Многооблачна среда е добър вариант за план за възстановяване след бедствие (DRP), но може да е отнемаща време задача, тъй като трябва да конфигурирате свързаността между различните доставчици на облак и ще след това трябва да разположите и управлявате своя клъстер от база данни на две различни места.
В този блог ще покажем как да извършите внедряване в множество облаци за PostgreSQL в два от най-популярните доставчици на облак в момента, AWS и Google Cloud. За тази задача ще използваме някои от функциите, които ClusterControl може да ви предложи, като мащабиране и репликация от клъстер към клъстер.
Ще приемем, че имате стартирана инсталация на ClusterControl и вече сте създали два различни акаунта на доставчик на облак.
Подготовка на вашата облачна среда
Първо, трябва да създадете своята среда във вашия основен доставчик на облак. В този случай ще използваме AWS с 2 възела на PostgreSQL:

Уверете се, че имате разрешен SSH и PostgreSQL трафик от вашия сървър ClusterControl от редактиране на вашата група за сигурност:

След това отидете на вторичния облачен доставчик и създайте поне една виртуална машина това ще бъде подчинения възел. Ще използваме Google Cloud Platform с 1 възел PostgreSQL.

И отново се уверете, че разрешавате SSH и PostgreSQL трафик от вашия ClusterControl сървър:

В този случай ние разрешаваме трафика без никакви ограничения за източника , но това е само пример и не се препоръчва в реалния живот.
Разгръщане на PostgreSQL клъстер в облака
Ще използваме ClusterControl за тази задача, така че предполагаме, че сте го инсталирали.
Отидете на вашия сървър ClusterControl и изберете опцията „Разгръщане“. Ако вече имате работещ екземпляр на PostgreSQL, тогава трябва да изберете „Импортиране на съществуващ сървър/база данни“.
Когато избирате PostgreSQL, трябва да посочите потребител, ключ или парола и порт за да се свържете чрез SSH към вашите PostgreSQL възли. Освен това имате нужда от името за вашия нов клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
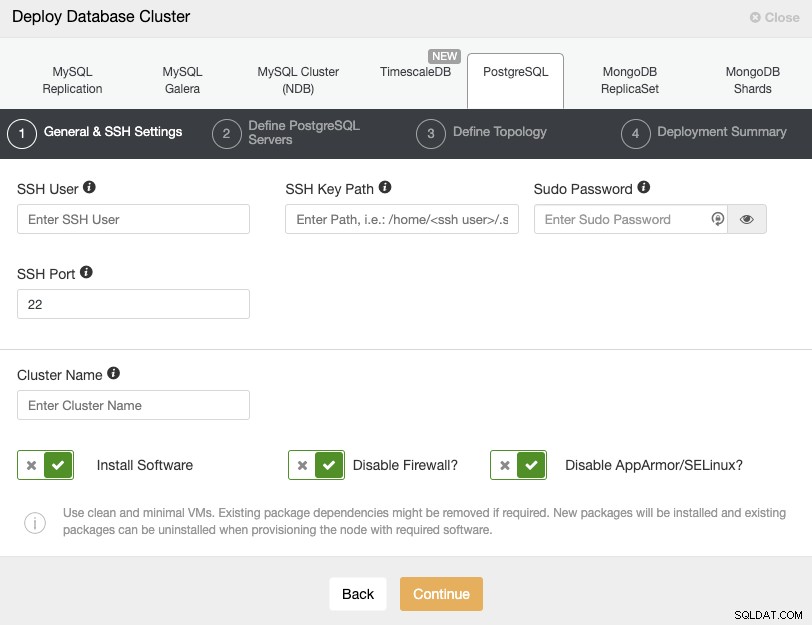
Моля, проверете потребителските изисквания на ClusterControl за повече информация относно тази стъпка.
