Този блог започва многосерийна документация на моето пътуване към сравнителния анализ на PostgreSQL в облака.
Първата част включва преглед на инструментите за сравнителен анализ и дава старт на забавлението с Amazon Aurora PostgreSQL.
Избор на доставчици на PostgreSQL облачни услуги
Преди малко попаднах на процедурата за сравнение на AWS за Aurora и си помислих, че би било наистина страхотно, ако мога да направя този тест и да го стартирам на други доставчици на облачен хостинг. За чест на Amazon, от трите най-известни доставчици на помощни изчисления — AWS, Google и Microsoft — AWS е единственият основен принос в развитието на PostgreSQL и първият, който предлага управлявана услуга PostgreSQL (от ноември 2013 г.).
Докато управляваните PostgreSQL услуги се предлагат и от множество PostgreSQL хостинг доставчици, исках да се съсредоточа върху споменатите три доставчици на облачни изчисления, тъй като техните среди са мястото, където много организации, търсещи предимствата на изчисленията в облак, избират да стартират своите приложения, при условие че имат необходимото ноу-хау за управление на PostgreSQL. Твърдо вярвам, че в днешния ИТ пейзаж организациите, работещи с критични работни натоварвания в облака, биха имали голяма полза от услугите на специализиран доставчик на PostgreSQL услуги, който може да им помогне да се ориентират в сложния свят на GUCS и безброй презентации на SlideShare.
Избор на правилния инструмент за сравнителен анализ
Бенчмаркингът PostgreSQL се появява доста често в пощенския списък за производителност и както се подчертава безброй пъти, тестовете не са предназначени да валидират конфигурация за приложение в реалния живот. Въпреки това, изборът на правилния инструмент за сравнение и параметри са важни, за да се съберат значими резултати. Бих очаквал всеки доставчик на облачни услуги да предостави процедури за сравнителен анализ на своите услуги, особено когато първото изживяване в облака може да не започне на правилния крак. Добрата новина е, че двама от тримата играчи в този тест са включили бенчмаркове в своята документация. Ръководството на AWS Benchmark Procedure for Aurora е лесно за намиране, достъпно направо на страницата Amazon Aurora Resources. Google не предоставя специфично ръководство за PostgreSQL, но документацията на Compute Engine съдържа ръководство за тестване на натоварване за SQL Server, базирано на HammerDB.
Следва обобщение на инструментите за сравнителен анализ, базирани на техните препратки, които си струва да бъдат разгледани:
- Споменатият по-горе AWS Benchmark е базиран на pgbench и sysbench.
- HammerDB, също споменат по-рано, се обсъжда в скорошна публикация в списъка с pgsql-хакери.
- TPC-C тестове, базирани на oltpbench, както е споменато в тази друга дискусия за pgsql-хакери.
- benchmarksql е още един TPC-C тест, който беше използван за валидиране на промените в разделянето на страници B-Tree.
- pg_ycsb е новото дете в града, което подобрява pgbench и вече се използва от някои от хакерите на PostgreSQL.
- pgbench-tools, както подсказва името, е базиран на pgbench и макар да не е получавал никакви актуализации от 2016 г. насам, той е продукт на Грег Смит, автор на книгите за висока производителност на PostgreSQL.
- бенчмаркът за присъединяване е сравнителен показател, който ще тества оптимизатора на заявки.
- pgreplay, на който попаднах, докато четях блога на командния ред, е възможно най-близо до сравнителния анализ на сценарий от реалния живот.
Друг момент, който трябва да се отбележи, е, че PostgreSQL все още не е подходящ за стандарта за сравнение на TPC-H и както беше отбелязано по-горе, всички инструменти (с изключение на pgreplay) трябва да се изпълняват в режим TPC-C (pgbench е по подразбиране за него).
За целите на този блог смятах, че AWS Benchmark процедурата за Aurora е добро начало, просто защото задава стандарт за доставчиците на облак и се основава на широко използвани инструменти.
Освен това използвах най-новата налична версия на PostgreSQL по това време. Когато избирате доставчик на облак, е важно да вземете предвид честотата на надстройки, особено когато важни функции, въведени от новите версии, могат да повлияят на производителността (какъвто е случаят за версии 10 и 11 срещу 9). Към момента на писане имаме:
- Amazon Aurora PostgreSQL 10.6
- Amazon RDS за PostgreSQL 10.6
- Google Cloud SQL за PostgreSQL 9.6
- Microsoft Azure PostgreSQL 10.5
...и победителят тук е AWS, като предлага най-новата версия (въпреки че не е най-новата, която към момента на писане е 11.2).
Настройване на средата за сравнителен анализ
Реших да огранича тестовете си до средни работни натоварвания по няколко причини:Първо, наличните облачни ресурси не са идентични при различните доставчици. В ръководството спецификациите на AWS за екземпляра на базата данни са 64 vCPU / 488 GiB RAM / 25 Gigabit Network, докато максималната RAM на Google за всеки размер на инстанция (изборът трябва да бъде настроен на „персонализиран“ в калкулатора на Google) е 208 GiB, и Business Critical Gen5 на Microsoft с 32 vCPU идва само с 163 GiB). Второ, инициализацията на pgbench довежда размера на базата данни до 160GiB, което в случай на екземпляр с 488 GiB RAM вероятно ще се съхранява в паметта.
