато вмъкнем ред в таблица, ние генерираме записи за промяна за вложката плюс всички индексни записи .
Когато VACUUM таблица, ние също генерираме записи за промени.
Освен това репликацията на физическото поточно предаване записва всички промени на ниво байт/блок , което прави много трудно да се направи нещо друго, освен просто да се преиграе всичко
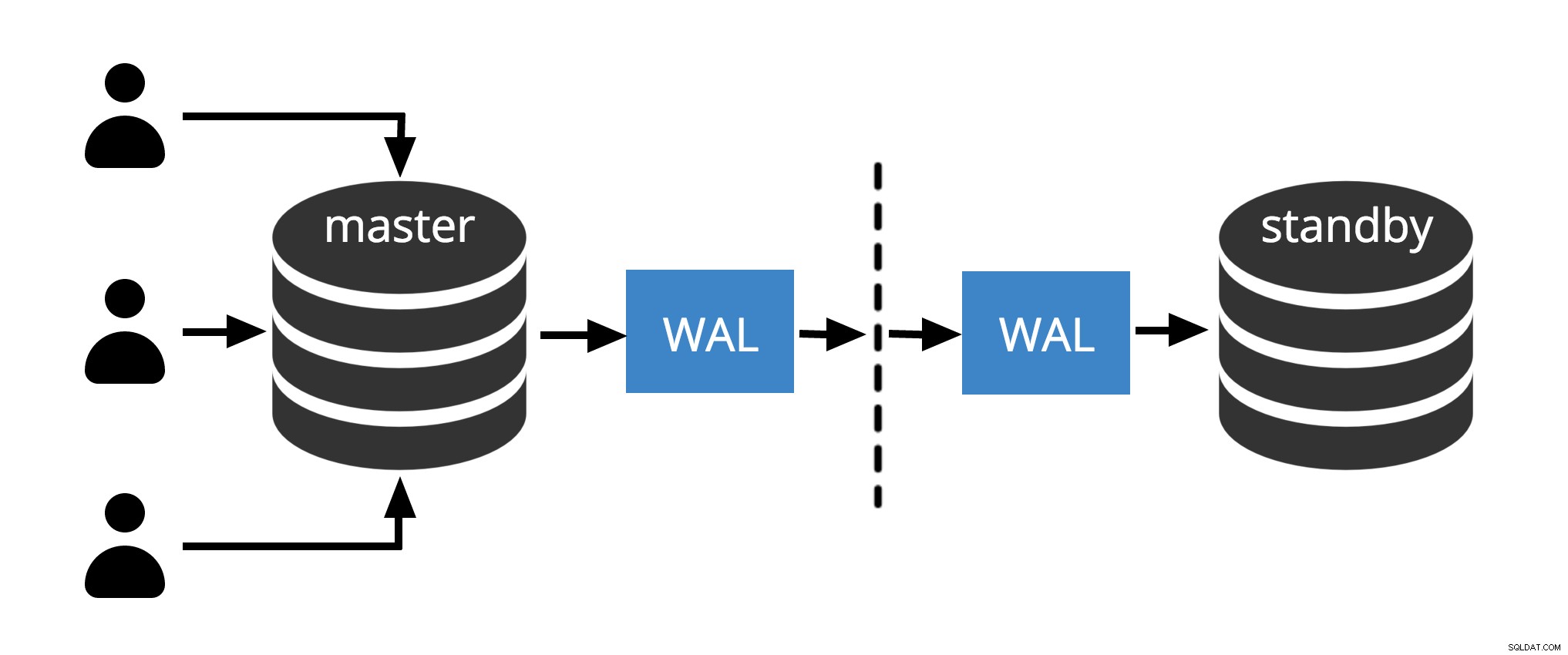
Фиг.1 Физическа репликация
Фиг.1 показва как работи физическата репликация само с два възела. Клиентът изпълнява заявки на главния възел, промените се записват в регистър на транзакциите (WAL) и се копират по мрежата в WAL на възел в режим на готовност. След това процесът на възстановяване на възела в режим на готовност чете промените от WAL и ги прилага към файловете с данни точно както по време на възстановяване при срив. Ако режимът на готовност е вгорещ режим в режим, клиентите могат да издават заявки само за четене на възела, докато това се случва.
Забележка: Физическата репликация просто се отнася за изпращане на WAL файлове през мрежа от главен към резервен възел. Файловете могат да се изпращат по различни протоколи като scp, rsync, ftp... Разликата между физическа репликация и Репликация на физическо поточно предаване is Streaming Replication използва вътрешен протокол за изпращане на WAL файлове (подавател иприемни процеси )
Режими на готовност
Множество възли осигуряват висока наличност. Поради тази причина съвременните архитектури обикновено имат резервни възли. Има различни режими за възли в режим на готовност (топъл и горещ режим на готовност). Списъкът по-долу обяснява основните разлики между различните режими на готовност и също така показва случая на архитектурата с няколко главни.