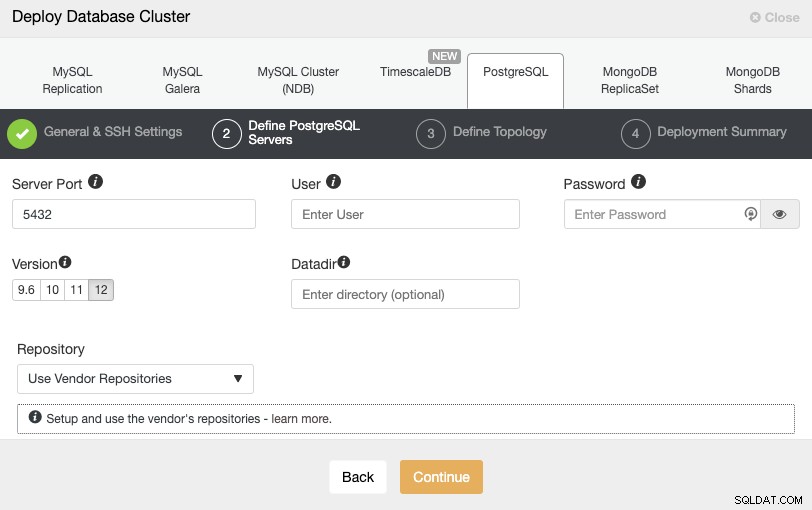
След като настроите информацията за SSH достъп, трябва да дефинирате потребителя на базата данни, версия и datadir (по избор). Можете също да посочите кое хранилище да използвате. В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадете.
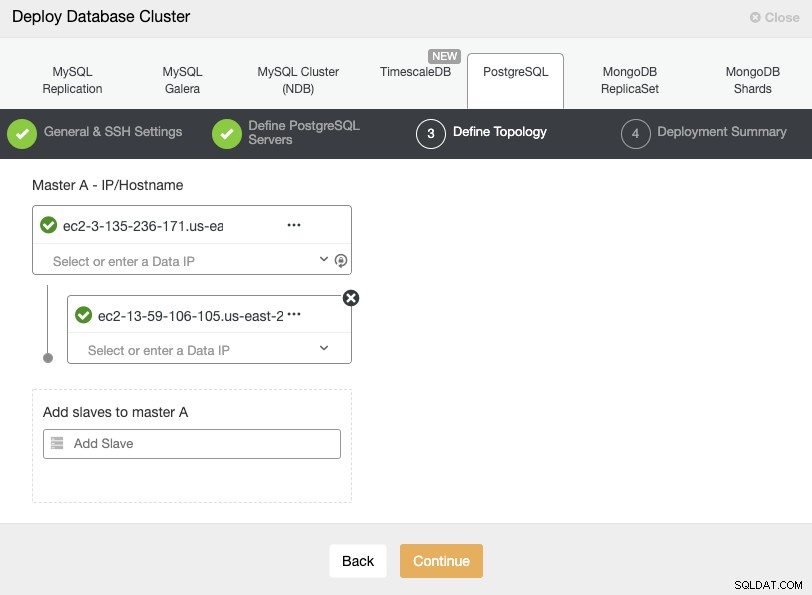
Когато добавяте вашите сървъри, можете да въведете IP или име на хост. В тази стъпка можете също да добавите възела, поставен във вторичния облачен доставчик, тъй като ClusterControl няма никакви ограничения относно мрежата, която да се използва, но за да стане по-ясно, ще го добавим в следващия раздел. Единственото изискване тук е да имате SSH достъп до възела.
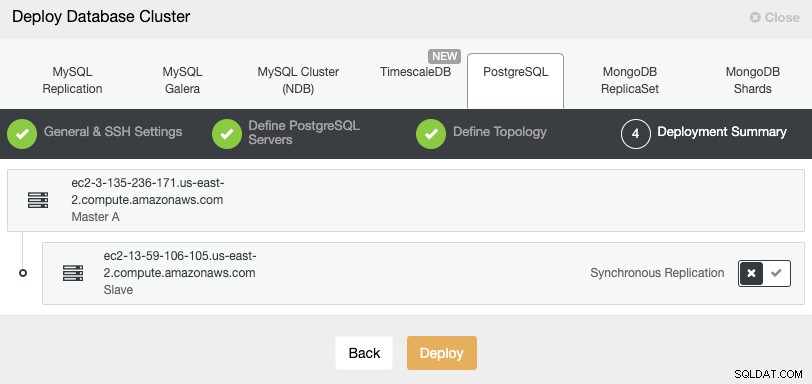
В последната стъпка можете да изберете дали репликацията ви ще бъде синхронна или Асинхронно.