Освен това оставих конфигурацията на PostgreSQL недокосната. Причината да се придържаме към настройките по подразбиране на доставчика на облак е, че извън кутията, когато се стресира от стандартен бенчмарк, се очаква управлявана услуга да се представи сравнително добре. Не забравяйте, че общността на PostgreSQL изпълнява pgbench тестове като част от процеса на управление на изданието. Освен това, ръководството на AWS не споменава никакви промени в конфигурацията на PostgreSQL по подразбиране.
Както е обяснено в ръководството, AWS приложи две корекции към pgbench. Тъй като корекцията за броя на клиентите не се прилагаше ясно за 10.6 версия на PostgreSQL и не исках да инвестирам време в коригирането му, броят на клиентите беше ограничен до максимум 1000.
Ръководството посочва изискване клиентският екземпляр да има активирана подобрена мрежа — за този тип екземпляр това е по подразбиране:
[example@sqldat.com ~]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc mq state UP group default qlen 1000
link/ether 0a:cd:ee:40:2b:e6 brd ff:ff:ff:ff:ff:ff
inet 172.31.19.190/20 brd 172.31.31.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::8cd:eeff:fe40:2be6/64 scope link
valid_lft forever preferred_lft forever
[example@sqldat.com ~]$ ethtool -i eth0
driver: ena
version: 2.0.2g
firmware-version:
bus-info: 0000:00:03.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
>>> aws (master *%) ~ $ aws ec2 describe-instances --instance-ids i-0ee51642334c1ec57 --query "Reservations[].Instances[].EnaSupport"
[
true
]Изпълнение на бенчмарка на Amazon Aurora PostgreSQL
По време на действителното бягане реших да направя още едно отклонение от ръководството:вместо да изпълнявам теста за 1 час, задайте времевото ограничение на 10 минути, което обикновено се приема като добра стойност.
Изпълнете #1
Специфични характеристики
- Този тест използва спецификациите на AWS както за размера на екземпляра на клиента, така и за базата данни.
- Клиентска машина:Оптимизиран EC2 екземпляр за памет при поискване:
- vCPU:32 (16 ядра x 2 нишки/ядро)
- RAM:244 GiB
- Съхранение:EBS оптимизирано
- Мрежа:10 гигабита
- DB клъстер:db.r4.16xlarge
- vCPU:64
- ECU (капацитет на процесора):195 x [1,0-1,2 GHz] Opteron/Xeon 2007 г.
- RAM:488 GiB