Топъл режим на готовност
Може да се активира незабавно, но не може да извършва полезна работа, докато не се активира. Ако непрекъснато подаваме поредицата от WAL файлове към друга машина, която е била заредена със същия основен архивен файл, имаме система за топъл режим на готовност:във всеки един момент можем да изведем втората машина и тя ще има почти текущо копие на базата данни. Топъл режим на готовност не позволява заявки само за четене, Фиг.2 просто представя този факт.
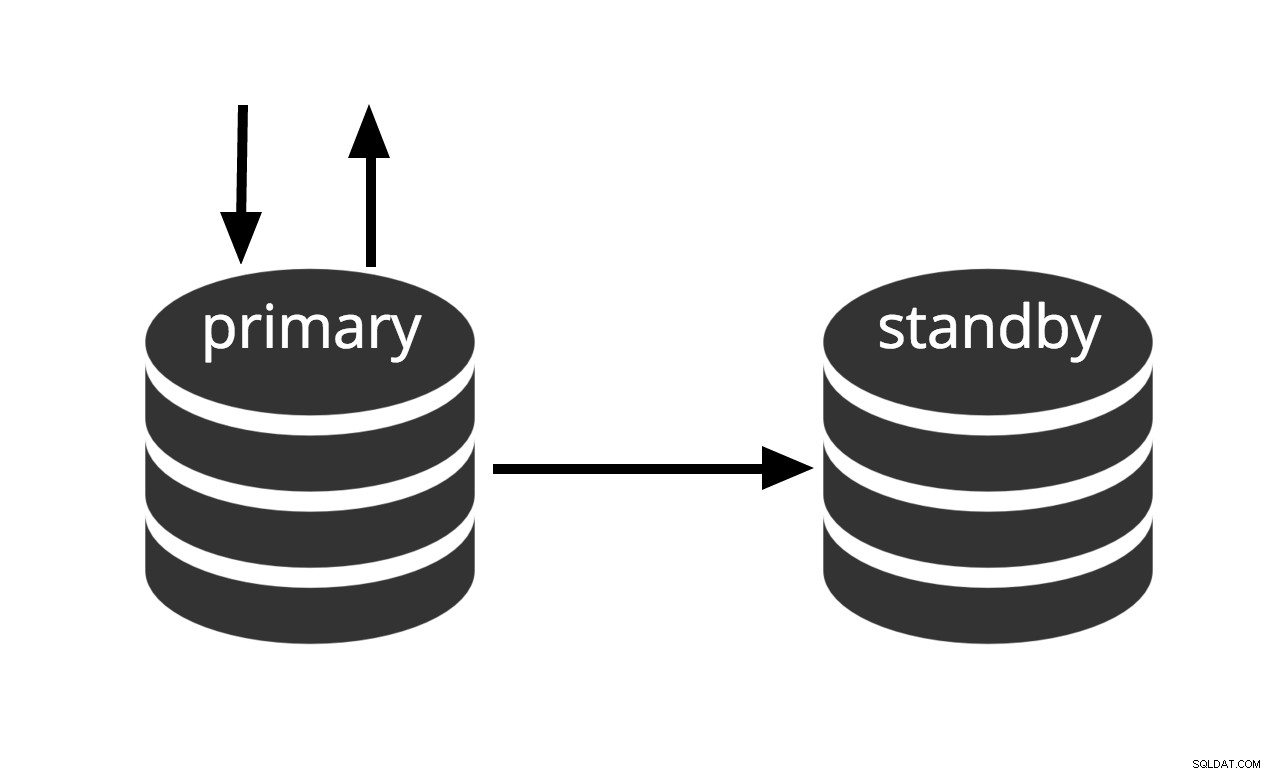
Фиг.2 Топъл режим на готовност
Ефективността на възстановяване на топъл режим на готовност е достатъчно добра, така че режимът на готовност обикновено ще бъде само на няколко минути от пълната наличност, след като бъде активиран. В резултат на това това се нарича конфигурация в топъл режим на готовност, която предлага висока наличност.
Горещ режим на готовност
Горещ режим на готовност е терминът, използван за описване на възможността за свързване със сървъра и изпълнение на заявки само за четене, докато сървърът е в режим на възстановяване на архив или в режим на готовност. Това е полезно както за целите на репликацията, така и за възстановяване на резервно копие до желано състояние с голяма точност.
