Използването на среда с множество облаци или много центрове за данни е полезно за гео-разпределени топологии или дори за план за възстановяване при бедствия и всъщност става все по-популярно в днешно време, поради което концепцията за разделен мозък също става все по-важно, тъй като рискът от възникването му се увеличава при този вид сценарии. Трябва да предотвратите разделяне на мозъка, за да избегнете потенциална загуба на данни или несъответствие на данните, което може да бъде голям проблем за бизнеса.
В този блог ще видим какво е разделен мозък и как ClusterControl може да ви помогне да избегнете този важен проблем.
Какво е Split-Brain?
В света на PostgreSQL разделянето на мозъка възниква, когато повече от един първичен възел е наличен едновременно (без инструмент на трета страна, който да има среда с няколко главни), което позволява на приложението да пише в двата възела. В този случай ще имате различна информация за всеки възел, което генерира несъответствие на данните в клъстера. Коригирането на този проблем може да е трудно, тъй като трябва да обедините данни, нещо, което понякога е невъзможно.
PostgreSQL Split-Brain в многооблачна топология
Да предположим, че имате следната многооблачна топология за PostgreSQL (която е доста често срещана топология в днешно време):
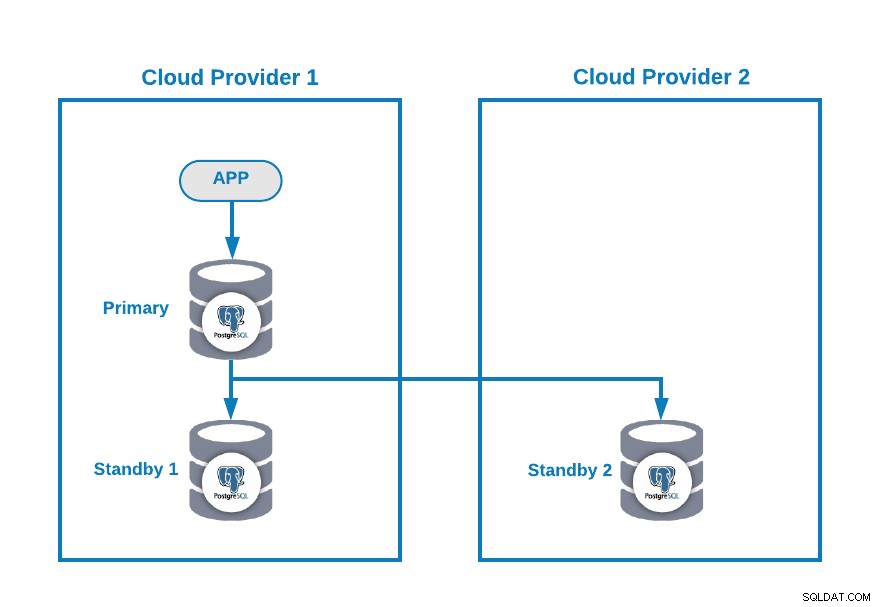
Разбира се, можете да подобрите тази среда, като например добавите Сървър на приложения в Cloud Provider 2, но в този случай нека използваме тази основна конфигурация.
Ако основният ви възел не работи, един от резервните възли трябва да бъде повишен като нов основен и трябва да промените IP адреса във вашето приложение, за да използвате този нов основен възел.
Има различни начини да направите това по автоматичен начин. Например, можете да използвате виртуален IP адрес, присвоен на вашия основен възел, и да го наблюдавате. Ако не успее, популяризирайте един от резервните възли и мигрирайте виртуалния IP адрес към този нов основен възел, така че да не е необходимо да променяте нищо в приложението си и това може да се направи с помощта на собствен скрипт или инструмент.
В момента нямате проблем, но... ако старият ви основен възел се върне, трябва да се уверите, че няма да имате два основни възела в един и същ клъстер едновременно .
Най-често срещаните методи за избягване на тази ситуация са:
- STONITH:Застреляйте другия възел в главата.
- SMITH:Застреля се в главата.
PostgreSQL не предоставя никакъв начин за автоматизиране на този процес. Трябва да го направите сами.