- Съхранение:Оптимизиран EBS (Специален капацитет за I/O)
- Мрежа:14 000 Mbps максимална честотна лента в 25 Gps мрежа
- Клиентска машина:Оптимизиран EC2 екземпляр за памет при поискване:
- Настройката на базата данни включва една реплика.
- Съхранението на базата данни не беше шифровано.
Извършване на тестове и резултати
- Следвайте инструкциите в ръководството, за да инсталирате pgbench и sysbench.
- Редактирайте ~/.bashrc, за да зададете променливите на средата за връзката към базата данни и необходимите пътища към библиотеките на PostgreSQL:
export PGHOST=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com export PGUSER=postgres export PGPASSWORD=postgres export PGDATABASE=postgres export PATH=$PATH:/usr/local/pgsql/bin export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/lib - Инициализирайте базата данни:
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000 NOTICE: table "pgbench_history" does not exist, skipping NOTICE: table "pgbench_tellers" does not exist, skipping NOTICE: table "pgbench_accounts" does not exist, skipping NOTICE: table "pgbench_branches" does not exist, skipping creating tables... 100000 of 1000000000 tuples (0%) done (elapsed 0.05 s, remaining 457.23 s) 200000 of 1000000000 tuples (0%) done (elapsed 0.13 s, remaining 631.70 s) 300000 of 1000000000 tuples (0%) done (elapsed 0.21 s, remaining 688.29 s) ... 999500000 of 1000000000 tuples (99%) done (elapsed 811.41 s, remaining 0.41 s) 999600000 of 1000000000 tuples (99%) done (elapsed 811.50 s, remaining 0.32 s) 999700000 of 1000000000 tuples (99%) done (elapsed 811.58 s, remaining 0.24 s) 999800000 of 1000000000 tuples (99%) done (elapsed 811.65 s, remaining 0.16 s) 999900000 of 1000000000 tuples (99%) done (elapsed 811.73 s, remaining 0.08 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 811.80 s, remaining 0.00 s) vacuum... set primary keys... done. - Проверете размера на базата данни:
postgres=> \l+ postgres List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description ----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------------------------------------- postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 160 GB | pg_default | default administrative connection database (1 row) - Използвайте следната заявка, за да проверите дали интервалът от време между контролните точки е зададен, така че контролните точки да бъдат принудени по време на 10-минутното изпълнение:
Резултат:SELECT total_checkpoints, seconds_since_start / total_checkpoints / 60 AS minutes_between_checkpoints FROM ( SELECT EXTRACT( EPOCH FROM ( now() - pg_postmaster_start_time() ) ) AS seconds_since_start, (checkpoints_timed+checkpoints_req) AS total_checkpoints FROM pg_stat_bgwriter) AS sub;postgres=> \e total_checkpoints | minutes_between_checkpoints -------------------+----------------------------- 50 | 0.977392292333333 (1 row) - Изпълнете работното натоварване за четене/запис:
Изход[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048starting vacuum...end. progress: 60.0 s, 35670.3 tps, lat 27.243 ms stddev 10.915 progress: 120.0 s, 36569.5 tps, lat 27.352 ms stddev 11.859 progress: 180.0 s, 35845.2 tps, lat 27.896 ms stddev 12.785 progress: 240.0 s, 36613.7 tps, lat 27.310 ms stddev 11.804 progress: 300.0 s, 37323.4 tps, lat 26.793 ms stddev 11.376 progress: 360.0 s, 36828.8 tps, lat 27.155 ms stddev 11.318 progress: 420.0 s, 36670.7 tps, lat 27.268 ms stddev 12.083 progress: 480.0 s, 37176.1 tps, lat 26.899 ms stddev 10.981 progress: 540.0 s, 37210.8 tps, lat 26.875 ms stddev 11.341 progress: 600.0 s, 37415.4 tps, lat 26.727 ms stddev 11.521 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 22040445 latency average = 27.149 ms latency stddev = 11.617 ms tps = 36710.828624 (including connections establishing) tps = 36811.054851 (excluding connections establishing) - Подгответе теста на sysbench:
Изход:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250\ --oltp-table-size=450000 \ preparesysbench 0.5: multi-threaded system evaluation benchmark Creating table 'sbtest1'... Inserting 450000 records into 'sbtest1' Creating secondary indexes on 'sbtest1'... Creating table 'sbtest2'... ... Creating table 'sbtest250'... Inserting 450000 records into 'sbtest250' Creating secondary indexes on 'sbtest250'... - Изпълнете теста на sysbench:
Изход:sysbench --test=/usr/local/share/sysbench/oltp.lua \ --pgsql-host=aurora.cluster-ctfirtyhadgr.us-east-1.rds.amazonaws.com \ --pgsql-db=postgres \ --pgsql-user=postgres \ --pgsql-password=postgres \ --pgsql-port=5432 \ --oltp-tables-count=250 \ --oltp-table-size=450000 \ --max-requests=0 \ --forced-shutdown \ --report-interval=60 \ --oltp_simple_ranges=0 \ --oltp-distinct-ranges=0 \ --oltp-sum-ranges=0 \ --oltp-order-ranges=0 \ --oltp-point-selects=0 \ --rand-type=uniform \ --max-time=600 \ --num-threads=1000 \ runsysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 20443.09, reads: 0.00, writes: 81834.16, response time: 68.24ms (95%), errors: 0.62, reconnects: 0.00 [ 120s] threads: 1000, tps: 20580.68, reads: 0.00, writes: 82324.33, response time: 70.75ms (95%), errors: 0.73, reconnects: 0.00 [ 180s] threads: 1000, tps: 20531.85, reads: 0.00, writes: 82127.21, response time: 70.63ms (95%), errors: 0.73, reconnects: 0.00 [ 240s] threads: 1000, tps: 20212.67, reads: 0.00, writes: 80861.67, response time: 71.99ms (95%), errors: 0.43, reconnects: 0.00 [ 300s] threads: 1000, tps: 19383.90, reads: 0.00, writes: 77537.87, response time: 75.64ms (95%), errors: 0.75, reconnects: 0.00 [ 360s] threads: 1000, tps: 19797.20, reads: 0.00, writes: 79190.78, response time: 75.27ms (95%), errors: 0.68, reconnects: 0.00 [ 420s] threads: 1000, tps: 20304.43, reads: 0.00, writes: 81212.87, response time: 73.82ms (95%), errors: 0.70, reconnects: 0.00 [ 480s] threads: 1000, tps: 20933.80, reads: 0.00, writes: 83737.16, response time: 74.71ms (95%), errors: 0.68, reconnects: 0.00 [ 540s] threads: 1000, tps: 20663.05, reads: 0.00, writes: 82626.42, response time: 73.56ms (95%), errors: 0.75, reconnects: 0.00 [ 600s] threads: 1000, tps: 20746.02, reads: 0.00, writes: 83015.81, response time: 73.58ms (95%), errors: 0.78, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 48868458 other: 24434022 total: 73302480 transactions: 12216804 (20359.59 per sec.) read/write requests: 48868458 (81440.43 per sec.) other operations: 24434022 (40719.87 per sec.) ignored errors: 414 (0.69 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0516s total number of events: 12216804 total time taken by event execution: 599964.4735s response time: min: 6.27ms avg: 49.11ms max: 350.24ms approx. 95 percentile: 72.90ms Threads fairness: events (avg/stddev): 12216.8040/31.27 execution time (avg/stddev): 599.9645/0.01