В случай, че добавяте своя отдалечен възел тук, важно е да използвате асинхронна репликация, ако не, клъстерът ви може да бъде засегнат от забавянето или проблемите с мрежата.
Можете да наблюдавате състоянието на създаване в монитора на активността на ClusterControl.
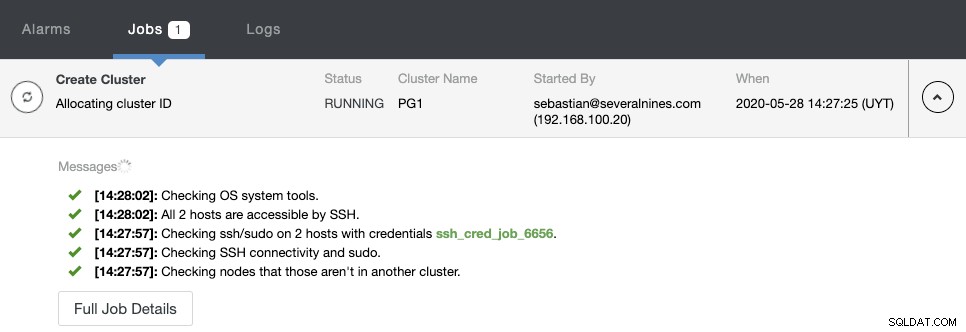
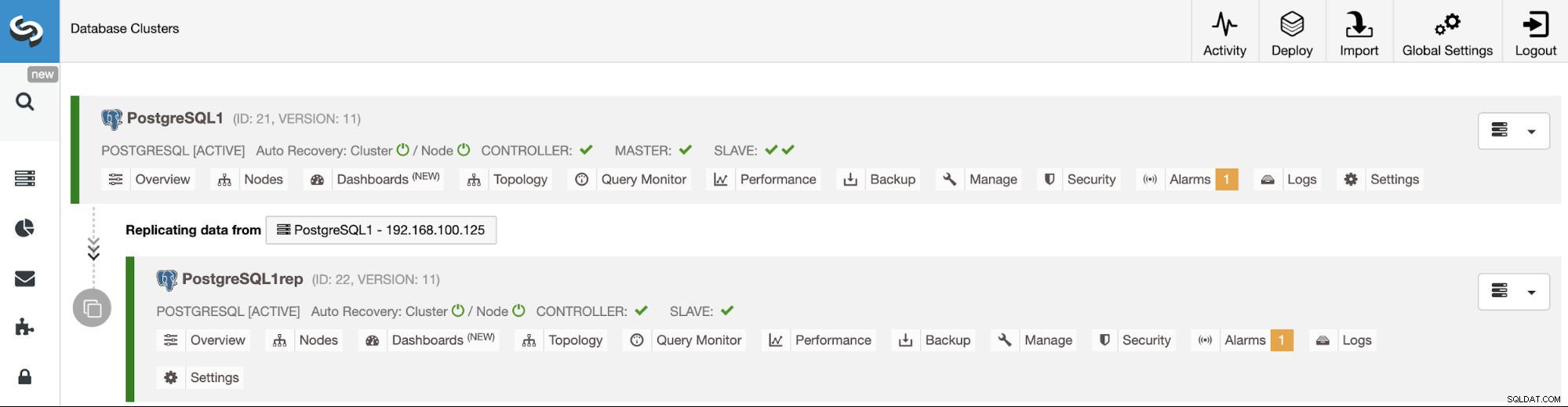
След като задачата приключи, можете да видите своя нов PostgreSQL клъстер в главен екран на ClusterControl.

Добавяне на отдалечен подчинен възел в облака
След като създадете своя клъстер, можете да изпълнявате няколко задачи върху него, като разгръщане/импортиране на балансьор на натоварване или подчинен възел за репликация.