Как да избегнем разделянето на мозъка в PostgreSQL с ClusterControl
Сега нека видим как ClusterControl може да ви помогне с тази задача.
Първо, можете да го използвате за внедряване или импортиране на вашата PostgreSQL Multi-Cloud среда по лесен начин, както можете да видите в тази публикация в блога.
След това можете да подобрите топологията си, като добавите Load Balancer (HAProxy), което можете да направите и с помощта на ClusterControl след този блог. Така че ще имате нещо подобно:
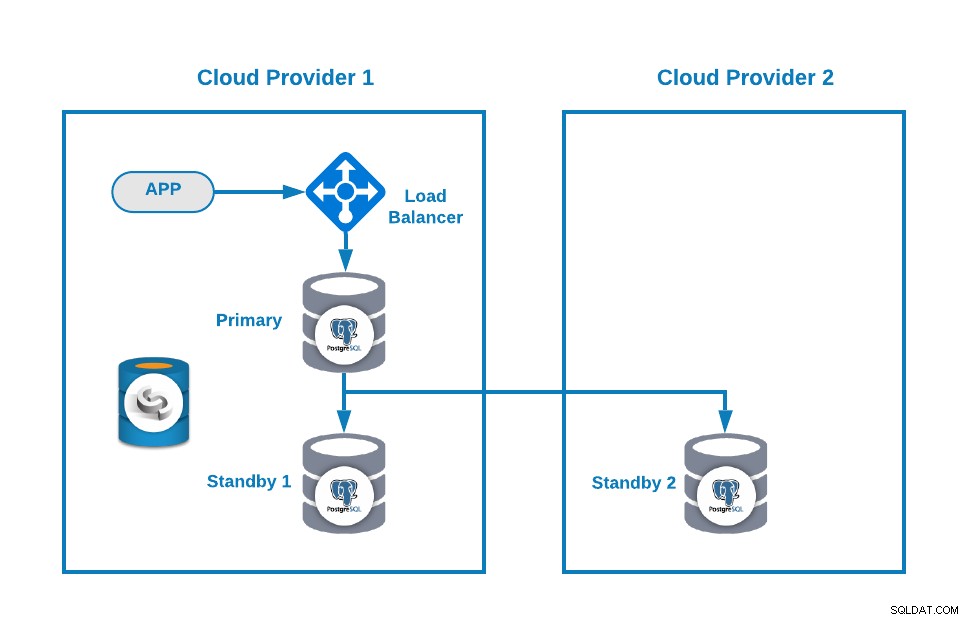
ClusterControl има функция за автоматично отказване, която открива главни грешки и насърчава готовност възел с най-актуалните данни като нов основен. Освен това не успява да се репликира над останалите възли в режим на готовност от новия първичен възел.
HAProxy се конфигурира от ClusterControl с два различни порта по подразбиране, един за четене-запис и един само за четене. В порта за четене и запис имате основния си възел като онлайн, а останалите си възли като офлайн, а в порта само за четене имате както основния, така и резервния възел онлайн. По този начин можете да балансирате трафика за четене между вашите възли, но се уверявате, че в момента на писане ще се използва портът за четене-запис, като се записва в основния възел, който е сървърът, който е онлайн.
