Както наскоро обявихме, ClusterControl 1.7.4 има нова функция, наречена репликация от клъстер към клъстер. Тя ви позволява да имате репликация, работеща между два автономни клъстера. За по-подробна информация, моля, вижте споменатото по-горе съобщение.
Ще разгледаме как да използваме тази нова функция за съществуващ PostgreSQL клъстер. За тази задача ще приемем, че имате инсталиран ClusterControl и главният клъстер е разгърнат с него.
Изисквания за главния клъстер
Има някои изисквания към главния клъстер, за да работи:
- PostgreSQL 9.6 или по-нова версия.
- Трябва да има PostgreSQL сървър с ролята на ClusterControl „Master“.
- Когато настройвате подчинения клъстер, идентификационните данни на администратора трябва да са идентични с главния клъстер.
Подготовка на главния клъстер
Главният клъстер трябва да отговаря на посочените по-горе изисквания.
Относно първото изискване, уверете се, че използвате правилната версия на PostgreSQL в главния клъстер и изберете същата за подчинения клъстер.
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitАко трябва да присвоите главната роля на конкретен възел, можете да го направите от потребителския интерфейс на ClusterControl. Отидете на ClusterControl -> Изберете главен клъстер -> Възли -> Изберете възел -> Действия на възел -> Промотиране на подчинен.
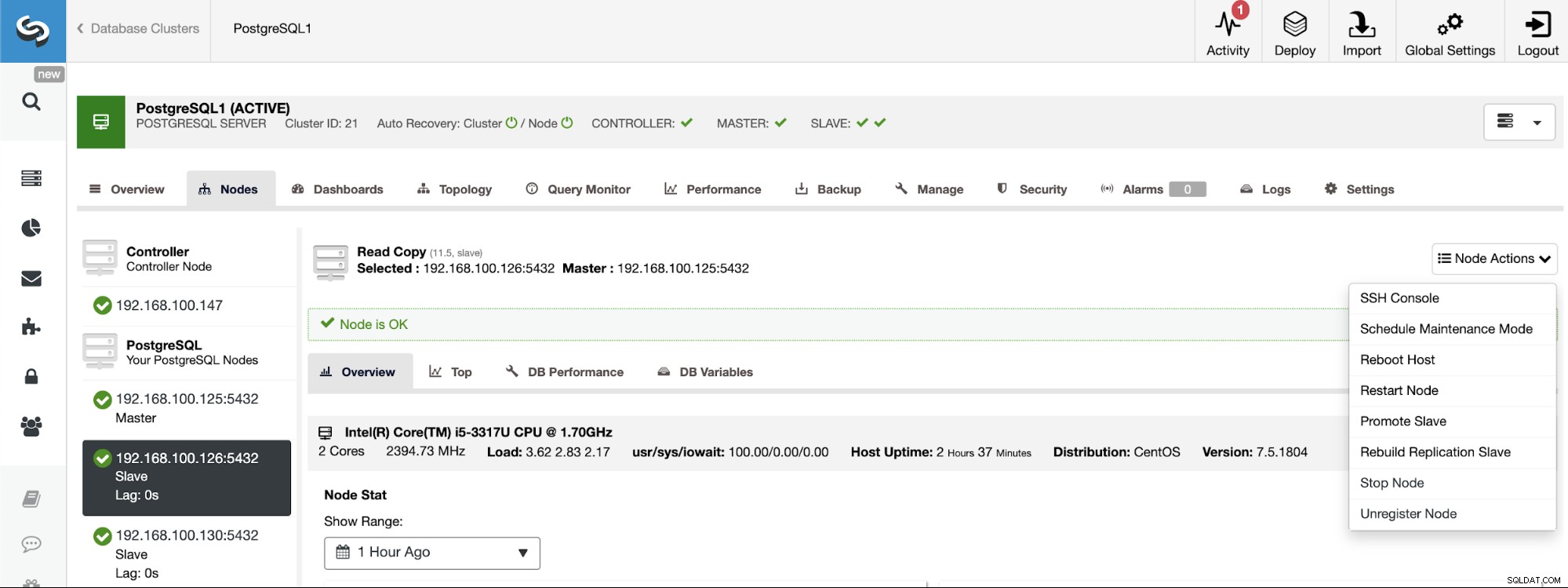
И накрая, по време на създаването на Slave Cluster, трябва да използвате същия администратор идентификационни данни, които използвате в момента в главния клъстер. Ще видите къде да го добавите в следващия раздел.
