Високата наличност е изискване за почти всяка компания по света, използваща PostgreSQL. Добре известно е, че PostgreSQL използва поточно репликация като метод за репликация. Поточната репликация на PostgreSQL е асинхронна по подразбиране, така че е възможно да има някои транзакции, ангажирани в основния възел, които все още не са репликирани на сървъра в режим на готовност. Това означава, че има вероятност от потенциална загуба на данни.
Това забавяне в процеса на запис трябва да е много малко... ако сървърът в режим на готовност е достатъчно мощен, за да се справи с натоварването. Ако този малък риск от загуба на данни не е приемлив за компанията, можете също да използвате синхронна репликация вместо по подразбиране.
При синхронна репликация всяко записване на транзакция за запис ще изчака до потвърждението, че записването е било записано в регистъра за предварителна запис на диска както на основния, така и на резервния сървър.
Този метод минимизира възможността от загуба на данни. За да възникне загуба на данни, ще трябва и основният, и резервният да се провалят едновременно.
Недостатъкът на този метод е същият за всички синхронни методи, тъй като при този метод времето за отговор за всяка транзакция на запис се увеличава. Това се дължи на необходимостта да се изчака до всички потвърждения, че транзакцията е извършена. За щастие транзакциите само за четене няма да бъдат засегнати от това, но; само транзакциите за запис.
В този блог вие показвате как да инсталирате PostgreSQL клъстер от нулата, да конвертирате асинхронната репликация (по подразбиране) в синхронна. Също така ще ви покажа как да връщате назад , ако времето за отговор не е приемливо, тъй като можете лесно да се върнете към предишното състояние. Ще видите как лесно да разгръщате, конфигурирате и наблюдавате синхронна репликация на PostgreSQL, като използвате ClusterControl, като използвате само един инструмент за целия процес.
Инсталиране на PostgreSQL клъстер
Нека започнем да инсталираме и конфигурираме асинхронна PostgreSQL репликация, това е обичайният режим на репликация, използван в PostgreSQL клъстер. Ще използваме PostgreSQL 11 на CentOS 7.
Инсталиране на PostgreSQL
Следвайки официалното ръководство за инсталиране на PostgreSQL, тази задача е доста проста.
Първо, инсталирайте хранилището:
$ yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpmИнсталирайте клиентските и сървърните пакети на PostgreSQL:
$ yum install postgresql11 postgresql11-serverИнициализирайте базата данни:
$ /usr/pgsql-11/bin/postgresql-11-setup initdb
$ systemctl enable postgresql-11
$ systemctl start postgresql-11На възела в режим на готовност можете да избегнете последната команда (стартирайте услугата на базата данни), тъй като ще възстановите двоично резервно копие, за да създадете репликация на поточно предаване.
Сега нека видим конфигурацията, изисквана от асинхронна PostgreSQL репликация.
Конфигуриране на асинхронна PostgreSQL репликация
Настройка на първичен възел
В основния възел на PostgreSQL трябва да използвате следната основна конфигурация, за да създадете асинхронна репликация. Файловете, които ще бъдат променени, са postgresql.conf и pg_hba.conf. Като цяло те са в директорията с данни (/var/lib/pgsql/11/data/), но можете да го потвърдите от страната на базата данни:
postgres=# SELECT setting FROM pg_settings WHERE name = 'data_directory';
setting
------------------------
/var/lib/pgsql/11/data
(1 row)Postgresql.conf
Променете или добавете следните параметри в конфигурационния файл postgresql.conf.
Тук трябва да добавите IP адреса(ите), където да слушате. Стойността по подразбиране е „localhost“ и за този пример ще използваме „*“ за всички IP адреси в сървъра.
listen_addresses = '*' Задайте порта на сървъра, където да слушате. По подразбиране 5432.
port = 5432 Определете колко информация се записва в WAL. Възможните стойности са минимални, реплика или логически. Стойността hot_standby се преобразува в реплика и се използва за запазване на съвместимостта с предишни версии.
wal_level = hot_standby Задайте максималния брой процеси на walsender, които управляват връзката със сървър в режим на готовност.
max_wal_senders = 16Задайте минималното количество WAL файлове, които да се съхраняват в директорията pg_wal.
wal_keep_segments = 32Промяната на тези параметри изисква рестартиране на услугата за база данни.
$ systemctl restart postgresql-11Pg_hba.conf
Променете или добавете следните параметри в конфигурационния файл pg_hba.conf.
# TYPE DATABASE USER ADDRESS METHOD
host replication replication_user IP_STANDBY_NODE/32 md5
host replication replication_user IP_PRIMARY_NODE/32 md5Както можете да видите, тук трябва да добавите разрешение за потребителски достъп. Първата колона е типът на връзката, който може да бъде хост или локален. След това трябва да посочите база данни (репликация), потребител, IP адрес на източника и метод за удостоверяване. Промяната на този файл изисква презареждане на услугата за база данни.