Събрани показатели
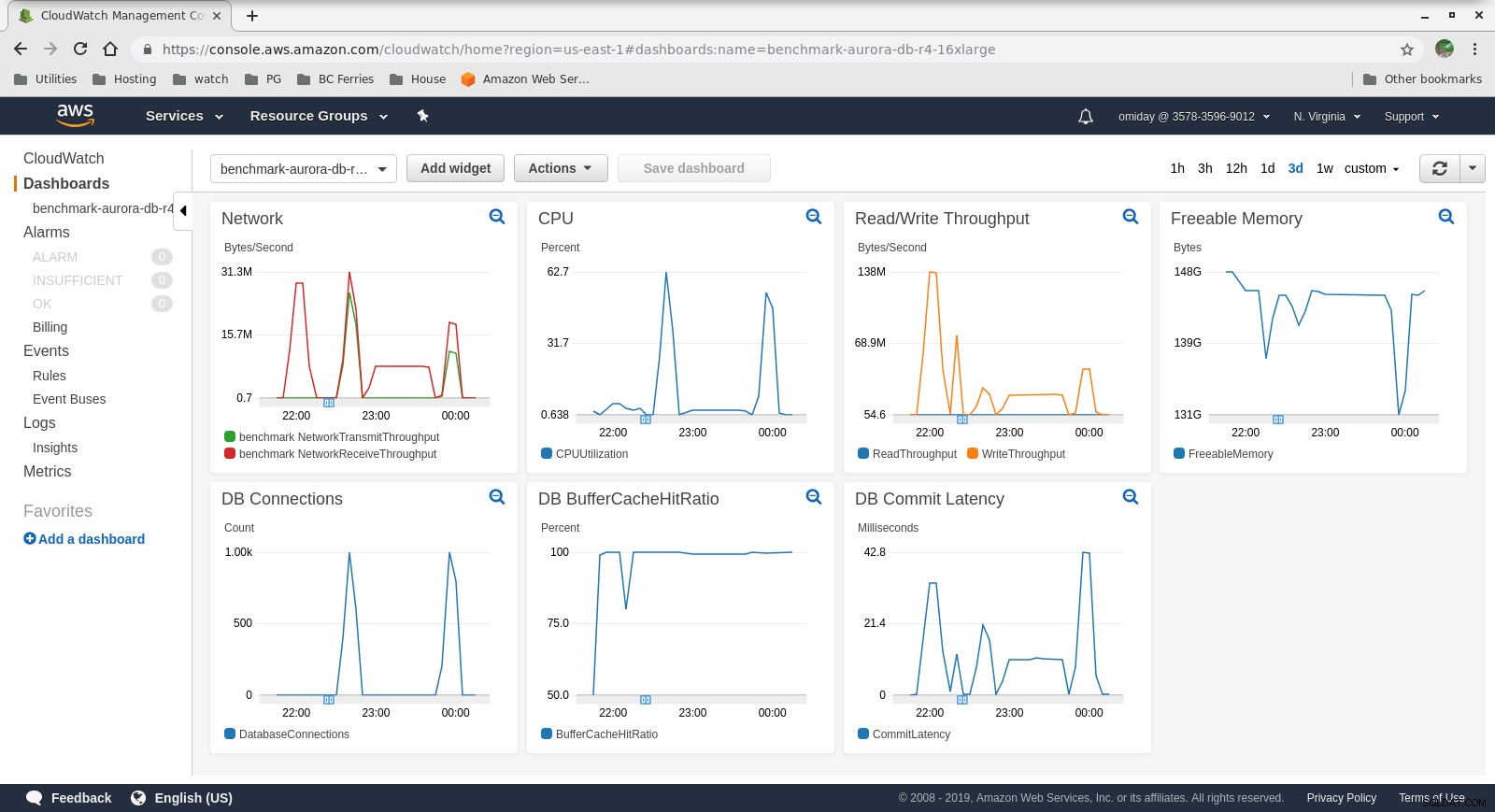 Показатели на Cloudwatch
Показатели на Cloudwatch 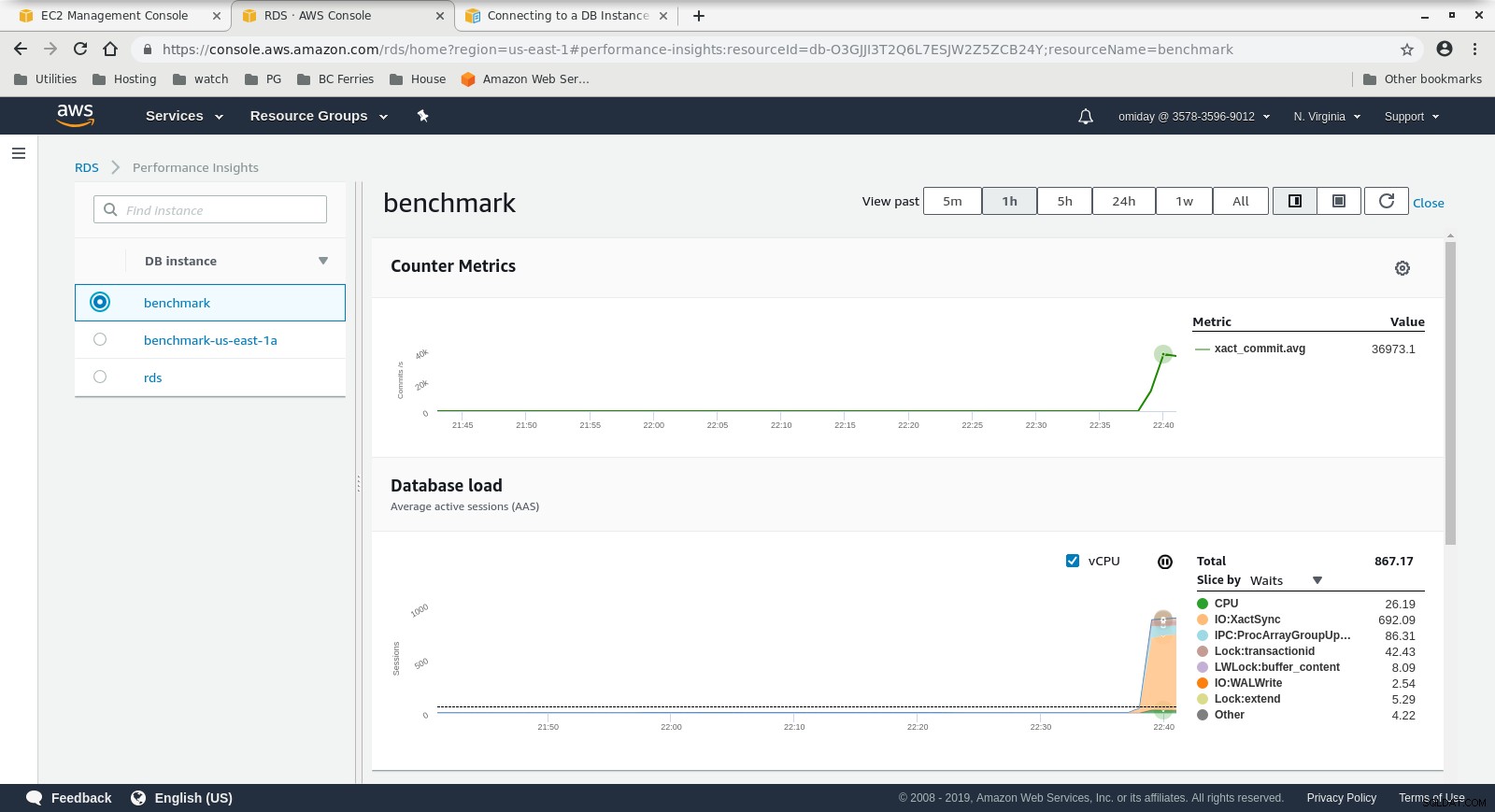 Показатели на производителността Изтеглете Бялата книга днес PostgreSQL Management &Automation с ClusterControl, научете за това, от което се нуждаете, за да наблюдавате управлявайте и мащабирайте PostgreSQLD Изтеглете Бялата книга
Показатели на производителността Изтеглете Бялата книга днес PostgreSQL Management &Automation с ClusterControl, научете за това, от което се нуждаете, за да наблюдавате управлявайте и мащабирайте PostgreSQLD Изтеглете Бялата книга Изпълнете #2
Специфични характеристики
- Този тест използва спецификациите на AWS за клиента и по-малък размер на екземпляра за базата данни:
- Клиентска машина:Оптимизиран EC2 екземпляр за памет при поискване:
- vCPU:32 (16 ядра x 2 нишки/ядро)
- RAM:244 GiB
- Съхранение:EBS оптимизирано
- Мрежа:10 гигабита
- DB клъстер:db.r4.2xlarge:
- vCPU:8
- RAM:61 GiB
- Съхранение:EBS оптимизирано
- Мрежа:1750 Mbps максимална честотна лента при връзка до 10 Gbps
- Клиентска машина:Оптимизиран EC2 екземпляр за памет при поискване:
- Базата данни не включва реплика.
- Съхранението на базата данни не беше шифровано.
Извършване на тестове и резултати
Стъпките са идентични с Run #1, така че показвам само изхода:
-
pgbench Работно натоварване за четене/запис:
... 745700000 of 1000000000 tuples (74%) done (elapsed 794.93 s, remaining 271.09 s) 745800000 of 1000000000 tuples (74%) done (elapsed 795.00 s, remaining 270.97 s) 745900000 of 1000000000 tuples (74%) done (elapsed 795.09 s, remaining 270.86 s) 746000000 of 1000000000 tuples (74%) done (elapsed 795.17 s, remaining 270.74 s) 746100000 of 1000000000 tuples (74%) done (elapsed 795.24 s, remaining 270.62 s) 746200000 of 1000000000 tuples (74%) done (elapsed 795.33 s, remaining 270.51 s) ... 999800000 of 1000000000 tuples (99%) done (elapsed 1067.11 s, remaining 0.21 s) 999900000 of 1000000000 tuples (99%) done (elapsed 1067.19 s, remaining 0.11 s) 1000000000 of 1000000000 tuples (100%) done (elapsed 1067.28 s, remaining 0.00 s) vacuum... set primary keys... total time: 4386.44 s (insert 1067.33 s, commit 0.46 s, vacuum 2088.25 s, index 1230.41 s) done.starting