Познаването на репликацията е задължително за всеки, който управлява бази данни. Това е тема, която вероятно сте виждали отново и отново, но никога не остарява. В този блог ще прегледаме малко от историята на вградените функции за репликация на PostgreSQL и ще се потопим дълбоко в това как работи стрийминг репликацията.
Когато говорим за репликация, ще говорим много за WAL. И така, нека набързо да прегледаме малко за регистрационните файлове с предварителна запис.
Регистър за предварителна запис (WAL)
Регистърът с предварителна запис е стандартен метод за гарантиране на целостта на данните и се активира автоматично по подразбиране.
WAL са REDO регистрационните файлове в PostgreSQL. Но какво точно представляват REDO регистрационните файлове?
Регистраторите на REDO съдържат всички промени, направени в базата данни, и се използват за репликация, възстановяване, онлайн архивиране и възстановяване в момента (PITR). Всички промени, които не са били приложени към страниците с данни, могат да бъдат направени отново от REDO регистрационните файлове.
Използването на WAL води до значително намален брой записвания на диск, тъй като само регистрационният файл трябва да бъде изтрит на диска, за да се гарантира, че транзакцията е ангажирана, а не всеки файл с данни, променен от транзакцията.
WAL запис ще указва промените, направени в данните, бит по бит. Всеки WAL запис ще бъде добавен към WAL файл. Позицията на вмъкване е пореден номер на регистрационния файл (LSN), изместване на байта в регистрационните файлове, което се увеличава с всеки нов запис.
WAL-ите се съхраняват в директорията pg_wal (или pg_xlog във версии на PostgreSQL <10) под директорията с данни. Тези файлове имат размер по подразбиране от 16MB (можете да промените размера, като промените опцията за конфигуриране --with-wal-segsize при изграждането на сървъра). Те имат уникално постепенно име в следния формат:„00000001 00000000 00000000“.
Броят WAL файлове, съдържащи се в pg_wal, ще зависи от стойността, присвоена на параметъра checkpoint_segments (или min_wal_size и max_wal_size, в зависимост от версията) в конфигурационния файл postgresql.conf.
Един параметър, който трябва да настроите, когато конфигурирате всичките си инсталации на PostgreSQL, е wal_level. wal_level определя колко информация се записва в WAL. Стойността по подразбиране е минимална, която записва само информацията, необходима за възстановяване след срив или незабавно изключване. Архивът добавя регистрация, необходима за WAL архивиране; hot_standby допълнително добавя информация, необходима за изпълнение на заявки само за четене на сървър в режим на готовност; logical добавя информация, необходима за поддържане на логическото декодиране. Този параметър изисква рестартиране, така че може да е трудно да се промени при работещи производствени бази данни, ако сте го забравили.
За повече информация можете да проверите официалната документация тук или тук. След като покрихме WAL, нека прегледаме историята на репликацията в PostgreSQL.
История на репликацията в PostgreSQL
Първият метод за репликация (топъл режим на готовност), който PostgreSQL внедри (версия 8.2, през 2006 г.), се основава на метода за доставка на регистрационни файлове.
Това означава, че WAL записите се преместват директно от един сървър на база данни на друг, за да бъдат приложени. Можем да кажем, че е непрекъснат PITR.
PostgreSQL внедрява базирано на файлове транспортиране на журнали, като прехвърля WAL записи един файл (WAL сегмент) наведнъж.
Това внедряване на репликация има недостатъка:ако има голяма повреда на основните сървъри, транзакциите, които все още не са изпратени, ще бъдат загубени. И така, има прозорец за загуба на данни (можете да настроите това, като използвате параметъра archive_timeout, който може да бъде настроен на само няколко секунди. Въпреки това, такава ниска настройка значително ще увеличи честотната лента, необходима за изпращане на файлове).