Създаване на подчинен клъстер от потребителския интерфейс на ClusterControl
За да създадете нов подчинен клъстер, отидете на ClusterControl -> Изберете Cluster -> Cluster Actions -> Създайте подчинен клъстер.
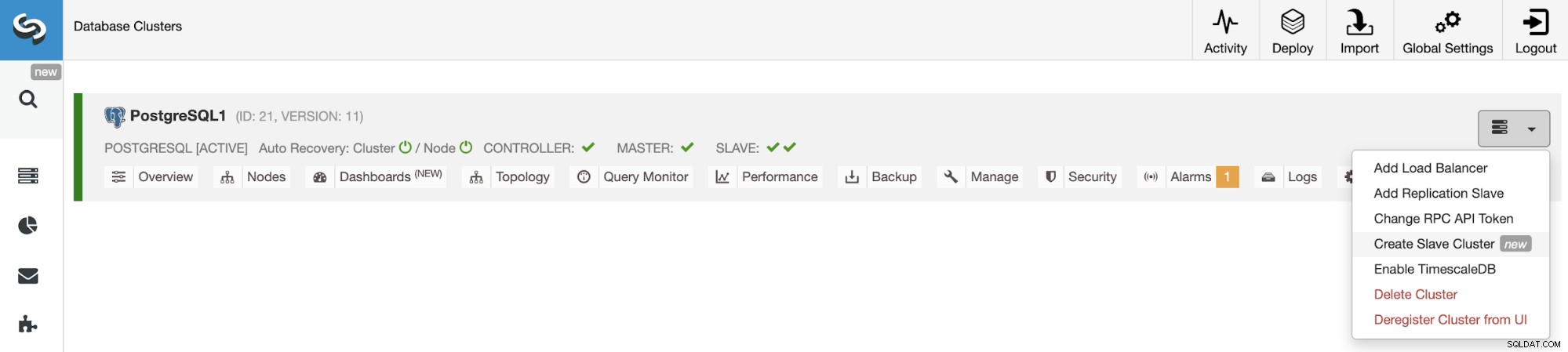
Подчинения клъстер ще бъде създаден чрез поточно предаване на данни от текущия главен клъстер.
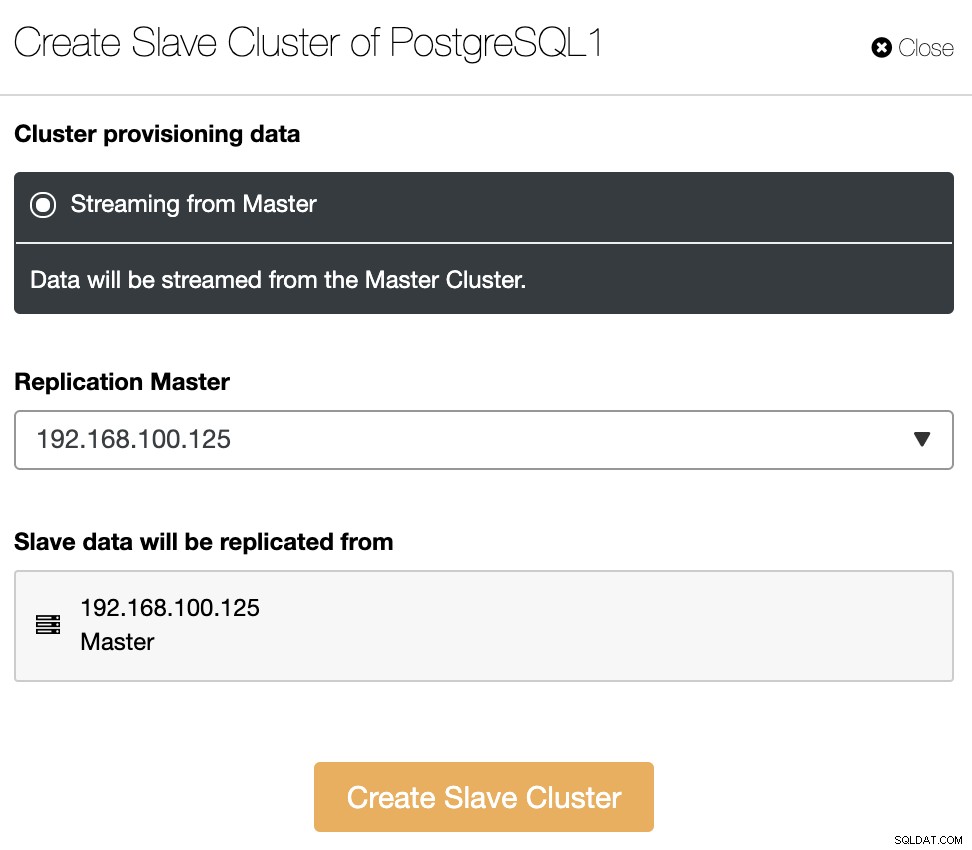
В този раздел трябва също да изберете главния възел на текущия клъстер от който данните ще бъдат репликирани.