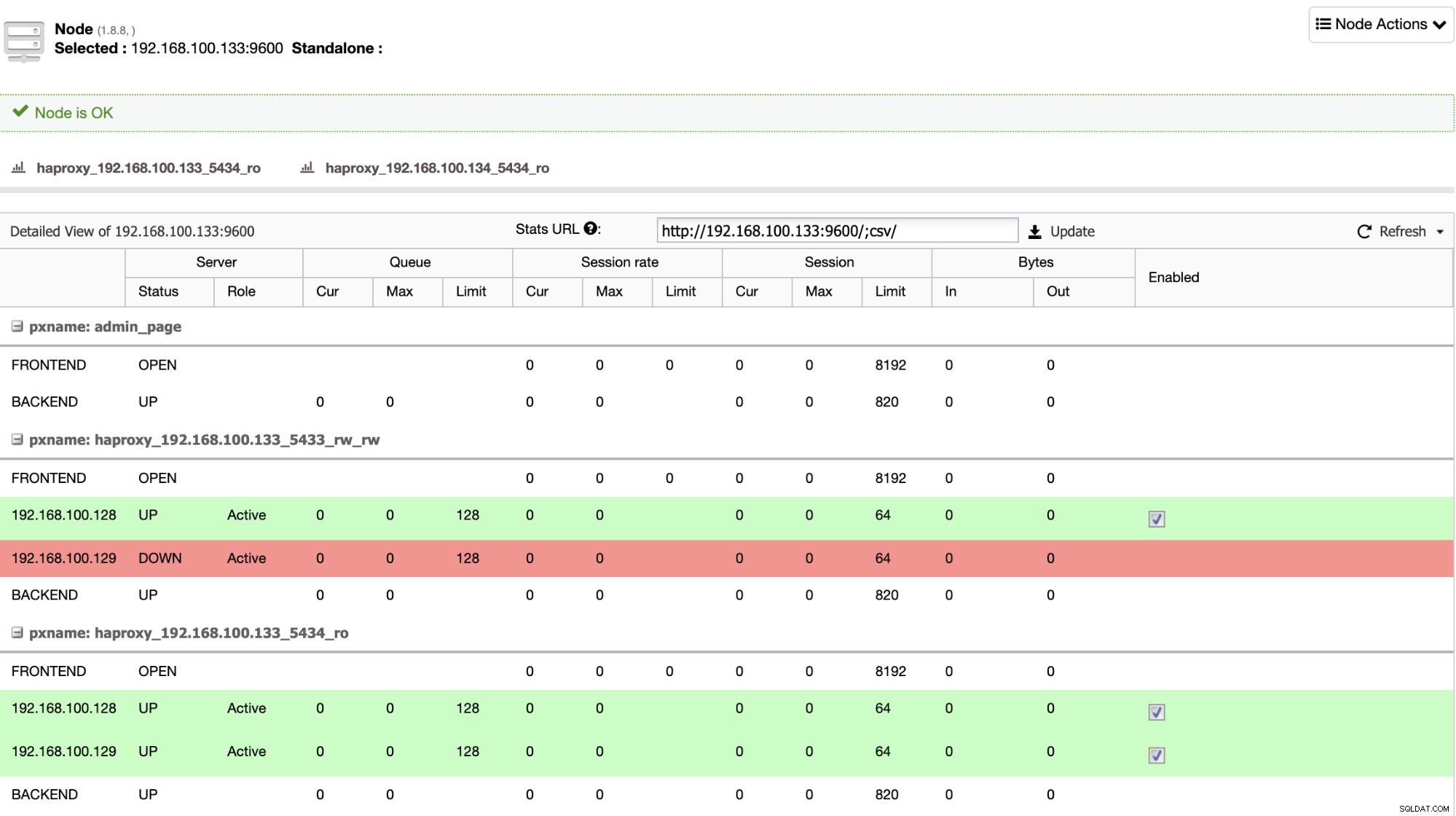
Когато HAProxy открие, че един от вашите възли, първичен или в режим на готовност, е не е достъпен, автоматично го маркира като офлайн и не го взема предвид за изпращане на трафик към него. Тази проверка се извършва от скриптове за проверка на състоянието, които са конфигурирани от ClusterControl по време на внедряването. Те проверяват дали екземплярите са актуални, дали са в процес на възстановяване или са само за четене.
Ако старият ви първичен възел се върне, ClusterControl също ще избегне стартирането му, за да предотврати потенциално разделяне на мозъка в случай, че имате директна връзка, която не използва Load Balancer, но можете да го добавите към клъстера като възел в режим на готовност по автоматичен или ръчен начин с помощта на ClusterControl UI или CLI, след което можете да го повишите така, че да има същата топология, която сте използвали преди проблема.
Заключение
При включена опция „Автоматично възстановяване“, ClusterControl ще извърши това автоматично преминаване при отказ, както и ще ви уведоми за проблема. По този начин вашите системи могат да се възстановят за секунди без ваша намеса и ще избегнете разделяне на мозъка в PostgreSQL Multi-Cloud среда.
Можете също така да подобрите вашата среда с висока достъпност, като добавите още възли на ClusterControl, като използвате функцията CMON HA, описана в този блог.