Можем да представим този базиран на файлове метод за доставка на регистрационни файлове със снимката по-долу:
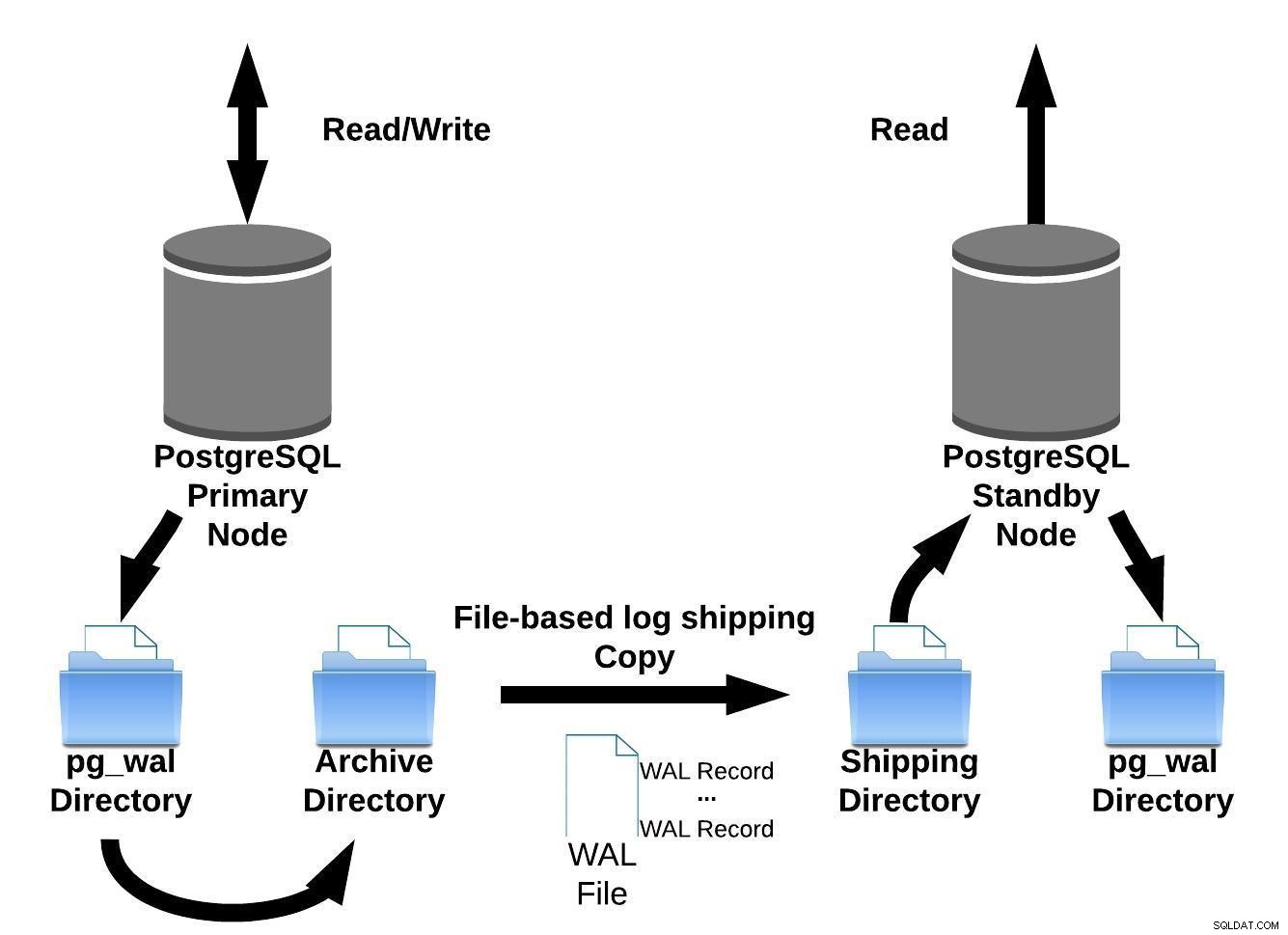 Базирана на PostgreSQL файлове доставка на дневници
Базирана на PostgreSQL файлове доставка на дневнициСлед това във версия 9.0 (назад през 2010 г. ), беше въведена поточно репликация.
Репликацията на поточно предаване ви позволява да бъдете по-актуални, отколкото е възможно с доставката на регистрационни файлове, базирана на файлове. Това работи чрез прехвърляне на WAL записи (WAL файлът се състои от WAL записи) в движение (прехвърляне на дневници, базирани на записи) между основен сървър и един или няколко резервни сървъра, без да се чака запълването на WAL файла.
На практика процес, наречен WAL приемник, работещ на сървъра в режим на готовност, ще се свърже с основния сървър чрез TCP/IP връзка. В основния сървър съществува друг процес, наречен WAL sender, и отговаря за изпращането на WAL регистрите до сървъра в режим на готовност, когато се случват.