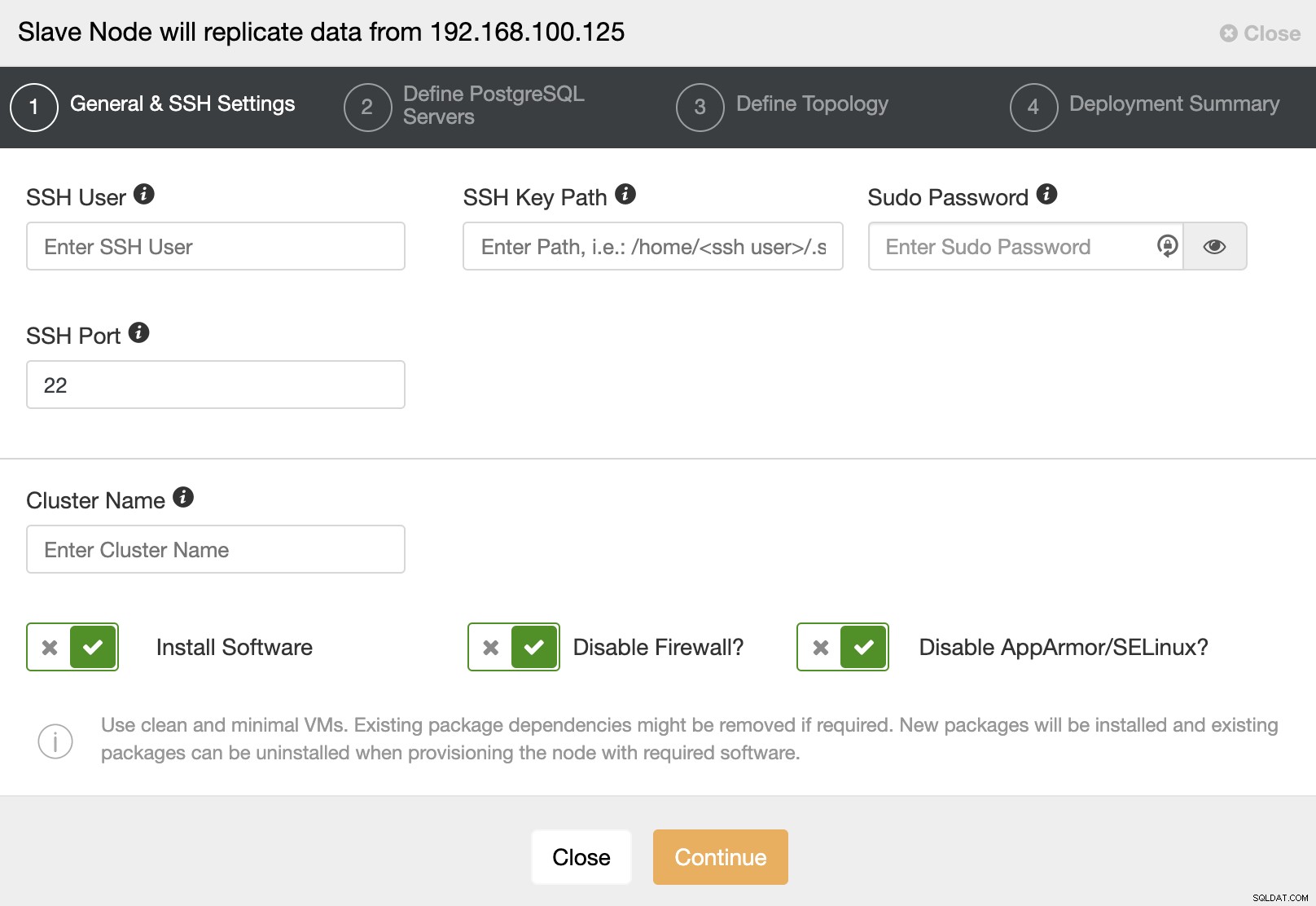
Когато преминете към следващата стъпка, трябва да посочите потребител, ключ или Парола и порт за свързване чрез SSH към вашите сървъри. Освен това имате нужда от име за вашия подчинен клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
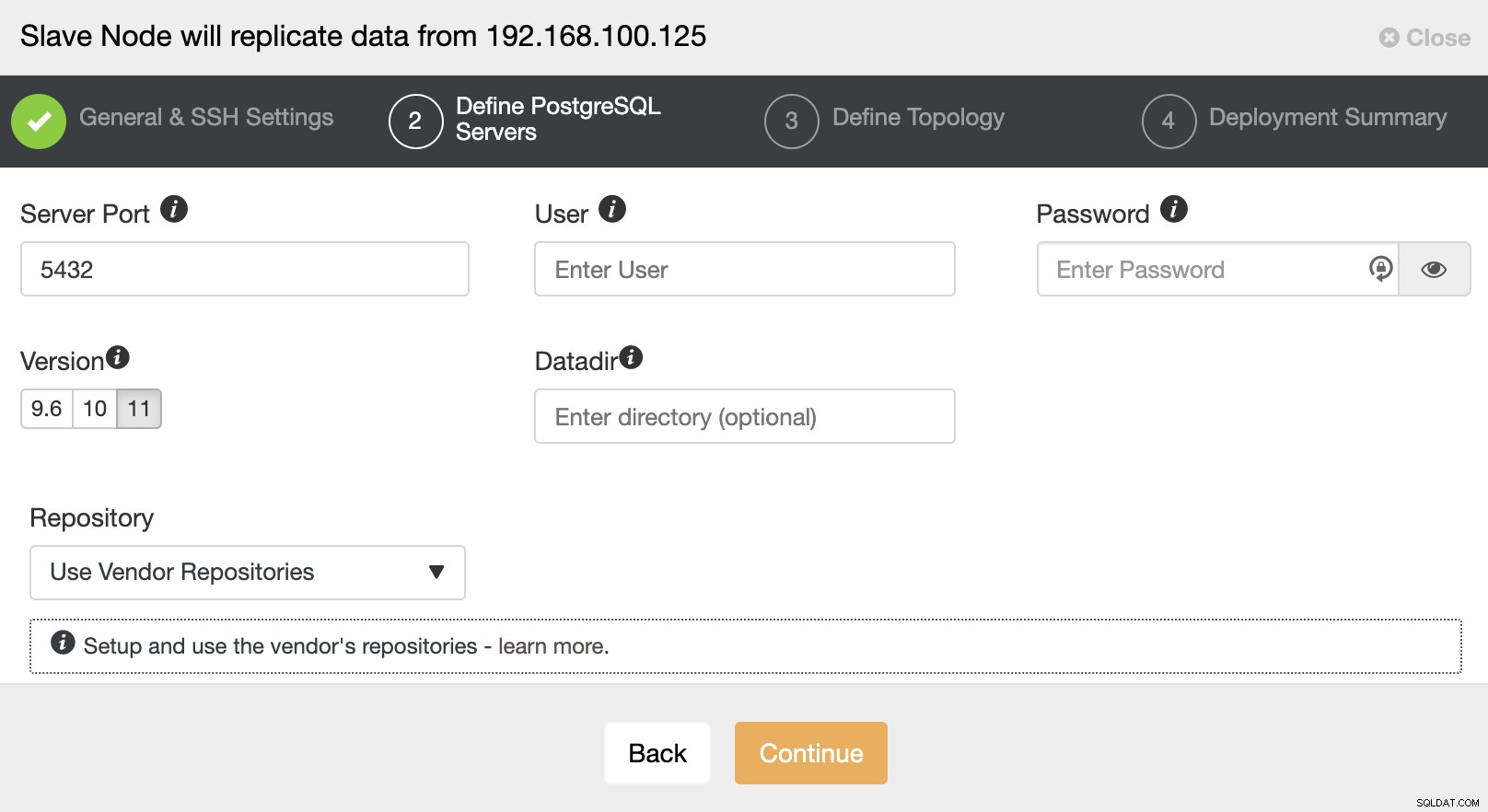
След като настроите информацията за SSH достъп, трябва да дефинирате версията на базата данни, datadir, порт и идентификационни данни на администратора. Тъй като ще използва стрийминг репликация, уверете се, че използвате същата версия на базата данни и както споменахме по-рано, идентификационните данни трябва да са същите, използвани от главния клъстер. Можете също да посочите кое хранилище да използвате.
