Поточно репликацията на PostgreSQL е чудесен начин за мащабиране на PostgreSQL клъстери и това добавя висока достъпност към тях. Както при всяка репликация, идеята е, че подчинението е копие на главната и че подчинението непрекъснато се актуализира с промените, случили се на главния, като се използва някакъв механизъм за репликация.
Може да се случи така, че подчинения по някаква причина да излезе от синхрон с главния. Как мога да го върна във веригата за репликация? Как мога да гарантирам, че подчинението отново е в синхрон с главния? Нека да разгледаме тази кратка публикация в блога.
Това, което е много полезно, няма начин да се пише на подчинен, ако е в режим на възстановяване. Можете да го тествате така:
postgres=# SELECT pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
postgres=# CREATE DATABASE mydb;
ERROR: cannot execute CREATE DATABASE in a read-only transactionВсе още може да се случи подчинения да излезе от синхрон с главния. Повреждане на данните - нито хардуерът, нито софтуерът са без грешки и проблеми. Някои проблеми с дисковото устройство може да предизвикат повреда на данните на подчинения. Някои проблеми с процеса на „вакуум“ могат да доведат до промяна на данните. Как да се възстановя от това състояние?
Възстановяване на подчинения с помощта на pg_basebackup
Основната стъпка е да осигурите подчинения с помощта на данните от главния. Като се има предвид, че ще използваме поточно репликация, не можем да използваме логическо архивиране. За щастие има готов инструмент, който може да се използва за настройка на нещата:pg_basebackup. Нека видим какви биха били стъпките, които трябва да предприемем, за да осигурим подчинен сървър. За да стане ясно, ние използваме PostgreSQL 12 за целите на тази публикация в блога.
Началното състояние е просто. Нашият роб не се възпроизвежда от своя господар. Данните, които съдържа, са повредени и не могат да се използват, нито да се вярва. Следователно първата стъпка, която ще направим, ще бъде да спрем PostgreSQL на нашия подчинен и да премахнем данните, които съдържа:
example@sqldat.com:~# systemctl stop postgresqlИли дори:
example@sqldat.com:~# killall -9 postgresСега, нека проверим съдържанието на файла postgresql.auto.conf, можем да използваме идентификационни данни за репликация, съхранени в този файл по-късно, за pg_basebackup:
example@sqldat.com:~# cat /var/lib/postgresql/12/main/postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
promote_trigger_file='/tmp/failover_5432.trigger'
recovery_target_timeline=latest
primary_conninfo='application_name=pgsql_0_node_1 host=10.0.0.126 port=5432 user=cmon_replication password=qZnVoV7LV97CFX9F'Интересуваме се от потребителя и паролата, използвани за настройка на репликацията.
Най-накрая можем да премахнем данните:
example@sqldat.com:~# rm -rf /var/lib/postgresql/12/main/*След като данните бъдат премахнати, трябва да използваме pg_basebackup, за да получим данните от главния:
example@sqldat.com:~# pg_basebackup -h 10.0.0.126 -U cmon_replication -Xs -P -R -D /var/lib/postgresql/12/main/
Password:
waiting for checkpointФлаговете, които използвахме, имат следното значение:
- -Xs: бихме искали да предаваме поточно WAL, докато резервното копие е създадено. Това помага да се избегнат проблеми с премахването на WAL файлове, когато имате голям набор от данни.
- -P: бихме искали да видим напредъка на архивирането.