Следната диаграма представя поточно репликация:
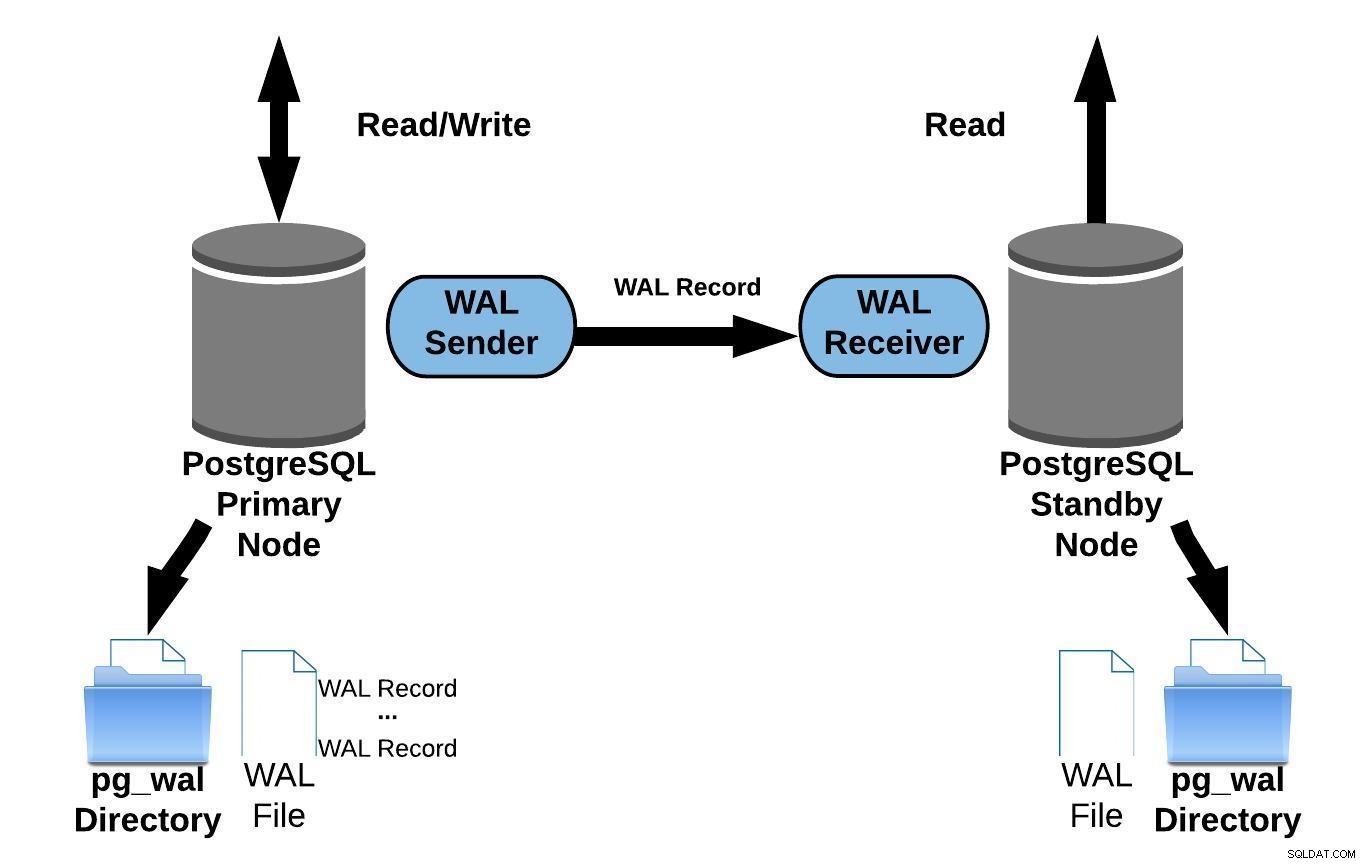 Поточно репликация на PostgreSQL
Поточно репликация на PostgreSQLРазглеждайки горната диаграма, може да се чудите какво се случва когато комуникацията между подателя на WAL и получателя на WAL се провали?
Когато конфигурирате поточно репликация, имате опцията да активирате WAL архивиране.
Тази стъпка не е задължителна, но е изключително важна за стабилна настройка на репликация. Необходимо е да се избягва рециклирането на стари WAL файлове от главния сървър, които все още не са приложени към сървъра в режим на готовност. Ако това се случи, ще трябва да пресъздадете репликата от нулата.
Когато конфигурирате репликация с непрекъснато архивиране, тя започва от резервно копие. За да достигне състоянието на синхронизиране с основния, той трябва да приложи всички промени, хоствани в WAL, които са се случили след архивирането. По време на този процес, режимът на готовност първо ще възстанови всички налични WAL в местоположението на архива (направено чрез извикване на restore_command). Restore_command ще се провали, когато достигне последния архивиран WAL запис, така че след това режимът на готовност ще търси в директорията pg_wal, за да види дали промяната съществува там (това работи, за да се избегне загуба на данни при срив на основните сървъри и някои промени, които вече са преместени и приложени към репликата, все още не са архивирани).
Ако това не успее и исканият запис не съществува там, той ще започне да комуникира с основния сървър чрез поточно репликация.
Когато стрийминг репликацията не успее, тя ще се върне към стъпка 1 и ще възстанови отново записите от архива. Този цикъл от повторни опити от архива, pg_wal, и чрез стрийминг репликация продължава, докато сървърът спре или превъртането на отказ се задейства от задействащ файл.