$ systemctl reload postgresql-11Трябва да добавите тази конфигурация както в основния, така и в резервния възел, тъй като ще ви е необходима, ако възелът в режим на готовност се повиши до главен в случай на повреда.
Сега трябва да създадете потребител за репликация.
Роля на репликация
РОЛЯТА (потребител) трябва да има привилегия REPLICATION, за да я използва в поточно репликацията.
postgres=# CREATE ROLE replication_user WITH LOGIN PASSWORD 'PASSWORD' REPLICATION;
CREATE ROLEСлед като конфигурирате съответните файлове и създаването на потребител, трябва да създадете последователно резервно копие от основния възел и да го възстановите на възел в режим на готовност.
Настройка на възел в режим на готовност
На възела в режим на готовност отидете в директорията /var/lib/pgsql/11/ и преместете или премахнете текущата директория с данни:
$ cd /var/lib/pgsql/11/
$ mv data data.bkСлед това изпълнете командата pg_basebackup, за да получите текущия първичен datadir и задайте правилния собственик (postgres):
$ pg_basebackup -h 192.168.100.145 -D /var/lib/pgsql/11/data/ -P -U replication_user --wal-method=stream
$ chown -R postgres.postgres dataСега трябва да използвате следната основна конфигурация, за да създадете асинхронна репликация. Файлът, който ще бъде променен е postgresql.conf и трябва да създадете нов файл recovery.conf. И двете ще се намират в /var/lib/pgsql/11/.
Recovery.conf
Посочете, че този сървър ще бъде сървър в режим на готовност. Ако е включен, сървърът ще продължи да се възстановява чрез извличане на нови сегменти на WAL, когато се достигне краят на архивирания WAL.
standby_mode = 'on'Посочете низ за връзка, който да се използва за свързване на сървъра в режим на готовност към основния възел.
primary_conninfo = 'host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'Посочете възстановяването в определена времева линия. По подразбиране се възстановява по същата времева линия, която е била текуща, когато е направено основното архивиране. Задаването на това на „най-ново“ се възстановява до най-новата времева линия, намерена в архива.
recovery_target_timeline = 'latest'Посочете файл за задействане, чието присъствие прекратява възстановяването в режим на готовност.
trigger_file = '/tmp/failover_5432.trigger'Postgresql.conf
Променете или добавете следните параметри в конфигурационния файл postgresql.conf.
Определете колко информация се записва в WAL. Възможните стойности са минимални, реплика или логически. Стойността hot_standby се преобразува в реплика и се използва за запазване на съвместимостта с предишни версии. Промяната на тази стойност изисква рестартиране на услугата.
wal_level = hot_standbyРазрешаване на заявките по време на възстановяване. Промяната на тази стойност изисква рестартиране на услугата.
hot_standby = onСтартиране на възел в режим на готовност
Сега разполагате с цялата необходима конфигурация, просто трябва да стартирате услугата за база данни на възела в режим на готовност.
$ systemctl start postgresql-11И проверете регистрационните файлове в базата данни в /var/lib/pgsql/11/data/log/. Трябва да имате нещо подобно:
2019-11-18 20:23:57.440 UTC [1131] LOG: entering standby mode
2019-11-18 20:23:57.447 UTC [1131] LOG: redo starts at 0/3000028
2019-11-18 20:23:57.449 UTC [1131] LOG: consistent recovery state reached at 0/30000F8
2019-11-18 20:23:57.449 UTC [1129] LOG: database system is ready to accept read only connections
2019-11-18 20:23:57.457 UTC [1135] LOG: started streaming WAL from primary at 0/4000000 on timeline 1Можете също да проверите състоянието на репликация в основния възел, като изпълните следната заявка:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1467 | replication_user | walreceiver | streaming | async
(1 row)Както можете да видите, ние използваме асинхронна репликация.
Преобразуване на асинхронна PostgreSQL репликация в синхронна репликация
Сега е време да преобразувате тази асинхронна репликация в синхронизирана и за това ще трябва да конфигурирате както основния, така и резервния възел.
Основен възел
В основния възел на PostgreSQL трябва да използвате тази основна конфигурация в допълнение към предишната асинхронна конфигурация.
Postgresql.conf
Посочете списък със сървъри в режим на готовност, които могат да поддържат синхронна репликация. Това име на сървър в режим на готовност е настройката application_name във файла recovery.conf на резервния режим.
synchronous_standby_names = 'pgsql_0_node_0'synchronous_standby_names = 'pgsql_0_node_0'Указва дали транзакцията commit ще изчака записите на WAL да бъдат записани на диска, преди командата да върне индикация за „успех“ на клиента. Валидните стойности са on, remote_apply, remote_write, local и off. Стойността по подразбиране е включена.
synchronous_commit = onНастройка на възел в режим на готовност
В възела на готовност на PostgreSQL трябва да промените файла recovery.conf, като добавите стойността 'application_name в параметъра primary_conninfo.