- -R: искаме pg_basebackup да създаде файл standby.signal и да подготви postgresql.auto.conf файл с настройки за връзка.
pg_basebackup ще изчака контролната точка, преди да започне архивирането. Ако отнема твърде много време, можете да използвате две опции. Първо, възможно е да се зададе бърз режим на контролна точка в pg_basebackup, като се използва опцията „-c fast“. Като алтернатива можете да форсирате контролна точка, като изпълните:
postgres=# CHECKPOINT;
CHECKPOINTПо един или друг начин pg_basebackup ще започне. С флага -P можем да проследяваме напредъка:
416906/1588478 kB (26%), 0/1 tablespaceceaceСлед като архивирането е готово, всичко, което трябва да направим, е да се уверим, че съдържанието на директорията с данни има присвоен правилен потребител и група - ние изпълнихме pg_basebackup като 'root', затова искаме да го променим на 'postgres ':
example@sqldat.com:~# chown -R postgres.postgres /var/lib/postgresql/12/main/Това е всичко, можем да стартираме подчинения и той трябва да започне да се репликира от главния.
example@sqldat.com:~# systemctl start postgresqlМожете да проверите отново напредъка на репликацията, като изпълните следната заявка на главния:
postgres=# SELECT * FROM pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state | reply_time
-------+----------+------------------+------------------+-------------+-----------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+------------+---------------+------------+-------------------------------
23565 | 16385 | cmon_replication | pgsql_0_node_1 | 10.0.0.128 | | 51554 | 2020-02-27 15:25:00.002734+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:32.594213+00
11914 | 16385 | cmon_replication | 12/main | 10.0.0.127 | | 25058 | 2020-02-28 13:42:09.160576+00 | | streaming | 2/AA5EF370 | 2/AA5EF2B0 | 2/AA5EF2B0 | 2/AA5EF2B0 | | | | 0 | async | 2020-02-28 13:45:42.41722+00