Следната диаграма представя конфигурация за поточно репликация с непрекъснато архивиране:
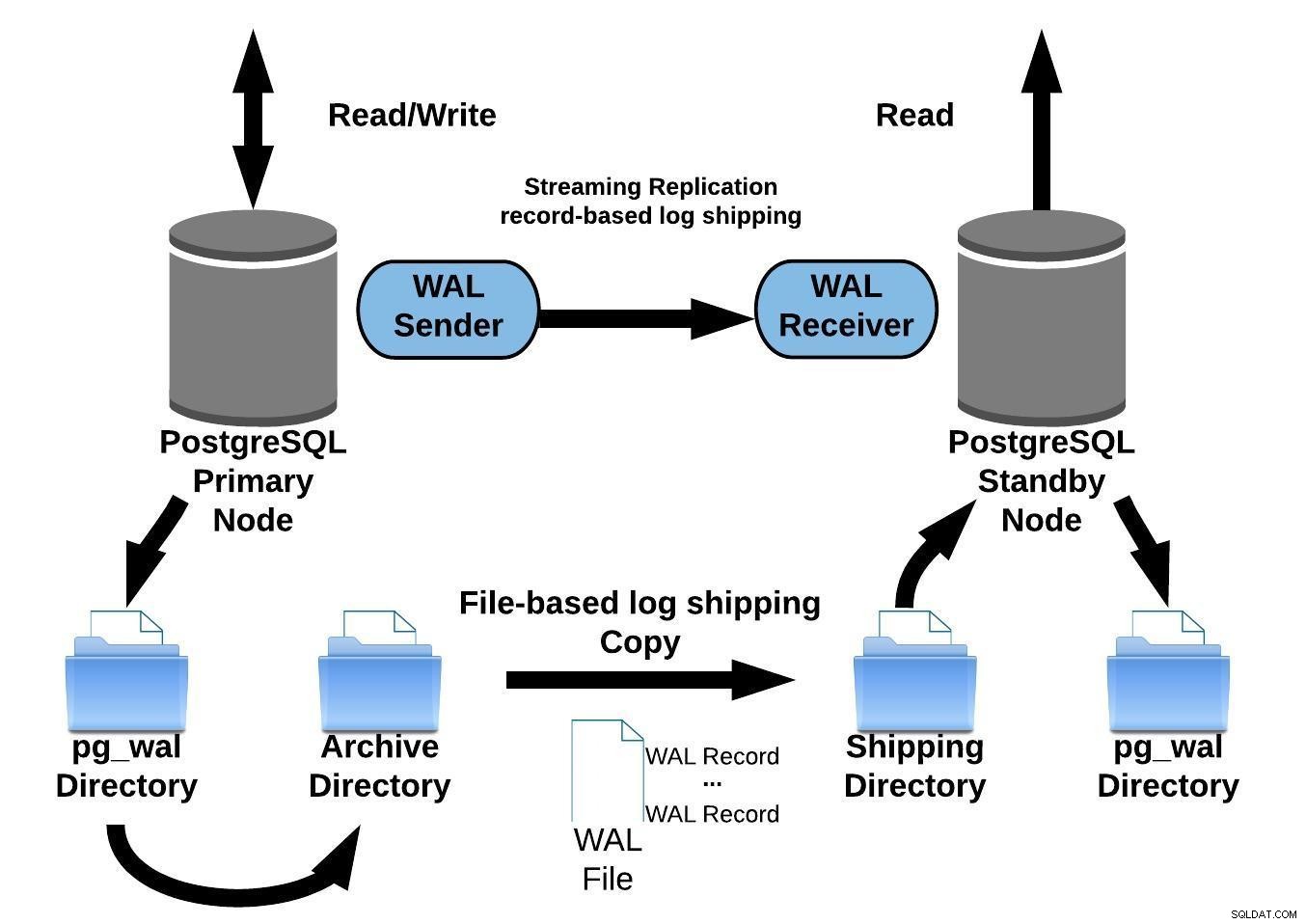 Поточно репликация на PostgreSQL с непрекъснато архивиране
Поточно репликация на PostgreSQL с непрекъснато архивиранеПоточно репликацията е асинхронна по подразбиране, така че на във всеки даден момент можете да имате някои транзакции, които могат да бъдат ангажирани към основния сървър и все още да не се репликират на сървъра в режим на готовност. Това предполага известна потенциална загуба на данни.
Въпреки това, това забавяне между записването и въздействието на промените в репликата се предполага, че е наистина малко (няколко милисекунди), като се приеме, разбира се, че сървърът на репликата е достатъчно мощен, за да бъде в крак с натоварването.
За случаите, когато дори рискът от лека загуба на данни е неприемлив, версия 9.1 въведе функцията за синхронно репликация.
При синхронна репликация всяко записване на транзакция за запис изчаква, докато бъде получено потвърждение, че записът е записан в дневника за предварителна запис на диска както на основния, така и на резервния сървър.
Този метод минимизира възможността от загуба на данни; за да се случи това, ще ви трябва едновременно основният и режим на готовност да се провалят.
Очевидният недостатък на тази конфигурация е, че времето за отговор за всяка транзакция на запис се увеличава, тъй като трябва да изчака, докато всички страни отговорят. Така че времето за комит е най-малкото двупосочно пътуване между основното и репликата. Транзакциите само за четене няма да бъдат засегнати от това.
За да настроите синхронна репликация, трябва да посочите application_name в primary_conninfo на възстановяването за всеки резервен server.conf файл:primary_conninfo ='...aplication_name=standbyX' .
Трябва също да посочите списъка на сървърите в режим на готовност, които ще участват в синхронната репликация:synchronous_standby_name ='standbyX,standbyY'.