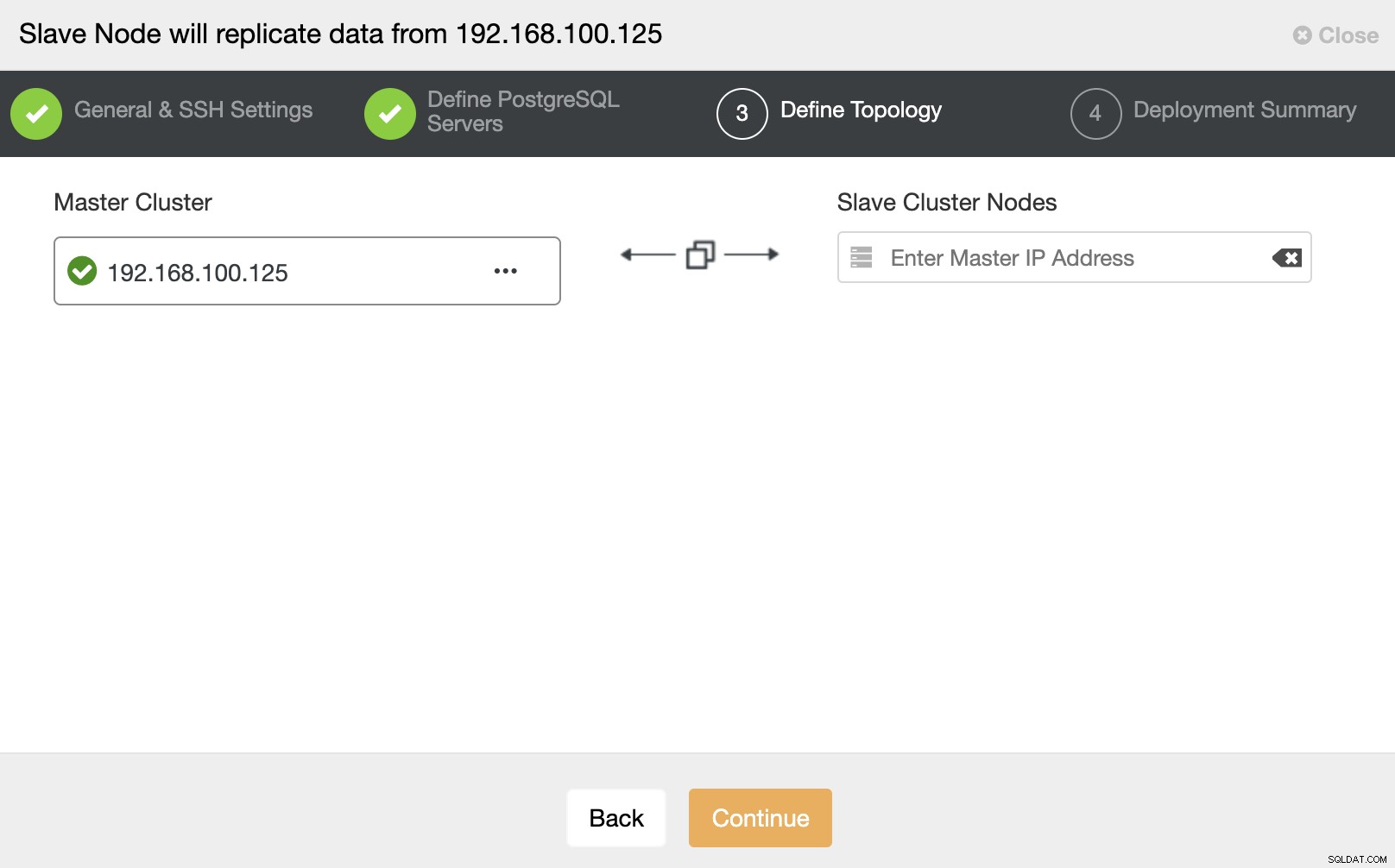
В тази стъпка трябва да добавите сървъра към новия подчинен клъстер . За тази задача можете да въведете както IP адрес, така и име на хост на възела на базата данни.