vacuum...end. progress: 60.0 s, 3361.3 tps, lat 286.143 ms stddev 80.417 progress: 120.0 s, 3466.8 tps, lat 288.386 ms stddev 76.373 progress: 180.0 s, 3683.1 tps, lat 271.840 ms stddev 75.712 progress: 240.0 s, 3444.3 tps, lat 289.909 ms stddev 69.564 progress: 300.0 s, 3475.8 tps, lat 287.736 ms stddev 73.712 progress: 360.0 s, 3449.5 tps, lat 289.832 ms stddev 71.878 progress: 420.0 s, 3518.1 tps, lat 284.432 ms stddev 74.276 progress: 480.0 s, 3430.7 tps, lat 291.359 ms stddev 73.264 progress: 540.0 s, 3515.7 tps, lat 284.522 ms stddev 73.206 progress: 600.0 s, 3482.9 tps, lat 287.037 ms stddev 71.649 transaction type: <builtin: TPC-B (sort of)> scaling factor: 10000 query mode: prepared number of clients: 1000 number of threads: 1000 duration: 600 s number of transactions actually processed: 2090702 latency average = 286.030 ms latency stddev = 74.245 ms tps = 3481.731730 (including connections establishing) tps = 3494.157830 (excluding connections establishing) -
Sysbench тест:
sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 1000 Report intermediate results every 60 second(s) Random number generator seed is 0 and will be ignored Forcing shutdown in 630 seconds Initializing worker threads... Threads started! [ 60s] threads: 1000, tps: 4809.05, reads: 0.00, writes: 19301.02, response time: 288.03ms (95%), errors: 0.05, reconnects: 0.00 [ 120s] threads: 1000, tps: 5264.15, reads: 0.00, writes: 21005.40, response time: 255.23ms (95%), errors: 0.08, reconnects: 0.00 [ 180s] threads: 1000, tps: 5178.27, reads: 0.00, writes: 20713.07, response time: 260.40ms (95%), errors: 0.03, reconnects: 0.00 [ 240s] threads: 1000, tps: 5145.95, reads: 0.00, writes: 20610.08, response time: 255.76ms (95%), errors: 0.05, reconnects: 0.00 [ 300s] threads: 1000, tps: 5127.92, reads: 0.00, writes: 20507.98, response time: 264.24ms (95%), errors: 0.05, reconnects: 0.00 [ 360s] threads: 1000, tps: 5063.83, reads: 0.00, writes: 20278.10, response time: 268.55ms (95%), errors: 0.05, reconnects: 0.00 [ 420s] threads: 1000, tps: 5057.51, reads: 0.00, writes: 20237.28, response time: 269.19ms (95%), errors: 0.10, reconnects: 0.00 [ 480s] threads: 1000, tps: 5036.32, reads: 0.00, writes: 20139.29, response time: 279.62ms (95%), errors: 