Повечето OLTP работни натоварвания включват произволно използване на I/O диск. Знаейки, че дисковете (включително SSD) са с по-бавна производителност от използването на RAM, системите за бази данни използват кеширане, за да увеличат производителността. Кеширането е свързано с съхраняване на данни в паметта (RAM) за по-бърз достъп в по-късен момент.
PostgreSQL също така използва кеширане на своите данни в пространство, наречено shared_buffers. В този блог ще разгледаме тази функционалност, за да ви помогнем да увеличите производителността.
Основи на кеширането на PostgreSQL
Преди да навлезем по-задълбочено в концепцията за кеширане, нека да разгледаме основите.
В PostgreSQL данните са организирани под формата на страници с размер 8KB и всяка такава страница може да съдържа множество кортежи (в зависимост от размера на кортежа). Опростеното представяне може да бъде като по-долу:
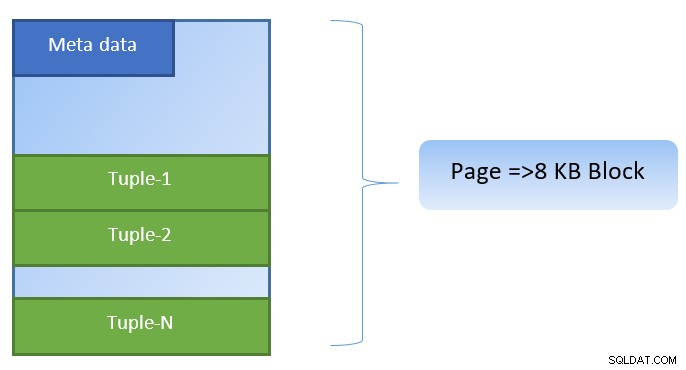
PostgreSQL кешира следното за ускоряване на достъпа до данни:
- Данни в таблици
- Индекси
- Планове за изпълнение на заявка
Докато фокусът на кеширането на плана за изпълнение на заявката е върху запазването на цикли на процесора; Кеширането за данни от таблици и данни за индекси е насочено към спестяване на скъпоструващи операции за вход/изход на диска.
PostgreSQL позволява на потребителите да определят колко памет биха искали да резервират за запазване на такъв кеш за данни. Съответната настройка е shared_buffers в конфигурационния файл postgresql.conf. Крайната стойност на shared_buffers определя колко страници могат да бъдат кеширани във всеки един момент от време.
При изпълнение на заявка PostgreSQL търси страницата на диска, която съдържа съответния кортеж, и я избутва в кеша shared_buffers за страничен достъп. Следващия път, когато трябва да се осъществи достъп до същия кортеж (или който и да е кортеж на същата страница), PostgreSQL може да запази дисково IO, като го прочете в паметта.
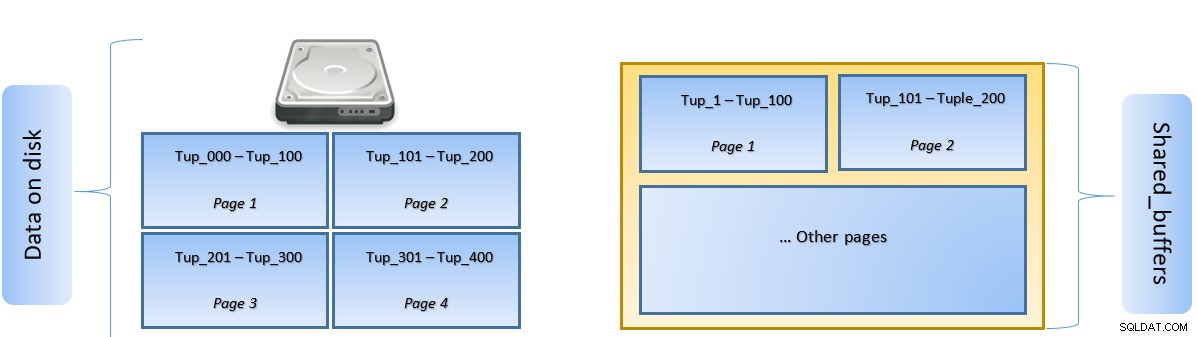
На горната фигура страница-1 и страница-2 на определен таблицата са кеширани. В случай, че потребителска заявка трябва да получи достъп до кортежи между Tuple-1 до Tuple-200, PostgreSQL може да го извлече от самата RAM.