(2 rows)Както можете да видите, и двата подчинени устройства се репликират правилно.
Възстановяване на подчинения с помощта на ClusterControl
Ако сте потребител на ClusterControl, можете лесно да постигнете точно същото, само като изберете опция от потребителския интерфейс.
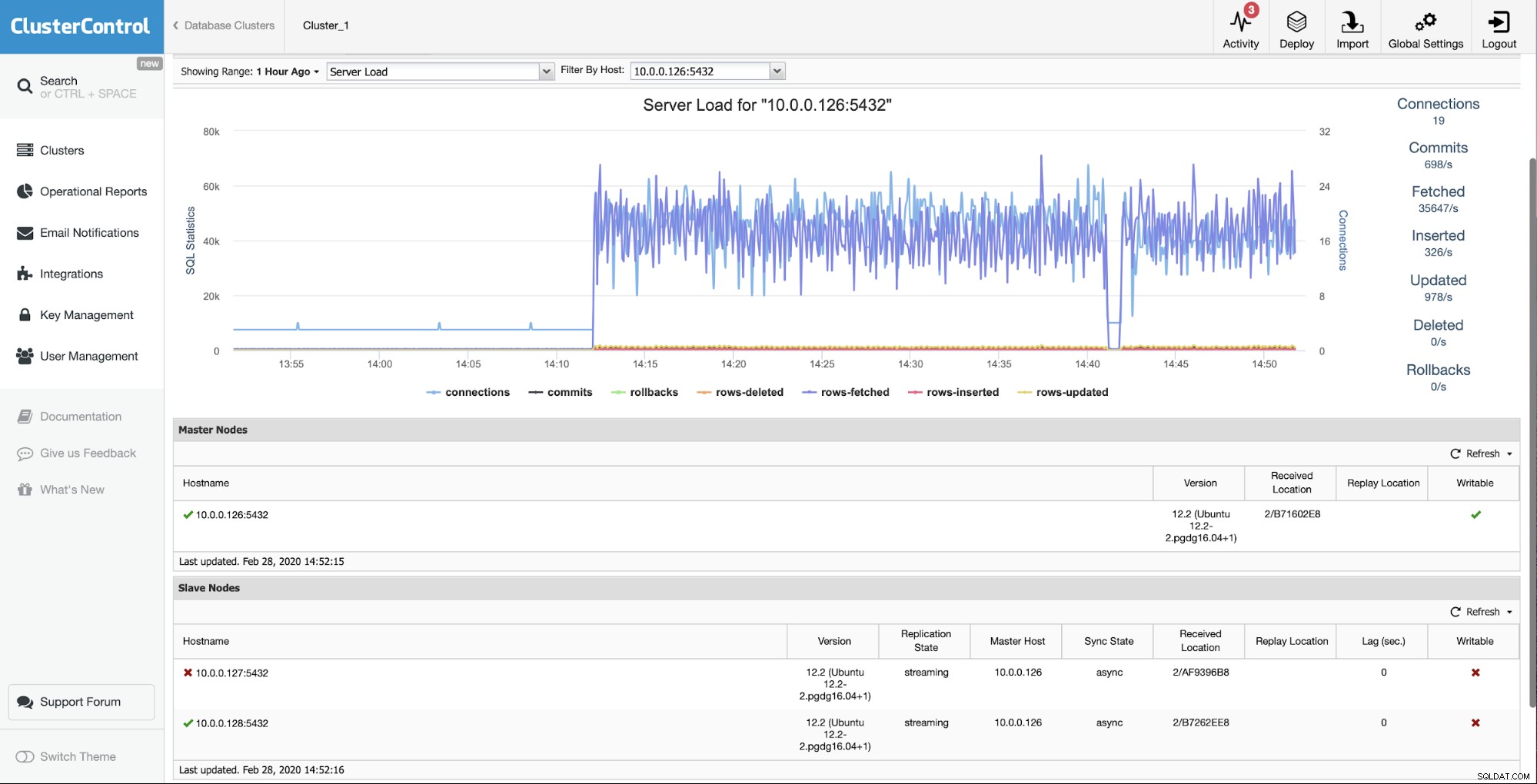
Първоначалната ситуация е, че един от подчинените (10.0.0.127) е не работи и не се възпроизвежда. Преценихме, че възстановяването е най-добрият вариант за нас.
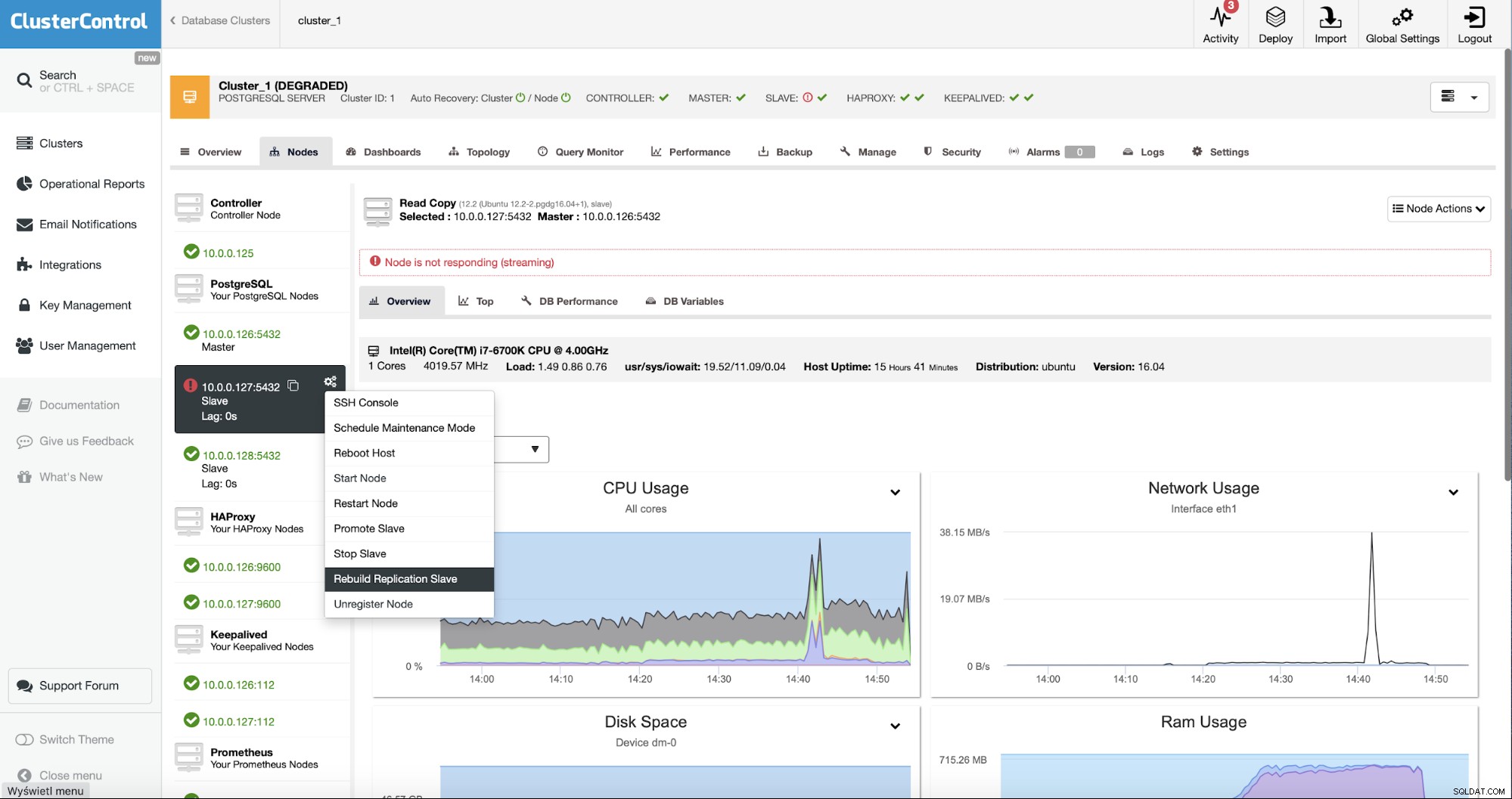
Като потребители на ClusterControl всичко, което трябва да направим, е да отидем на „Възли ” и стартирайте заданието „Rebuild Replication Slave”.