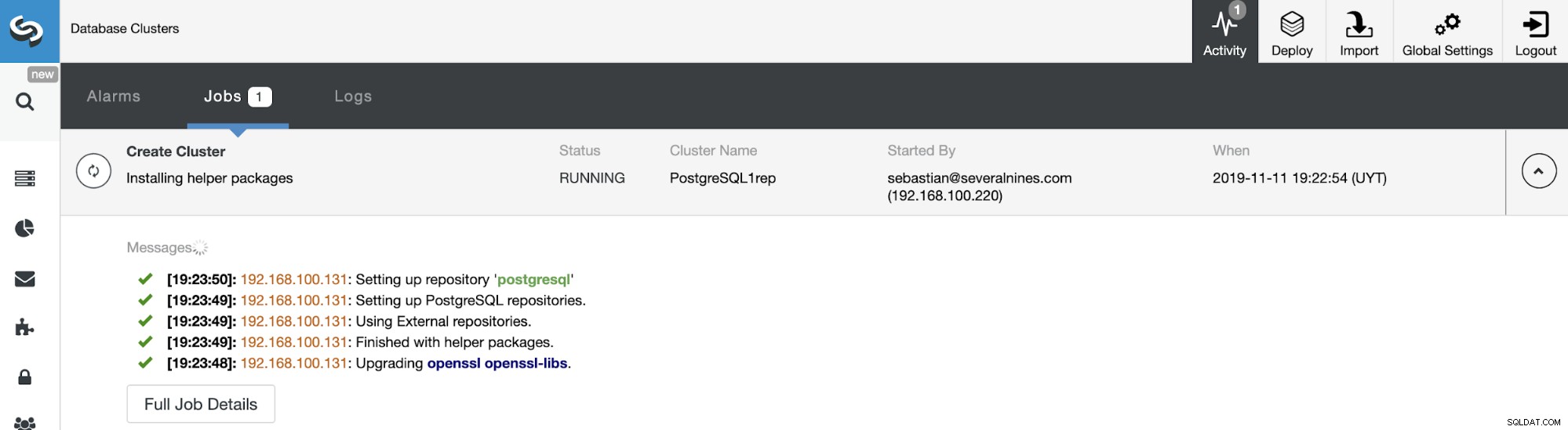
Можете да наблюдавате състоянието на създаването на вашия нов подчинен клъстер от Монитор на активността на ClusterControl. След като задачата приключи, можете да видите клъстера в главния екран на ClusterControl.
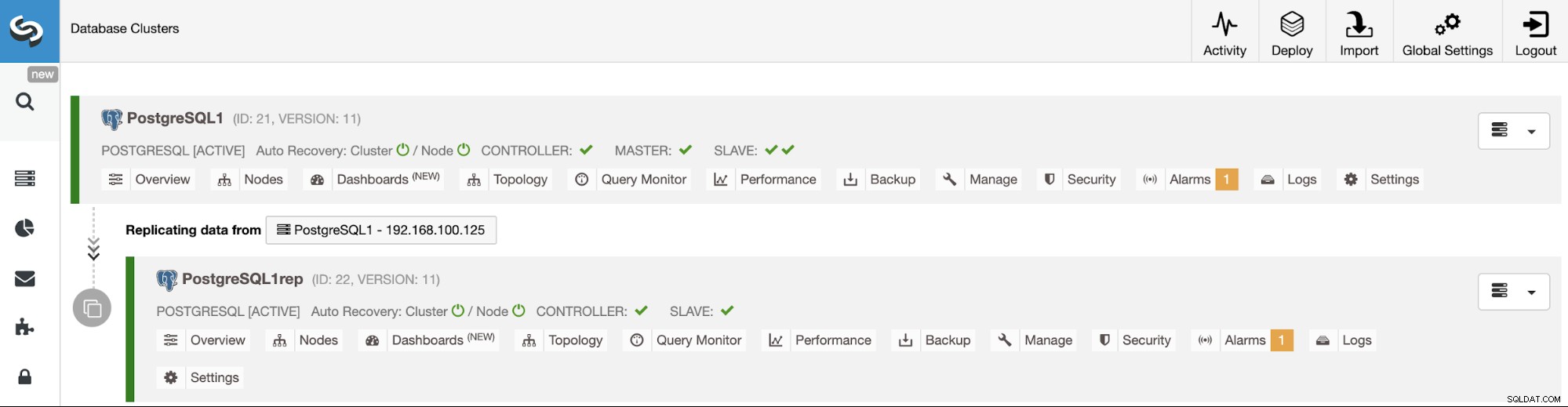
Управление на репликация от клъстер към клъстер с помощта на потребителския интерфейс на ClusterControl
Сега вашата репликация от клъстер към клъстер е стартирана и работи, има различни действия за извършване на тази топология с помощта на ClusterControl.