Можете да настроите един или няколко синхронни сървъра, като този параметър също така указва кой метод (ПЪРВИ и ВСЕКИ) да изберете синхронен режим на готовност от изброените. За повече информация относно настройката на режим на синхронна репликация, вижте този блог. Възможно е също така да се настрои синхронна репликация при внедряване чрез ClusterControl.
След като конфигурирате своята репликация и тя е стартирана и работи, ще трябва да внедрите наблюдение
Наблюдение на репликацията на PostgreSQL
Изгледът pg_stat_replication на главния сървър има много подходяща информация:
postgres=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 756
usesysid | 16385
usename | cmon_replication
application_name | pgsql_0_node_0
client_addr | 10.10.10.137
client_hostname |
client_port | 36684
backend_start | 2022-04-13 17:45:56.517518+00
backend_xmin |
state | streaming
sent_lsn | 0/400001C0
write_lsn | 0/400001C0
flush_lsn | 0/400001C0
replay_lsn | 0/400001C0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
reply_time | 2022-04-13 17:53:03.454864+00Нека да видим това подробно:
-
pid:Идентификатор на процеса на процеса на walsender.
-
usesysid:OID на потребителя, който се използва за поточно репликация.
-
usename:Име на потребителя, което се използва за поточно репликация.
-
application_name:Име на приложението, свързано с главния.
-
client_addr:Адрес на репликация в режим на готовност/поточно предаване.
-
client_hostname:Име на хост в режим на готовност.
-
client_port:Номер на TCP порт, на който в режим на готовност комуникира с подателя на WAL.
-
backend_start:Начален час, когато SR се свърза с Основния.
-
състояние:Текущо състояние на изпращача на WAL, т.е. поточно предаване.
-
sent_lsn:Местоположението на последната транзакция, изпратено в режим на готовност.
-
write_lsn:Последна транзакция, записана на диск в режим на готовност.
-
flush_lsn:Последна транзакция изтриване на диска в режим на готовност.
-
replay_lsn:Последна транзакция изтриване на диска в режим на готовност.
-
sync_priority:Приоритет на сървъра в режим на готовност, избран като синхронен режим на готовност.
-
sync_state:Синхронизирано състояние на готовност (асинхронно ли е или синхронно).
Можете също да видите процесите на изпращач/получател на WAL, работещи на сървърите.
Подател (основен възел):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47936 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5280 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 734 0.0 0.5 917188 10560 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.4 917208 9908 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 1.0 917060 22928 ? Ss 17:45 0:00 postgres: 14/main: walwriter
postgres 737 0.0 0.4 917748 9128 ? Ss 17:45 0:00 postgres: 14/main: autovacuum launcher
postgres 738 0.0 0.3 917060 6320 ? Ss 17:45 0:00 postgres: 14/main: archiver last was 00000001000000000000003F
postgres 739 0.0 0.2 354160 5340 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 740 0.0 0.3 917632 6892 ? Ss 17:45 0:00 postgres: 14/main: logical replication launcher
postgres 756 0.0 0.6 918252 13124 ? Ss 17:45 0:00 postgres: 14/main: walsender cmon_replication 10.10.10.137(36684) streaming 0/400001C0Приемник (възел в режим на готовност):
[example@sqldat.com ~]# ps aux |grep postgres
postgres 727 0.0 2.2 917060 47576 ? Ss 17:45 0:00 /usr/pgsql-14/bin/postmaster -D /var/lib/pgsql/14/data/
postgres 732 0.0 0.2 351904 5396 ? Ss 17:45 0:00 postgres: 14/main: logger
postgres 733 0.0 0.3 917196 6360 ? Ss 17:45 0:00 postgres: 14/main: startup recovering 000000010000000000000040
postgres 734 0.0 0.4 917060 10056 ? Ss 17:45 0:00 postgres: 14/main: checkpointer
postgres 735 0.0 0.3 917060 6304 ? Ss 17:45 0:00 postgres: 14/main: background writer
postgres 736 0.0 0.2 354160 5456 ? Ss 17:45 0:00 postgres: 14/main: stats collector
postgres 737 0.0 0.6 924532 12948 ? Ss 17:45 0:00 postgres: 14/main: walreceiver streaming 0/400001C0Един от начините да проверите колко актуална е вашата репликация, е като проверите количеството WAL записи, генерирани в основния сървър, но все още не приложени в сървъра в режим на готовност.