Recovery.conf
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_0_node_0 host=IP_PRIMARY_NODE port=5432 user=replication_user password=PASSWORD'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover_5432.trigger'Рестартирайте услугата за база данни както в основния, така и в резервния възел:
$ service postgresql-11 restartСега трябва да стартирате и стартирате репликацията на поточно синхронизиране:
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1561 | replication_user | pgsql_0_node_0 | streaming | sync
(1 row)Отвръщане от синхронно към асинхронно PostgreSQL репликация
Ако трябва да се върнете към асинхронна PostgreSQL репликация, просто трябва да върнете обратно промените, извършени във файла postgresql.conf на основния възел:
Postgresql.conf
#synchronous_standby_names = 'pgsql_0_node_0'
#synchronous_commit = onИ рестартирайте услугата за база данни.
$ service postgresql-11 restartИ така, сега трябва да имате отново асинхронна репликация.
postgres=# SELECT pid,usename,application_name,state,sync_state FROM pg_stat_replication;
pid | usename | application_name | state | sync_state
------+------------------+------------------+-----------+------------
1625 | replication_user | pgsql_0_node_0 | streaming | async
(1 row)Как да разположите синхронна репликация на PostgreSQL с помощта на ClusterControl
С ClusterControl можете да изпълнявате задачите за внедряване, конфигуриране и наблюдение всичко в едно от едно и също задание и ще можете да го управлявате от същия потребителски интерфейс.
Ще приемем, че имате инсталиран ClusterControl и той има достъп до възлите на базата данни чрез SSH. За повече информация как да конфигурирате достъпа на ClusterControl, моля, вижте нашата официална документация.
Отидете в ClusterControl и използвайте опцията „Deploy“, за да създадете нов PostgreSQL клъстер.
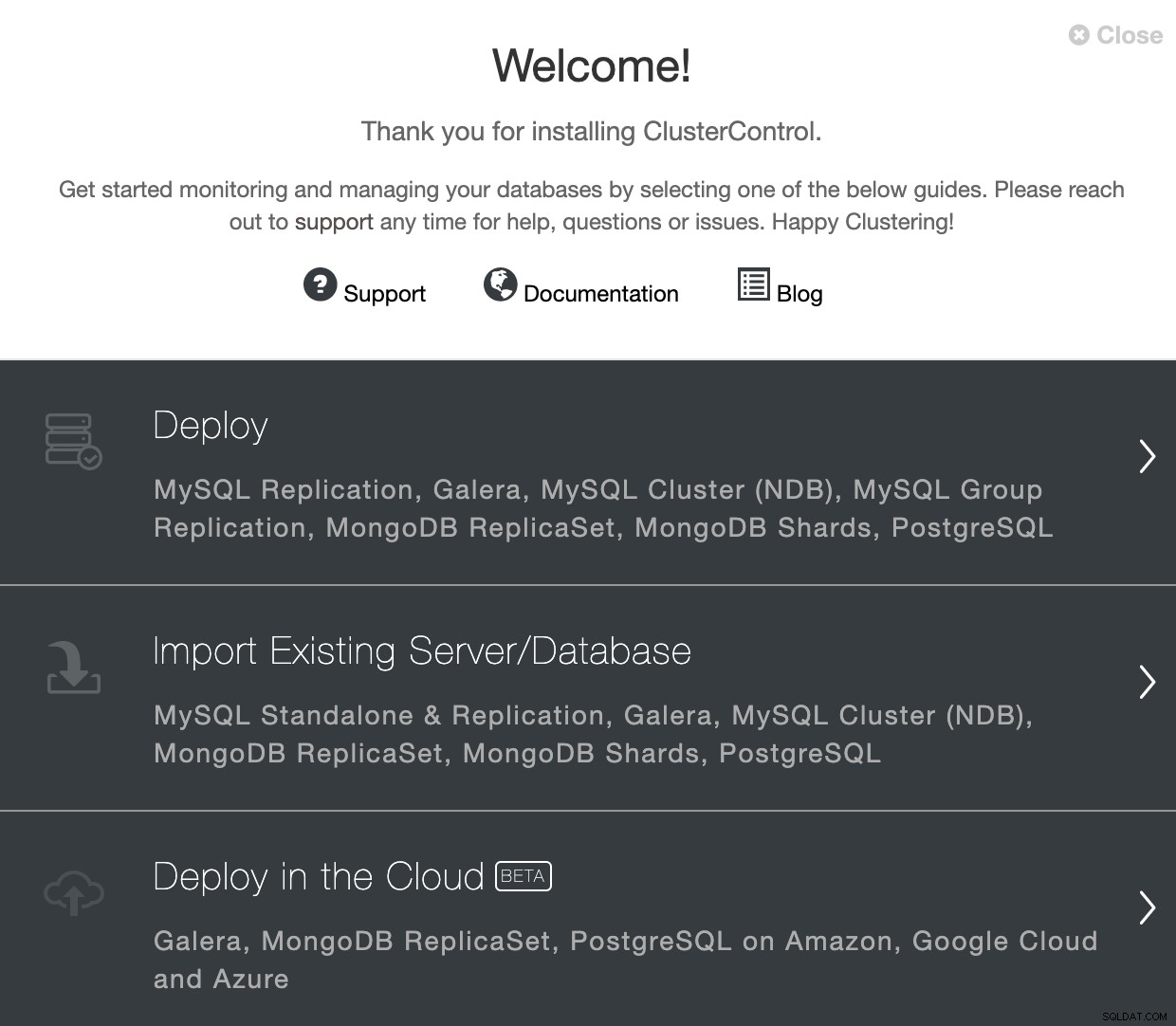
Когато избирате PostgreSQL, трябва да посочите потребител, ключ или парола и порт за свързване чрез SSH към нашите сървъри. Освен това имате нужда от име за вашия нов клъстер и ако искате ClusterControl да инсталира съответния софтуер и конфигурации вместо вас.
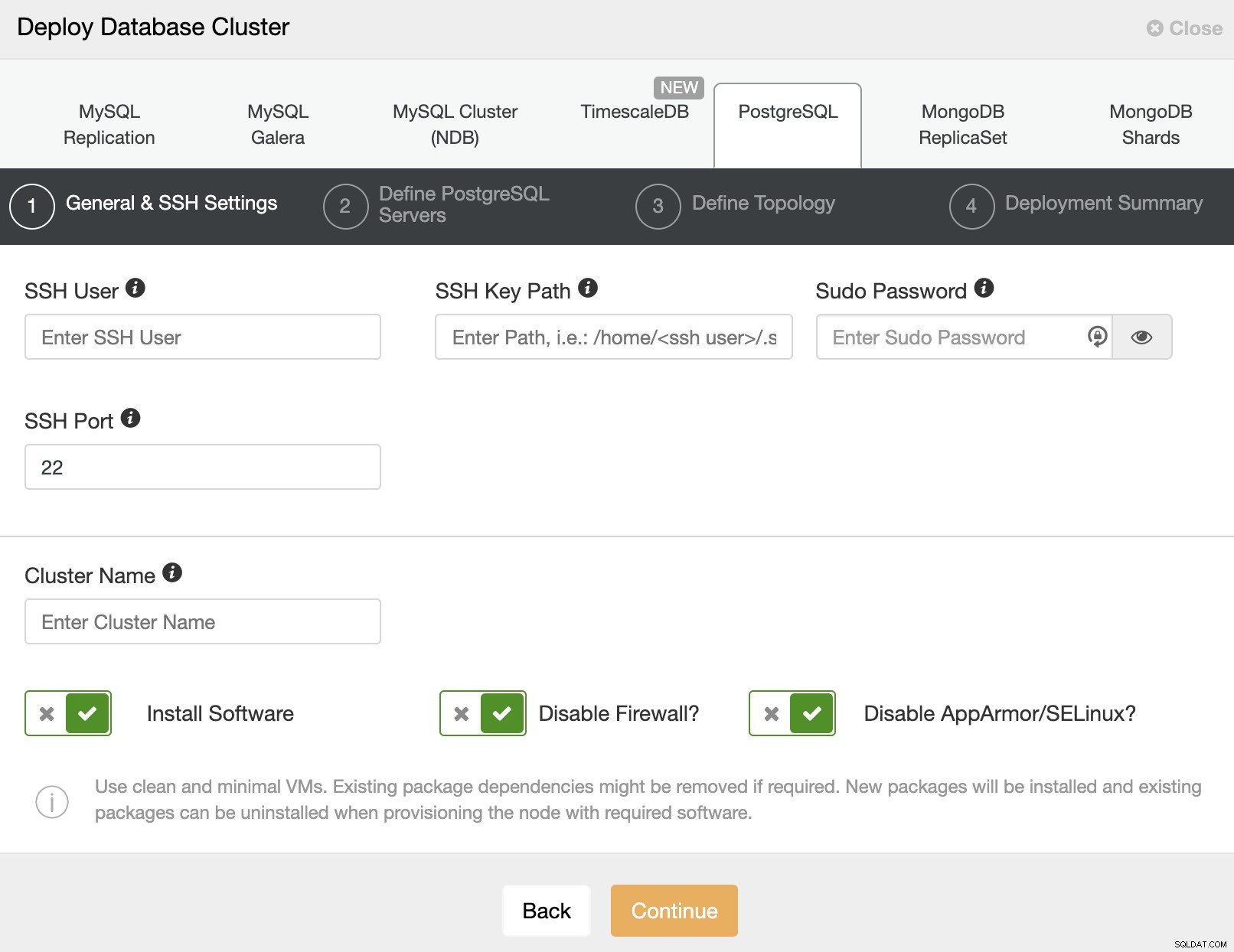
След като настроите информацията за SSH достъп, трябва да въведете данните за достъп вашата база данни. Можете също да посочите кое хранилище да използвате.