Възстановяване на подчинен клъстер
За да изградите отново подчинен клъстер, отидете на ClusterControl -> Изберете подчинен клъстер -> Възли -> Изберете възела, свързан към главния клъстер -> Действия на възел -> Възстановяване на подчинен клъстер за репликация.
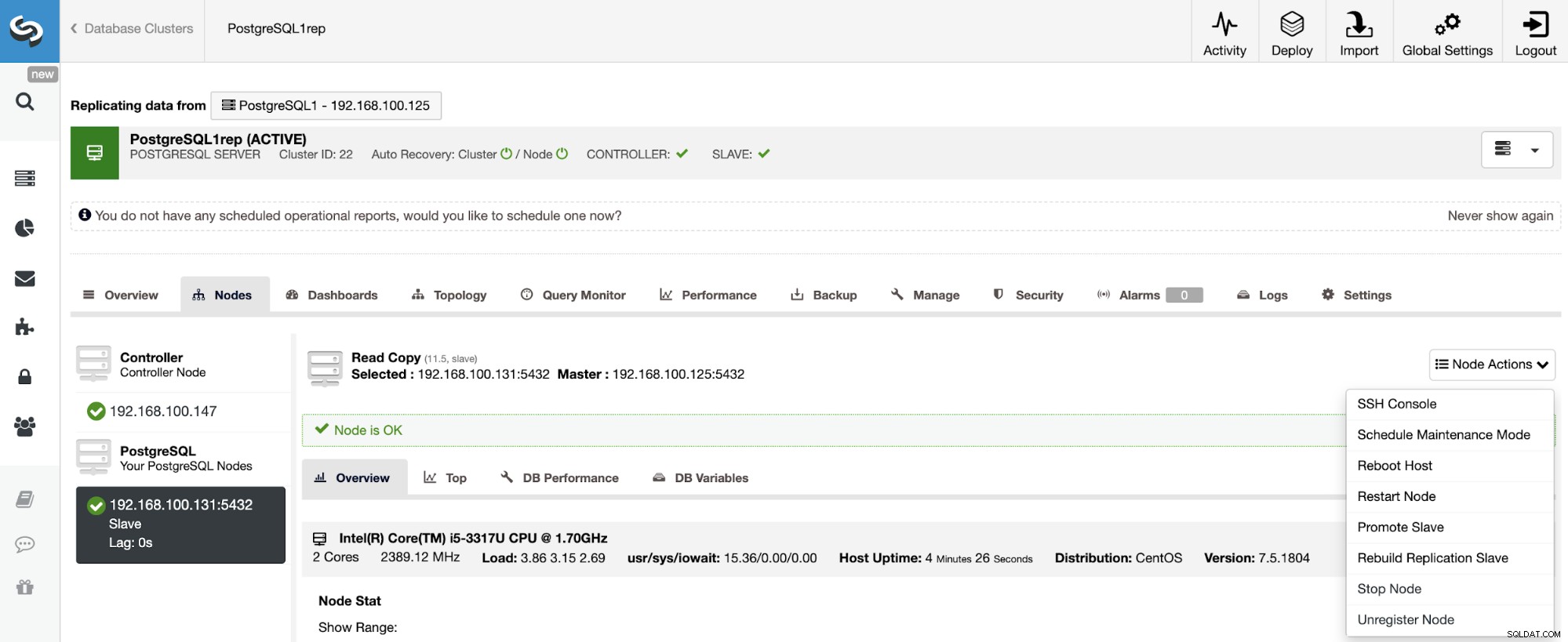
ClusterControl ще изпълни следните стъпки:
- Спиране на PostgreSQL сървър
- Премахнете съдържанието от неговата директория с данни
- Предавайте поточно архивно копие от главния към подчинения с помощта на pg_basebackup
- Стартирайте подчинения
Спиране/Стартиране на подчинено устройство за репликация
Спирането и стартирането на репликацията в PostgreSQL означава пауза и възобновяване, но ние използваме тези условия, за да бъдем в съответствие с другите технологии за бази данни, които поддържаме.