Основно:
postgres=# SELECT pg_current_wal_lsn();
pg_current_wal_lsn
--------------------
0/400001C0
(1 row)Режим на готовност:
postgres=# SELECT pg_last_wal_receive_lsn();
pg_last_wal_receive_lsn
-------------------------
0/400001C0
(1 row)
postgres=# SELECT pg_last_wal_replay_lsn();
pg_last_wal_replay_lsn
------------------------
0/400001C0
(1 row)Можете да използвате следната заявка в възела в режим на готовност, за да получите изоставането за секунди:
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn() = pg_last_wal_replay_lsn()
THEN 0
ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
END AS log_delay;
log_delay
-----------
0
(1 row)Можете също да видите последното получено съобщение:
postgres=# SELECT status, last_msg_receipt_time FROM pg_stat_wal_receiver;
status | last_msg_receipt_time
-----------+------------------------------
streaming | 2022-04-13 18:32:39.83118+00
(1 row)Наблюдение на репликацията на PostgreSQL с ClusterControl
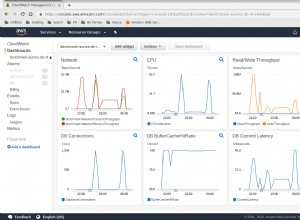
За да наблюдавате своя PostgreSQL клъстер, можете да използвате ClusterControl, който ви позволява да наблюдавате и изпълнявате няколко допълнителни задачи за управление като разполагане, архивиране, мащабиране и други.
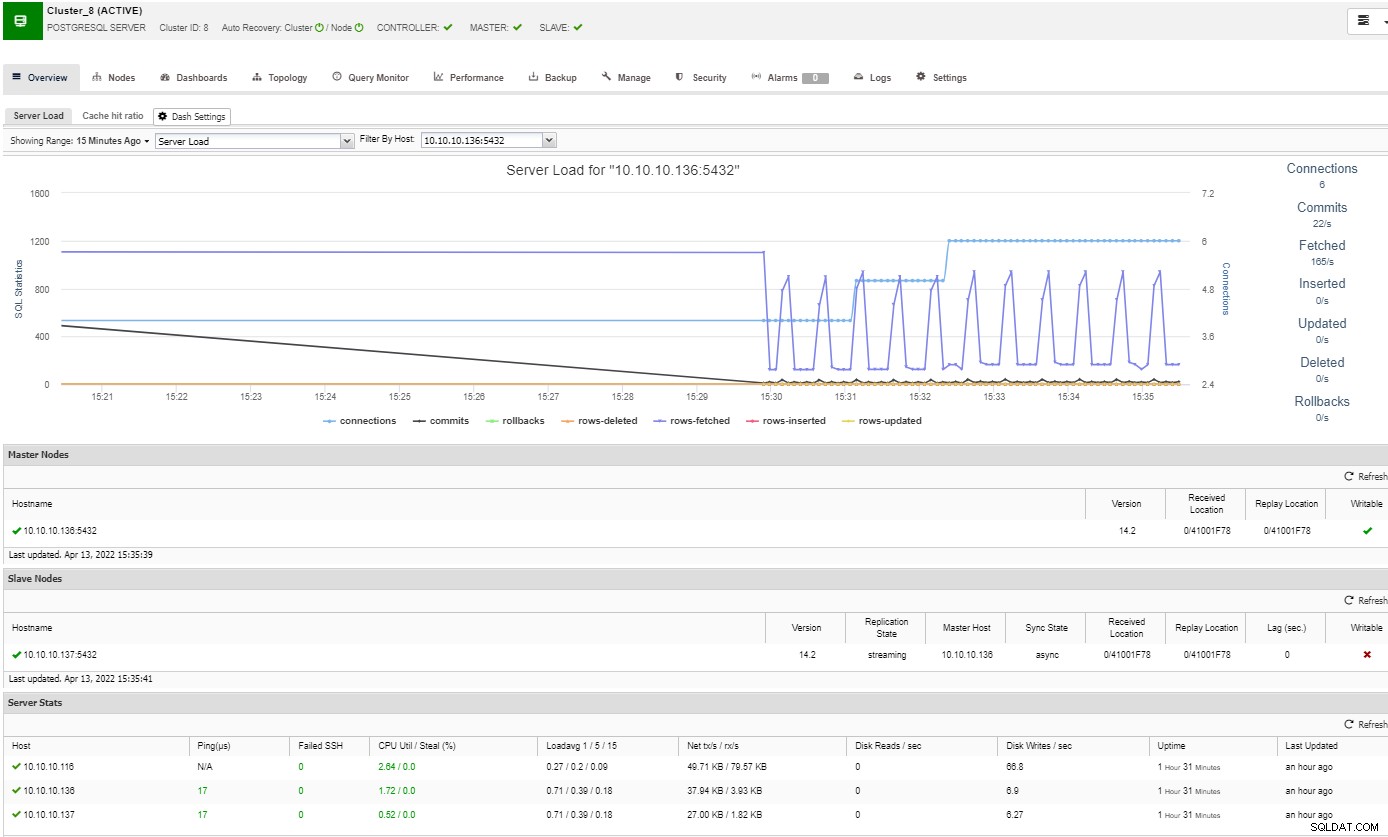
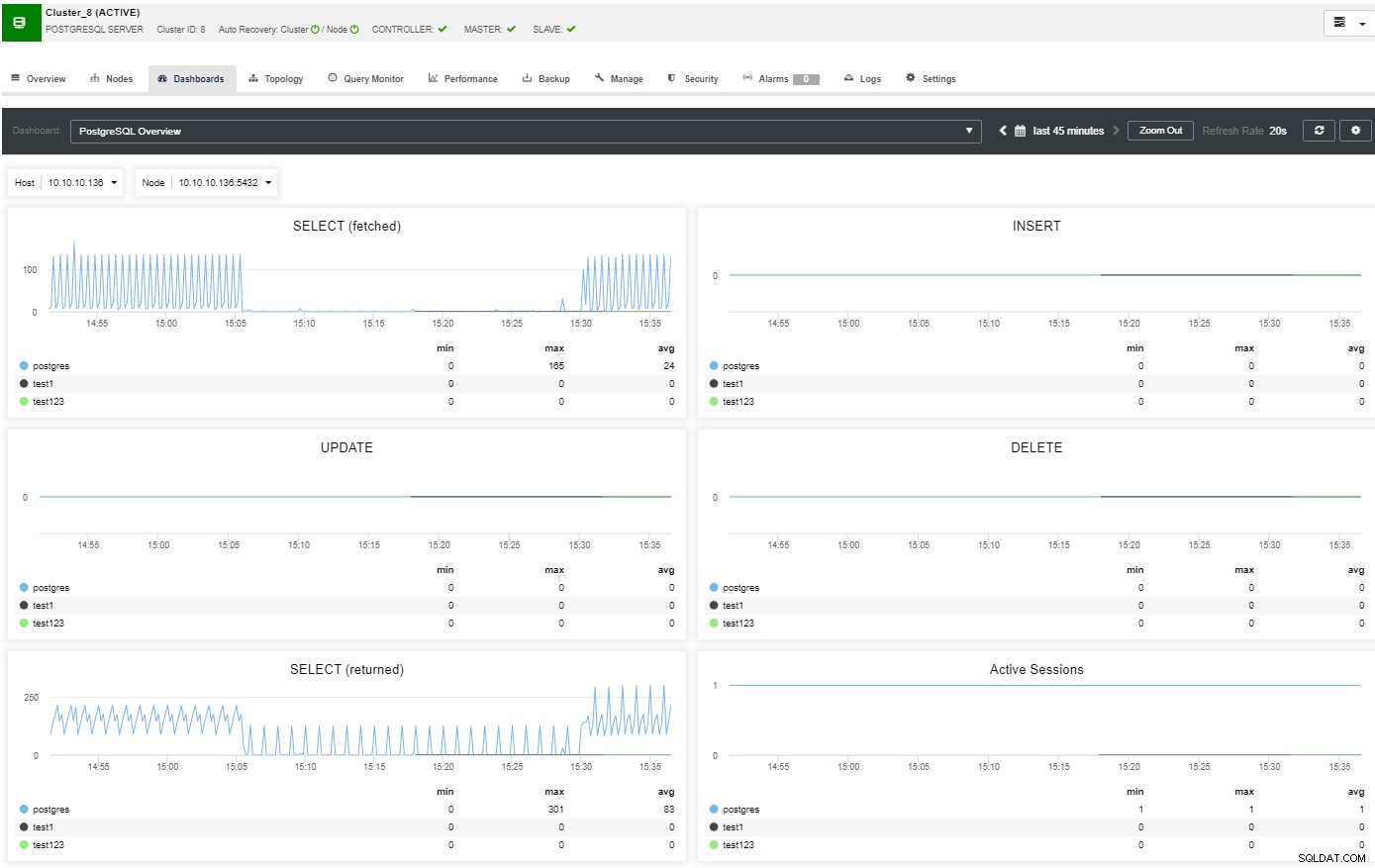
В секцията за преглед ще имате пълната картина на клъстера на вашата база данни актуално състояние. За да видите повече подробности, можете да получите достъп до секцията на таблото, където ще видите много полезна информация, разделена на различни графики.
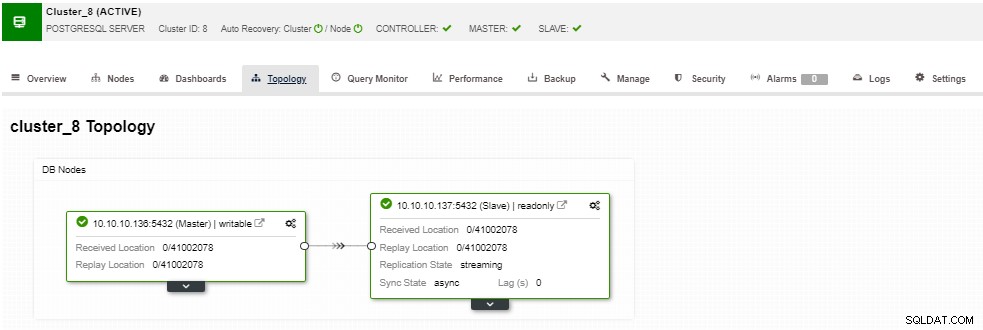
В секцията за топология можете да видите текущата си топология в потребител- приятелски начин и можете също да изпълнявате различни задачи над възлите, като използвате бутона за действие на възела.