Ако обаче заявката трябва да получи достъп до кортежи от 250 до 350, тя ще трябва да извърши дисков I/O за страница 3 и страница 4. Всеки по-нататъшен достъп за кортеж 201 до 400 ще бъде извлечен от кеша и дисков вход/изход няма да е необходим – по този начин заявката става по-бърза.
На високо ниво PostgreSQL следва LRU (най-малко използван) алгоритъм за идентифициране на страниците, които трябва да бъдат извадени от кеша. С други думи, страница, която е достъпна само веднъж, има по-високи шансове за изгонване (в сравнение със страница, която е достъпна многократно), в случай че нова страница трябва да бъде извлечена от PostgreSQL в кеша.
Кеширането на PostgreSQL в действие
Нека изпълним пример и да видим влиянието на кеша върху производителността.
Стартирайте PostgreSQL, като задържате shared_buffer на 128 MB по подразбиране
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startСвържете се със сървъра и създайте фиктивна таблица tblDummy и индекс на c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Попълнете фиктивни данни с 200 000 кортежи, така че да има 10 000 уникални p_id и за всеки p_id да има 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Рестартирайте сървъра, за да изчистите кеша. Сега изпълнете заявка и проверете за времето, необходимо за изпълнение на същото
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msСлед това проверете блоковете, прочетени от диска
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0В горния пример имаше 1000 блока, прочетени от диска, за да се намерят кортежи за броене, където c_id =1. Отне 160 ms, тъй като имаше дисков I/O, за да извлече тези записи от диска.
Изпълнението е по-бързо, ако същата заявка се изпълни повторно, тъй като всички блокове все още са в кеша на PostgreSQL сървъра на този етап
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msи блокира четенето от диска спрямо кеша
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Отгоре е видно, че тъй като всички блокове бяха прочетени от кеша и не се изискваше I/O диск. Следователно това също даде по-бързи резултати.
Задаване на размера на кеша на PostgreSQL
Размерът на кеша трябва да бъде настроен в производствена среда в съответствие с количеството налична RAM памет, както и заявките, необходими за изпълнение.
Като пример – shared_buffer от 128MB може да не е достатъчен за кеширане на всички данни, ако заявката трябваше да извлече повече кортежи:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Променете shared_buffer на 1024MB, за да увеличите heap_blks_hit.
Всъщност, като се имат предвид заявките (базирани на c_id), в случай, че данните се реорганизират, по-добро съотношение на попадане в кеша може да се постигне и с по-малък shared_buffer.
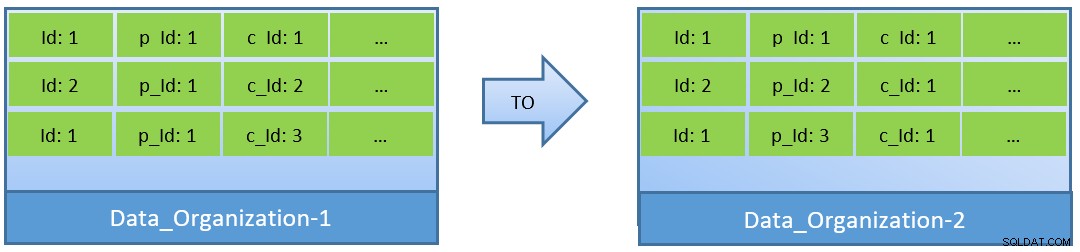
В Data_Organization-1, PostgreSQL ще се нуждае от 1000 четения на блока (и консумация на кеш ) за намиране на c_id=1. От друга страна, за Data_Organisation-2, за същата заявка, PostgreSQL ще се нуждае само от 104 блока.
По-малко блокове, необходими за една и съща заявка, в крайна сметка консумират по-малко кеш и също така поддържат времето за изпълнение на заявката оптимизирано.
Заключение
Докато shared_buffer се поддържа на ниво процес на PostgreSQL, кешът на ниво ядрото също се взема предвид за идентифициране на оптимизирани планове за изпълнение на заявка. Ще разгледам тази тема в по-късна серия от блогове.