Отидете към действията на клъстера и изберете „Добавяне на подчинен репликация“:
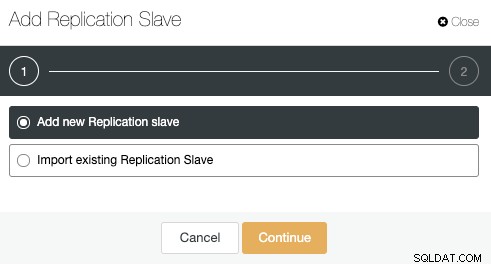
Нека използваме опцията „Добавяне на ново подчинено устройство за репликация“, тъй като предполагаме, че отдалеченият възел е нова инсталация, ако не, вместо това можете да използвате опцията „Импортиране на съществуващ подчинен репликационен модул“.
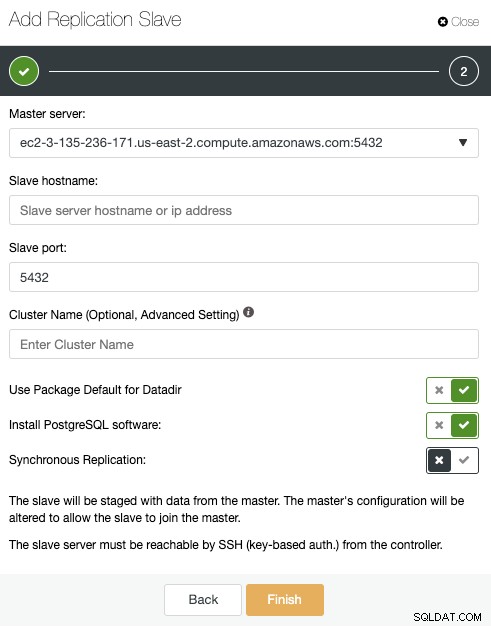
Тук трябва само да изберете вашия главен сървър, въведете IP адреса за вашия нов подчинен сървър и порта на базата данни. След това можете да изберете дали искате ClusterControl да инсталира софтуера и дали подчинението за репликация трябва да бъде синхронно или асинхронно. Отново, ако добавяте възел в различен център за данни, трябва да използвате асинхронна репликация, за да избегнете проблеми, свързани с производителността на мрежата.
По този начин можете да добавяте колкото искате копия и да разпределяте трафика за четене между тях с помощта на балансьор на натоварване, който можете също да внедрите с ClusterControl.
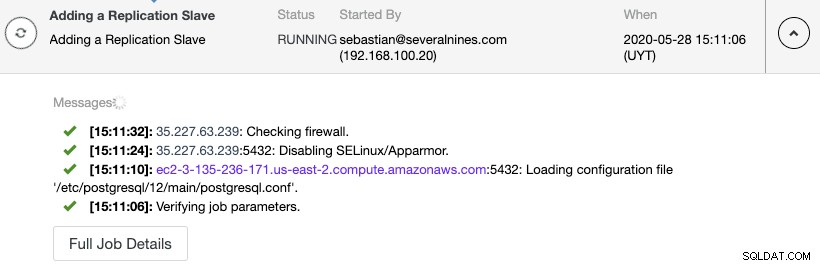
Можете да наблюдавате създаването на подчинен репликация в монитора на активността на ClusterControl.
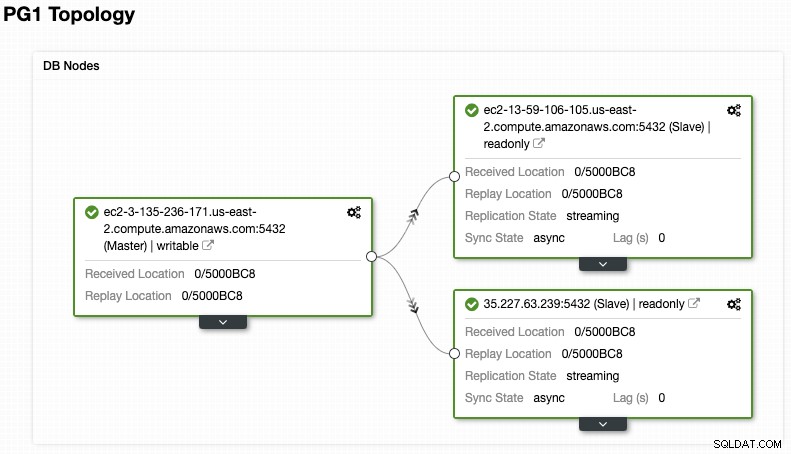
И проверете окончателната си топология в раздела за изглед на топология.