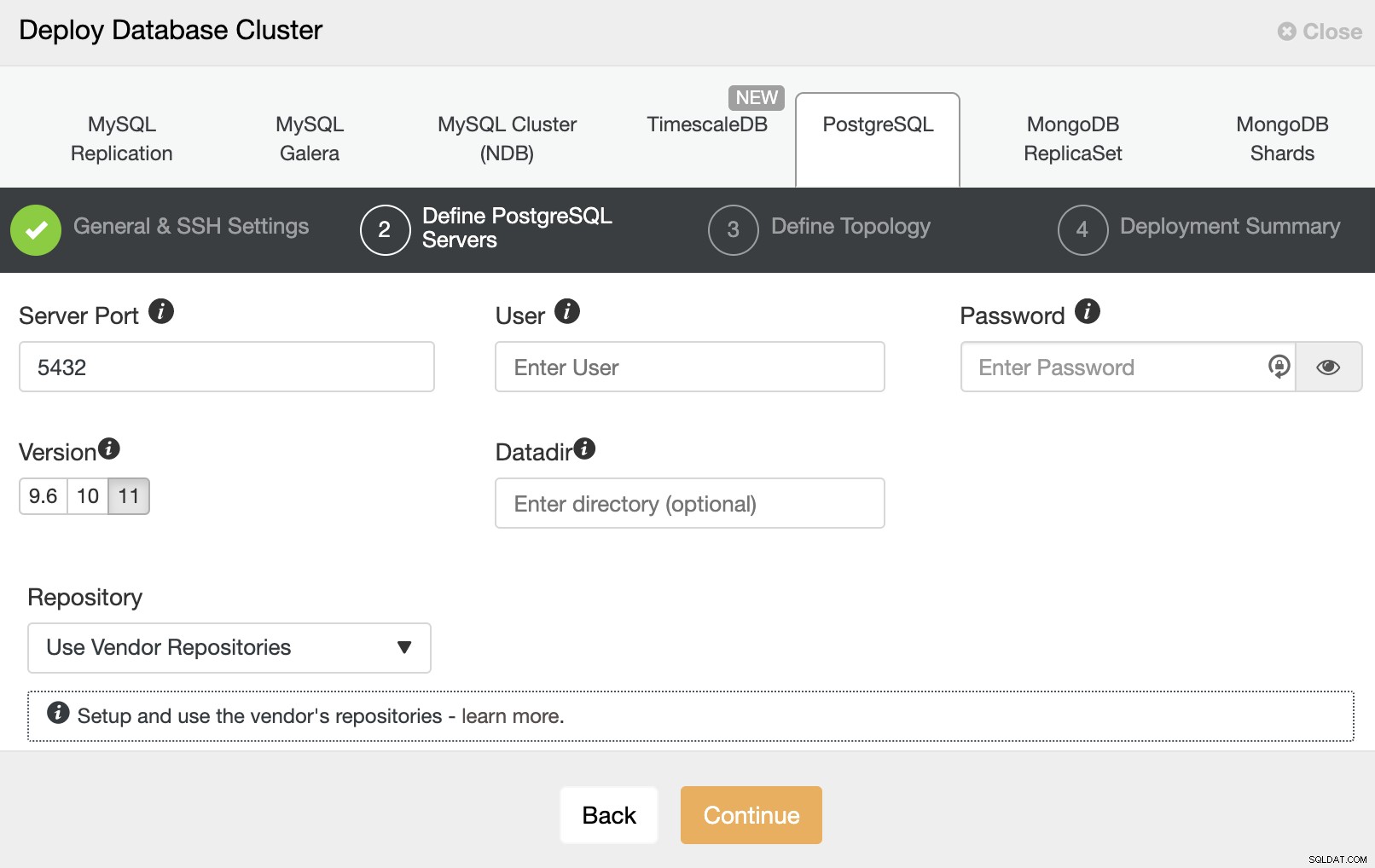
В следващата стъпка трябва да добавите вашите сървъри към клъстера, който ще създадеш. Когато добавяте вашите сървъри, можете да въведете IP или име на хост.