0.10, reconnects: 0.00 [ 540s] threads: 1000, tps: 5115.25, reads: 0.00, writes: 20459.05, response time: 264.64ms (95%), errors: 0.08, reconnects: 0.00 [ 600s] threads: 1000, tps: 5124.89, reads: 0.00, writes: 20510.07, response time: 265.43ms (95%), errors: 0.10, reconnects: 0.00 OLTP test statistics: queries performed: read: 0 write: 12225686 other: 6112822 total: 18338508 transactions: 3056390 (5093.75 per sec.) read/write requests: 12225686 (20375.20 per sec.) other operations: 6112822 (10187.57 per sec.) ignored errors: 42 (0.07 per sec.) reconnects: 0 (0.00 per sec.) General statistics: total time: 600.0277s total number of events: 3056390 total time taken by event execution: 600005.2104s response time: min: 9.57ms avg: 196.31ms max: 608.70ms approx. 95 percentile: 268.71ms Threads fairness: events (avg/stddev): 3056.3900/67.44 execution time (avg/stddev): 600.0052/0.01
Събрани показатели
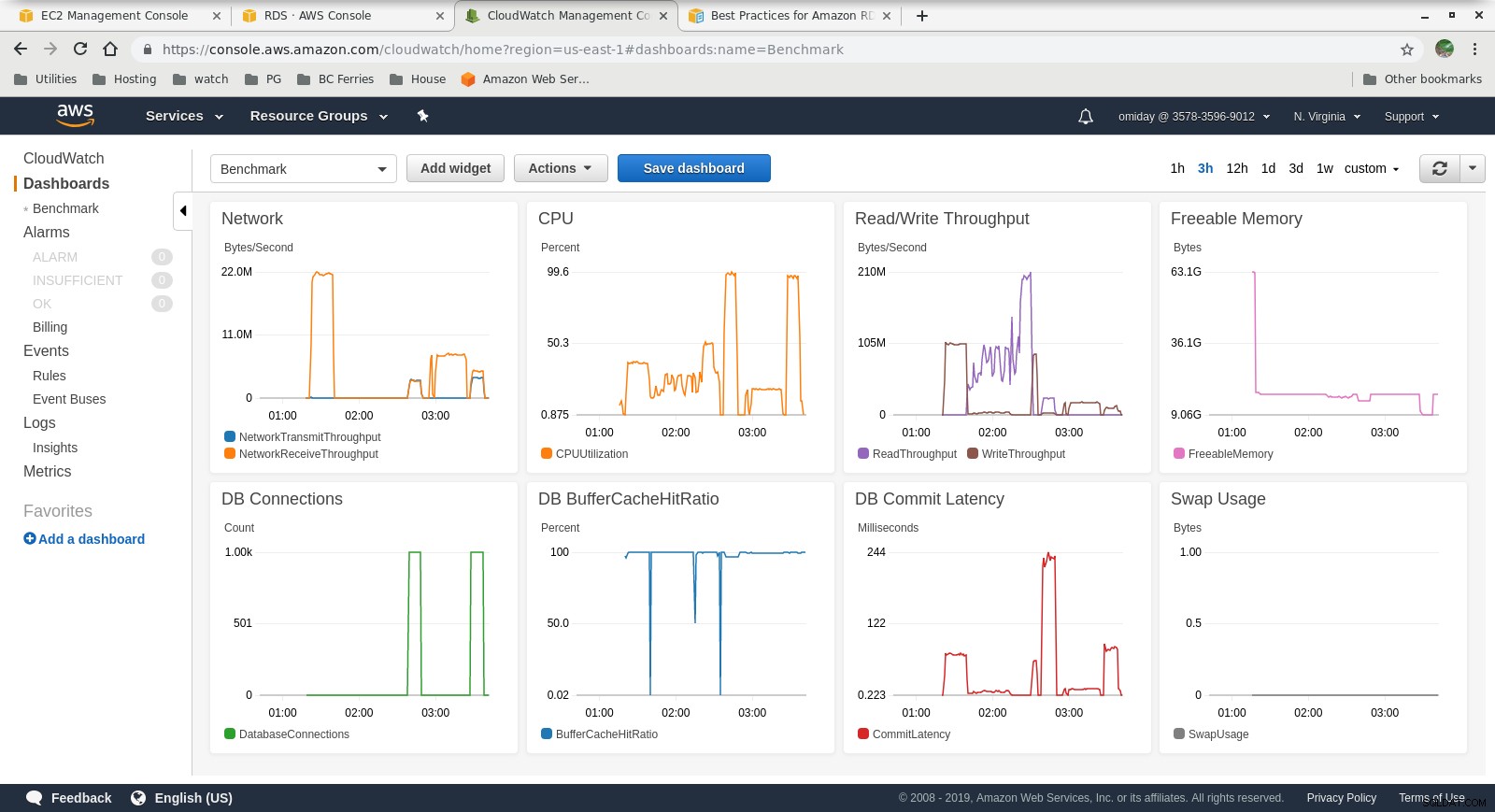 Показатели на Cloudwatch
Показатели на Cloudwatch 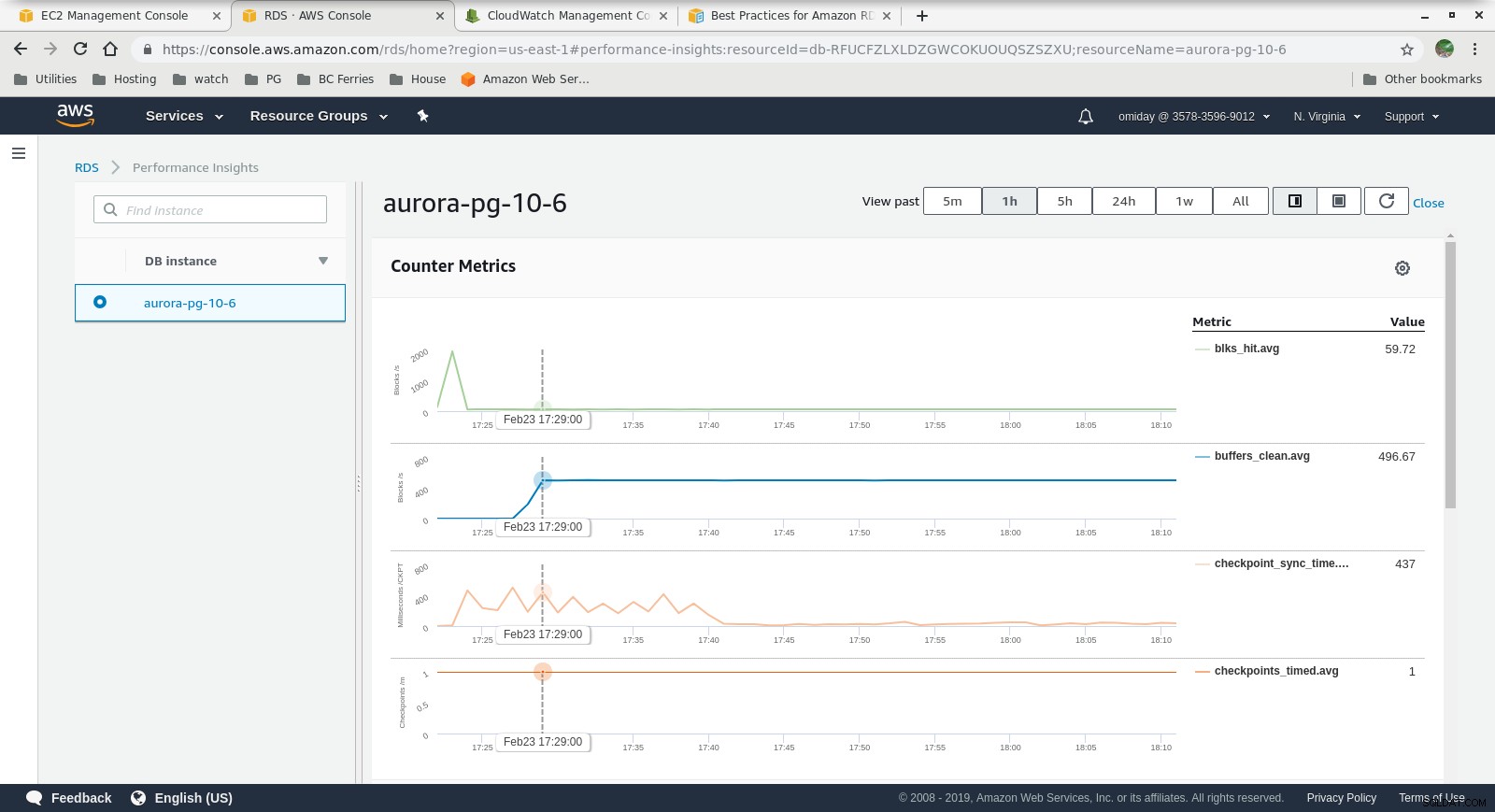 Статистика за производителността – Показатели на брояча
Статистика за производителността – Показатели на брояча 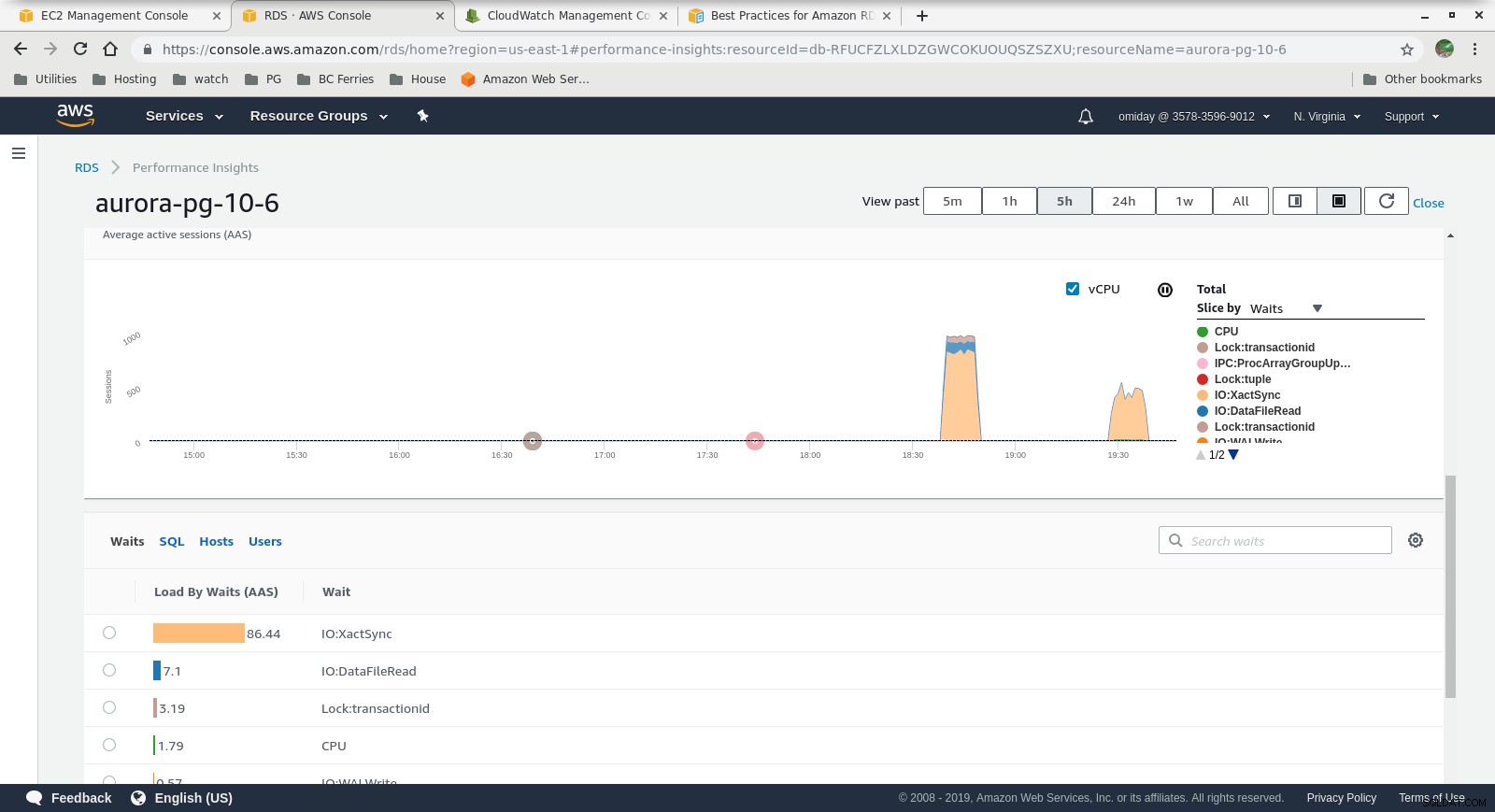 Информация за производителността – Зареждане на базата данни по изчаквания
Информация за производителността – Зареждане на базата данни по изчаквания Последни мисли
- Потребителите са ограничени до използване на предварително определени размери на екземпляра. Като недостатък, ако бенчмаркът показва, че моделът може да се възползва от допълнителна памет, не е възможно „просто да добавите още RAM“. Добавянето на повече памет води до увеличаване на размера на екземпляра, което идва с по-висока цена (цената се удвоява за всеки размер на екземпляра).
- Механизмът за съхранение на Amazon Aurora е много по-различен от RDS и е изграден върху хардуера на SAN. Показателите за I/O пропускателна способност на екземпляр показват, че тестът не се е доближил дори по-близо до максимума за предоставените обеми на IOPS SSD EBS от 1750 MiB/s.
- Допълнителна настройка може да се извърши чрез преглед на събитията на AWS PostgreSQL, включени в графиките на Performance Insights.
Следващо в серия
Очаквайте следващата част:Amazon RDS за PostgreSQL 10.6.