Репликация от клъстер в клъстер в облака
Вместо да използвате опцията „Добавяне на подчинен за репликация“, за да имате многооблачна среда, можете да използвате функцията ClusterControl Cluster-to-Cluster Replication, за да добавите отдалечен клъстер. В момента тази функция има ограничение за PostgreSQL, което ви позволява да имате само един отдалечен възел, така че е доста подобен на предишния начин, но ние работим за премахването на това ограничение скоро в бъдеща версия.
За да създадете нов подчинен клъстер, отидете на ClusterControl -> Изберете Cluster -> Cluster Actions -> Създайте подчинен клъстер.
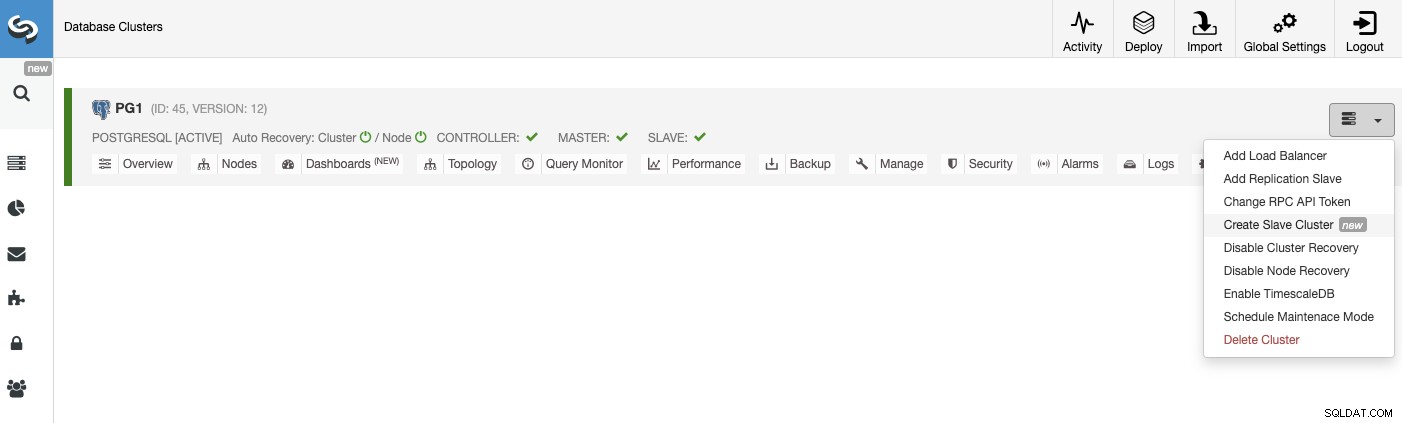
Подчинения клъстер ще бъде създаден чрез поточно предаване на данни от текущия главен клъстер.
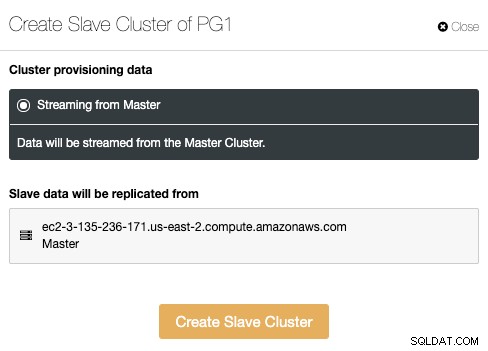
В този раздел трябва да изберете главния възел на текущия клъстер от който данните ще бъдат репликирани.