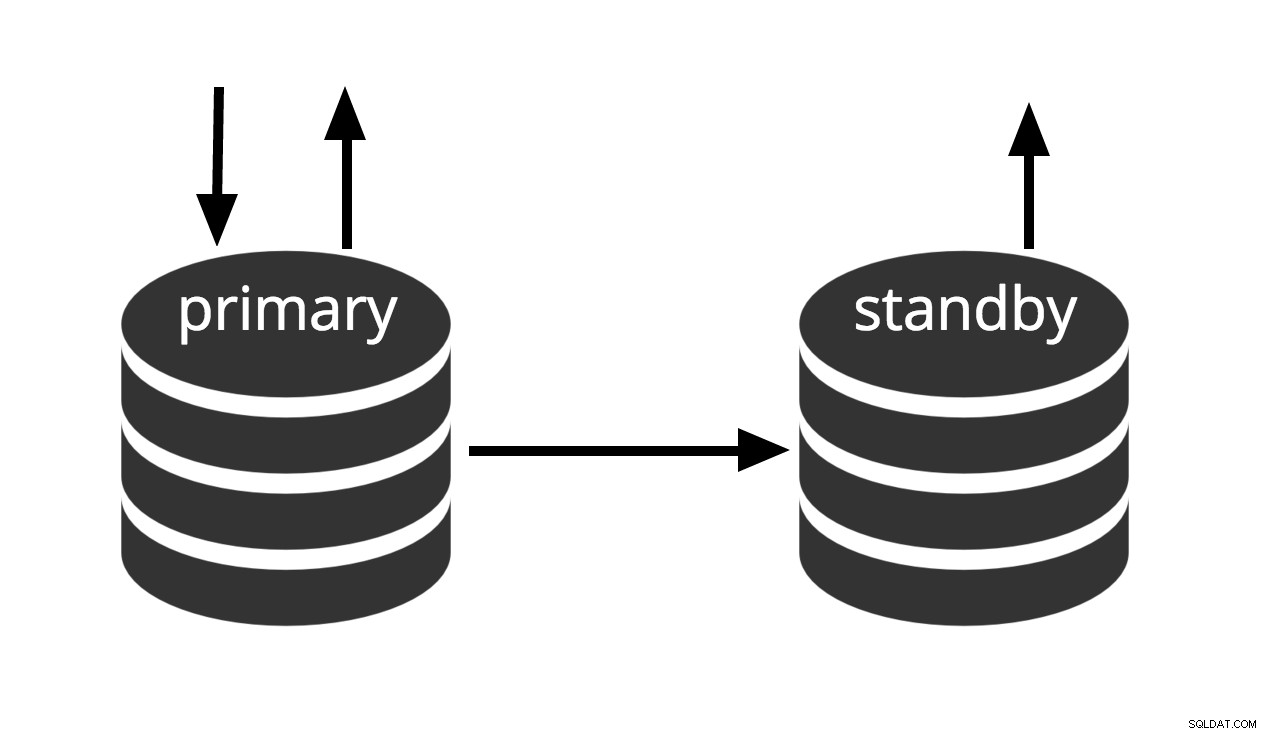 Фиг.3 Горещ режим на готовност
Фиг.3 Горещ режим на готовност
Терминът горещ режим на готовност също се отнася до способността на сървъра да премине от възстановяване към нормална работа, докато потребителите продължават да изпълняват заявки и/или поддържат връзките си отворени. Фиг.3 показва, че режимът на готовност позволява заявки само за четене.
Multi-Master
Всички възли могат да извършват работа за четене/запис. (Ще разгледаме архитектурите с няколко главни в следващите публикации в блога от поредицата.)
Параметър за ниво на WAL
Има връзка между настройката на wal_level параметър във файла postgresql.conf и за какво е подходяща тази настройка. Създадох таблица за показване на връзката за PostgreSQL версия 9.6.

Отказ и превключване
При репликация с един главен, ако главният умре, един от резервните трябва да заеме неговото място (промоция ). В противен случай няма да можем да приемем нови транзакции за писане. По този начин обозначенията на термините, master и standby, са просто роли, които всеки възел може да поеме в даден момент. За да преместим главната роля на друг възел, изпълняваме процедура, наречена Превключване .
Ако главният умре и не се възстанови, тогава по-тежката промяна на ролята е известна като Failover . В много отношения те могат да бъдат сходни, но е полезно да се използват различни термини за всяко събитие. (Познаването на условията за отказ и превключване ще ни помогне да разберем проблемите с времевата линия в следващата публикация в блога.)
Заключение
В тази публикация в блога обсъдихме репликацията на PostgreSQL и нейното значение за осигуряване на отказоустойчивост и надеждност. Разгледахме физическото поточно репликация и говорихме за режимите на готовност за PostgreSQL. Споменахме отказ и превключване. Ще продължим със сроковете на PostgreSQL в следващата публикация в блога.
Препратки
PostgreSQL документация
Логическа репликация в PostgreSQL 5432... Презентация на MeetUs от Petr Jelinek
Готварска книга за администриране на PostgreSQL 9 – второ издание