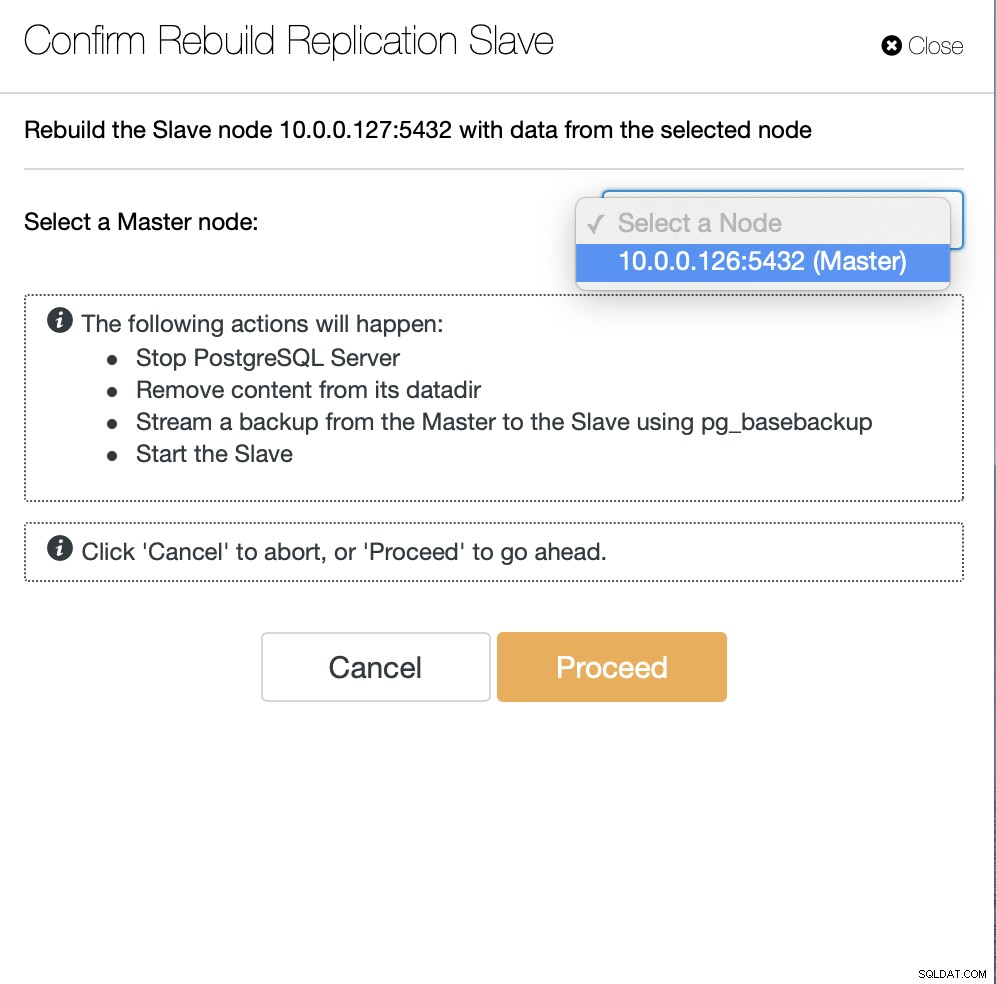
След това трябва да изберем възела, от който да възстановим подчинения и това е всичко. ClusterControl ще използва pg_basebackup, за да настрои подчинения за репликация и да конфигурира репликацията веднага щом данните бъдат прехвърлени.
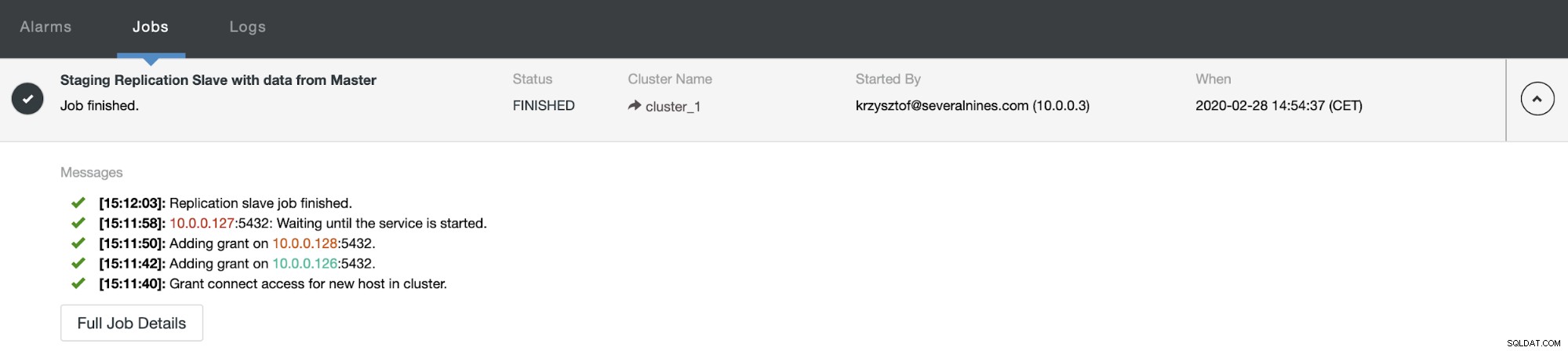
След известно време задачата приключи и подчиненият е обратно във веригата за репликация:
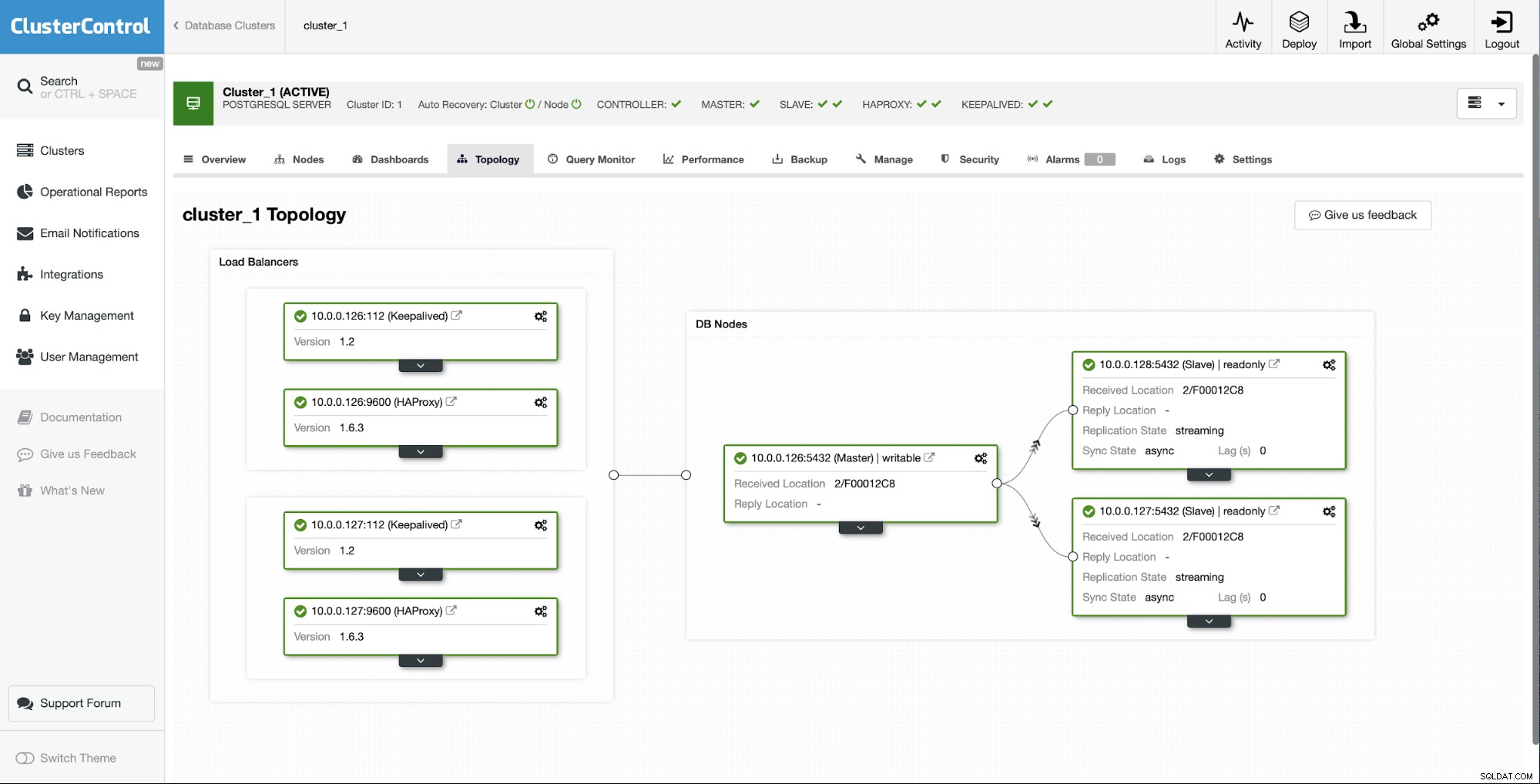
Както можете да видите, само с няколко щраквания, благодарение на ClusterControl, успяхме да възстановим нашия неуспешен подчинен и да го върнем обратно в клъстера.