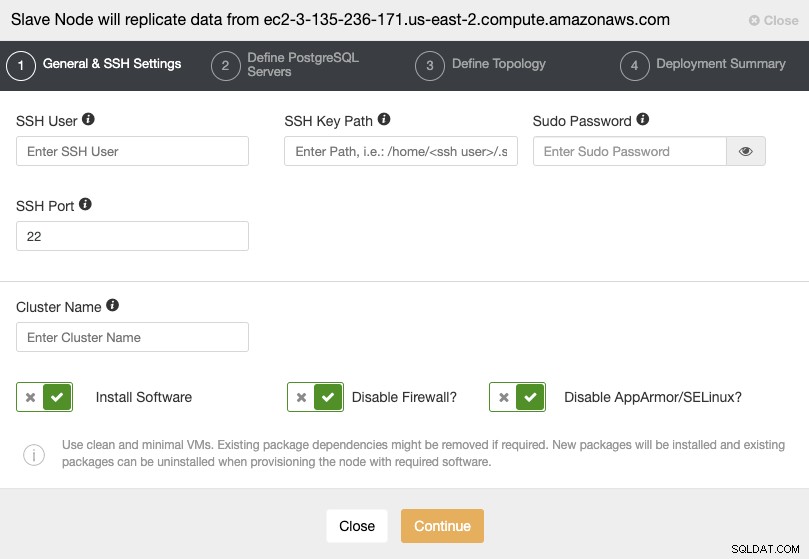
Когато преминете към следващата стъпка, трябва да посочите потребител, ключ или Парола и порт за свързване чрез SSH към вашите сървъри. Освен това имате нужда от име за вашия подчинен клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
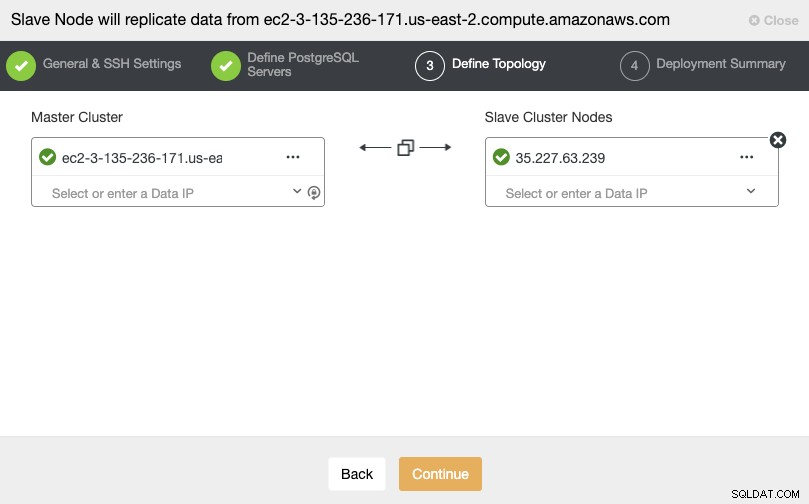
След като настроите информацията за SSH достъп, трябва да дефинирате версията на базата данни, datadir, порт и идентификационни данни на администратора. Тъй като ще използва поточно репликация, уверете се, че използвате същата версия на базата данни и идентификационни данни, използвани в главния клъстер. Можете също да посочите кое хранилище да използвате.
В тази стъпка трябва да добавите сървъра за новия подчинен клъстер . За тази задача можете да въведете както IP адреса, така и името на хоста на възела на базата данни.
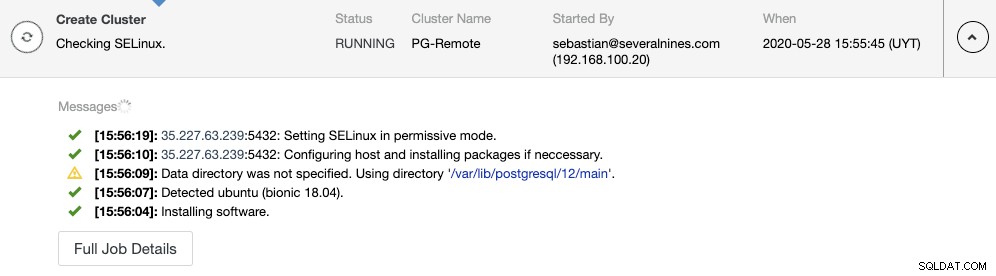
Можете да наблюдавате създаването на подчинен клъстер в монитора на активността на ClusterControl. След като задачата приключи, можете да видите клъстера в главния екран на ClusterControl.
Заключение
Тези функции на ClusterControl ще ви позволят бързо да настроите репликация между различни облачни доставчици за PostgreSQL база данни (и различни технологии) и да управлявате настройката по лесен и удобен начин. Относно комуникацията между доставчиците на облак, от съображения за сигурност, трябва да ограничите трафика само от известни източници, така че само от Cloud Provider 1 до Cloud Provider 2 и обратно.