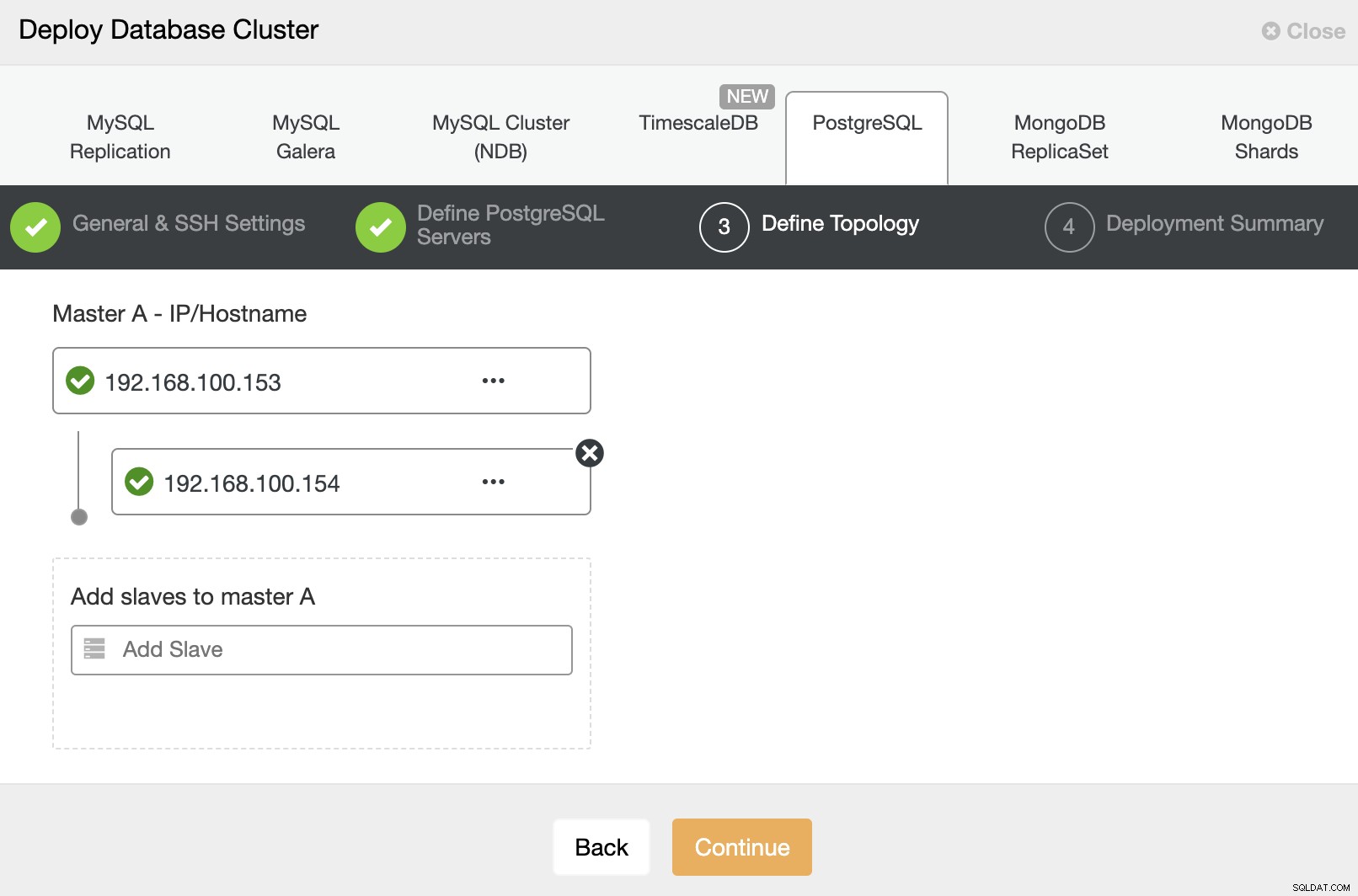
И накрая, в последната стъпка, можете да изберете метода на репликация, която може да бъде асинхронна или синхронна репликация.