Тази функция скоро ще бъде достъпна за използване от потребителския интерфейс на ClusterControl. Това действие ще използва функциите pg_wal_replay_pause и pg_wal_replay_resume PostgreSQL, за да изпълни тази задача.
Междувременно можете да използвате заобиколно решение, за да спрете и стартирате подчинения за репликация, спирайки и стартирайки възела на базата данни по лесен начин с помощта на ClusterControl.
Отидете на ClusterControl -> Изберете Slave Cluster -> Nodes -> Изберете Възел -> Действия на възел -> Стоп възел/Начален възел. Това действие ще спре/стартира директно услугата за база данни.
Управление на репликация от клъстер към клъстер с помощта на ClusterControl CLI
В предишния раздел успяхте да видите как да управлявате репликация от клъстер към клъстер с помощта на потребителския интерфейс на ClusterControl. Сега нека да видим как да го направите с помощта на командния ред.
Забележка:Както споменахме в началото на този блог, ще приемем, че имате инсталиран ClusterControl и главният клъстер е разгърнат с него.
Създайте подчинен клъстер
Първо, нека видим примерна команда за създаване на подчинен клъстер с помощта на ClusterControl CLI:
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logСега стартирате вашия процес за създаване на подчинен, нека видим всеки използван параметър:
- Клъстер:За изброяване и манипулиране на клъстери.
- Създаване:Създайте и инсталирайте нов клъстер.
- Име на клъстер:Името на новия подчинен клъстер.
- Тип клъстер:Типът клъстер за инсталиране.
- Версия на доставчика:Версията на софтуера.
- Възли:Списък на новите възли в подчинения клъстер.
- Os-user:Потребителското име за SSH командите.
- Os-key-file:Ключовият файл, който да се използва за SSH връзка.
- Db-admin:Потребителското име на администратора на базата данни.
- Db-admin-passwd:Паролата за администратора на базата данни.
- Remote-cluster-id:Главен идентификатор на клъстер за репликацията от клъстер към клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Използвайки флага --log, ще можете да виждате регистрационните файлове в реално време:
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.Възстановяване на подчинен клъстер
Можете да изградите отново подчинен клъстер, като използвате следната команда:
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --logПараметрите са:
- Репликация:За наблюдение и контрол на репликацията на данни.
- Етап:Етап/преизграждане на подчинен репликация.
- Мастер:Главният главен адрес на репликация в главния клъстер.
- Slave:Подчинения за репликация в подчинения клъстер.
- Cluster-id:Идентификаторът на подчинения клъстер.
- Remote-cluster-id:Идентификаторът на главния клъстер.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Регистърът на заданията трябва да е подобен на този:
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.Спиране/Стартиране на подчинено устройство за репликация
Както споменахме в секцията на потребителския интерфейс, спирането и стартирането на репликацията в PostgreSQL означава пауза и възобновяване, но ние използваме тези термини, за да запазим паралелизма с други технологии.
Можете да спрете да репликирате данните от главния клъстер по този начин:
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logЩе видите това:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().И сега можете да го стартирате отново:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logИ така, ще видите:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().Сега нека проверим използваните параметри.
- Репликация:За наблюдение и контрол на репликацията на данни.
- Спиране/Стартиране:За да накарате подчинения да спре/започне репликацията.
- Slave:Подчинен възел за репликация.
- Cluster-id:Идентификаторът на клъстера, в който е подчинения възел.
- Регистър:Изчакайте и наблюдавайте съобщенията за задание.
Заключение
Тази нова функция на ClusterControl ще ви позволи бързо да настроите репликация между различни PostgreSQL клъстери и да управлявате настройката по лесен и удобен начин. Екипът на разработчиците на Severalnines работи върху подобряването на тази функция, така че всякакви идеи или предложения ще бъдат много добре дошли.