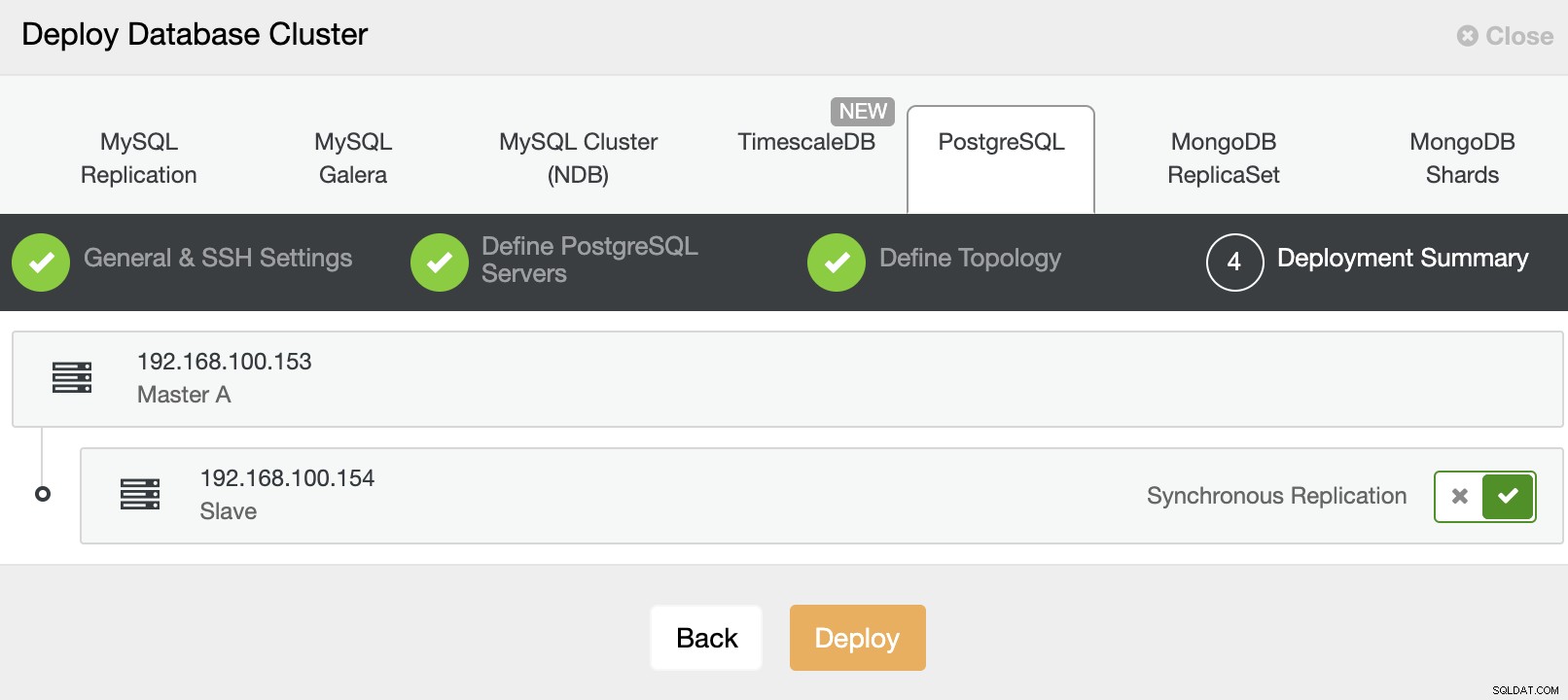
Това е. Можете да наблюдавате състоянието на заданието в секцията за активност на ClusterControl.
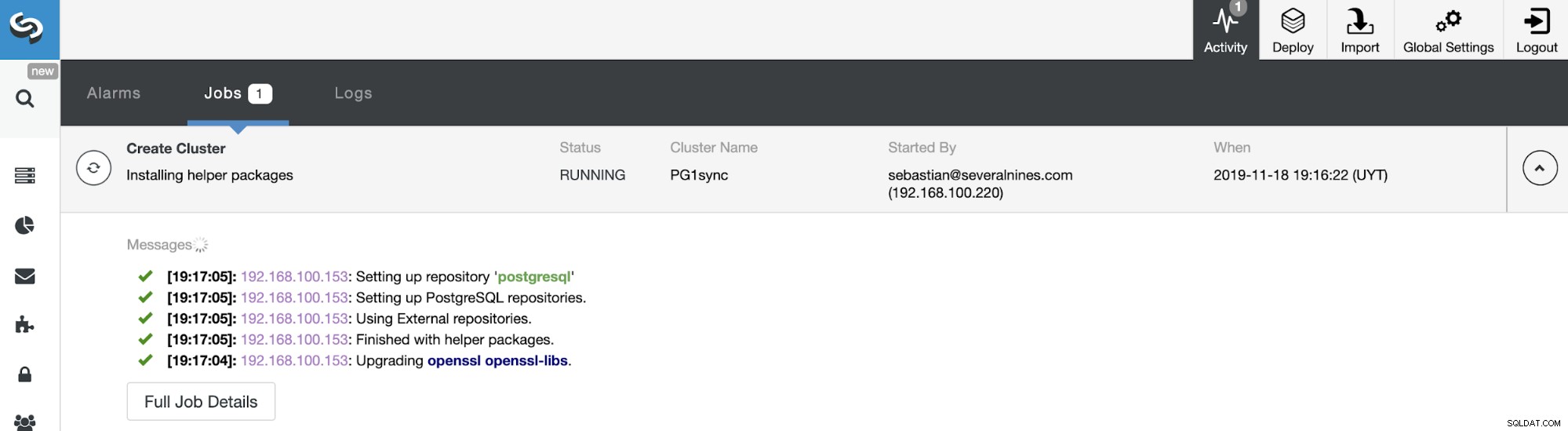
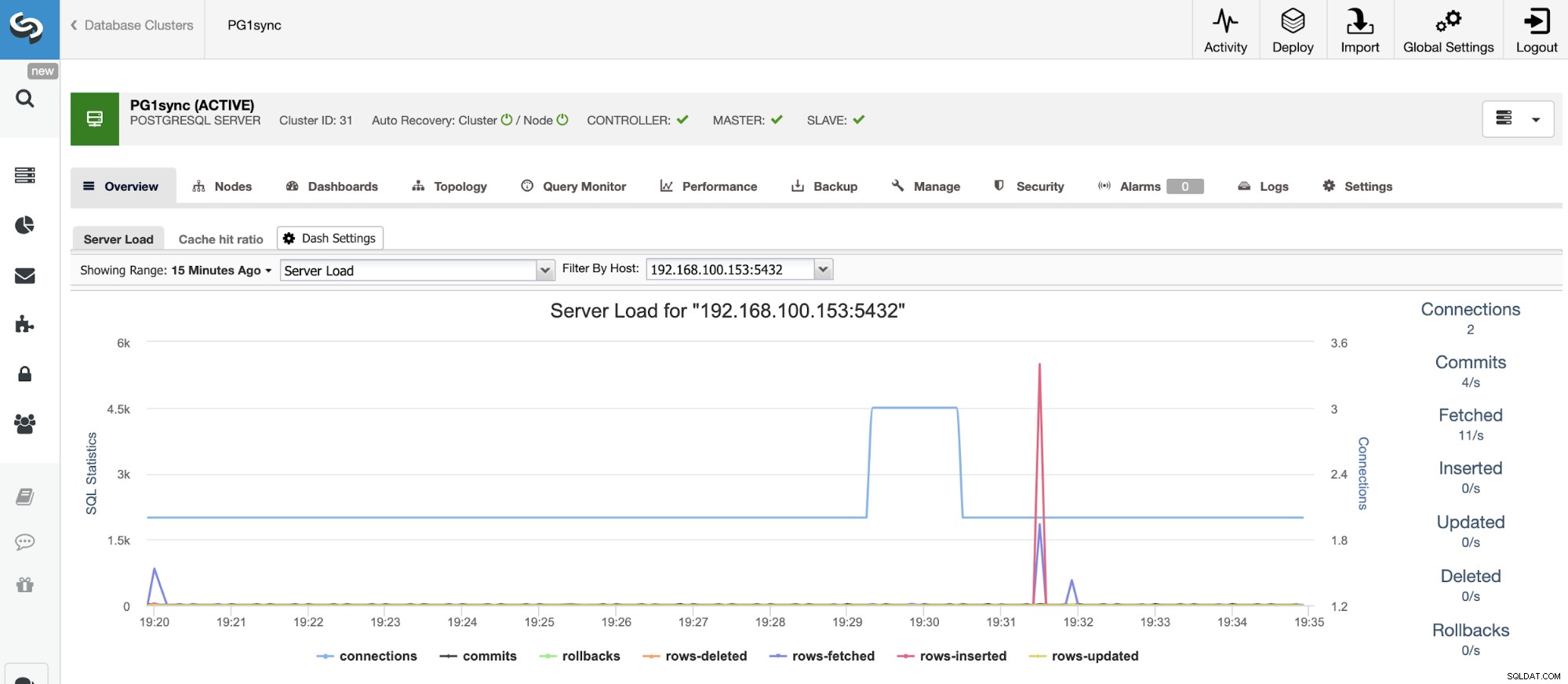
И когато тази задача приключи, ще имате инсталиран вашия PostgreSQL синхронен клъстер, конфигуриран и наблюдаван от ClusterControl.
Заключение
Както споменахме в началото на този блог, високата наличност е изискване за всички компании, така че трябва да знаете наличните опции, за да го постигнете за всяка използвана технология. За PostgreSQL можете да използвате синхронно стрийминг репликация като най-сигурния начин за прилагането му, но този метод не работи за всички среди и работни натоварвания.
Внимавайте с латентността, генерирана от изчакването на потвърждението на всяка транзакция, която може да бъде проблем вместо решение с висока достъпност.