Поточно репликацията се основава на изпращане на WAL записите и прилагането им в режим на готовност сървър, той диктува какви байтове да добавите или промените в какъв файл. В резултат на това резервният сървър всъщност е побитово копие на основния сървър. Тук обаче има някои добре известни ограничения:
-
Не можете да копирате в друга версия или архитектура.
-
Не можете да промените нищо на сървъра в режим на готовност.
-
Нямате голяма детайлност на това, което репликирате.
И така, за да преодолее тези ограничения, PostgreSQL 10 добави поддръжка за логическа репликация
Логическа репликация
Логическата репликация също ще използва информацията във файла WAL, но ще я декодира в логически промени. Вместо да знае кой байт се е променил, той ще знае точно какви данни са били вмъкнати в коя таблица.
Базира се на модел „публикуване“ и „абониране“ с един или повече абонати, които се абонират за една или повече публикации на възел на издател, който изглежда така:
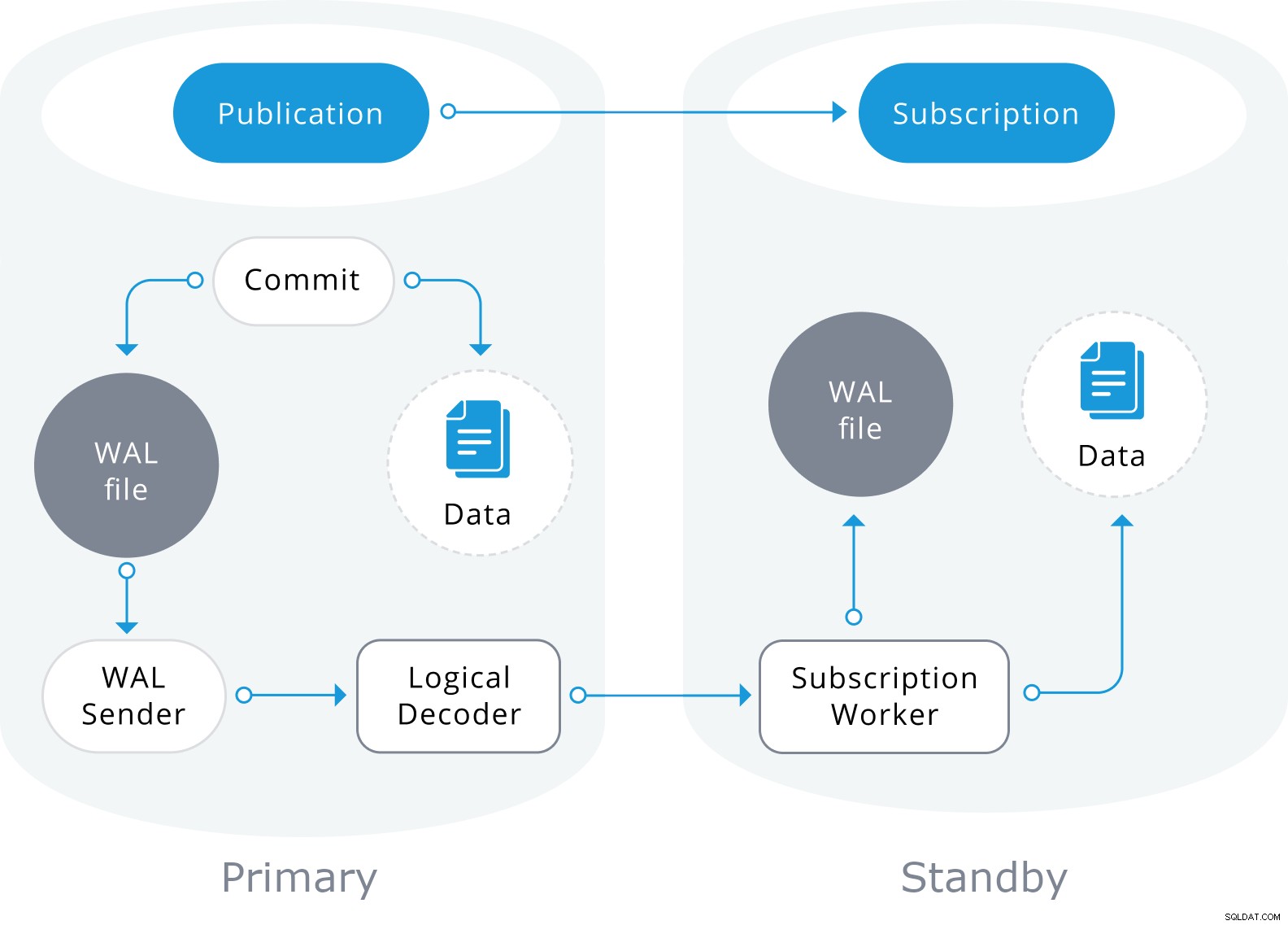
Приключване
С поточно репликация можете непрекъснато да изпращате и прилагате WAL записи към вашите сървъри в режим на готовност, като гарантирате, че информацията, актуализирана на основния сървър, се прехвърля към резервния сървър в реално време, което позволява и двете да останат в синхрон .
ClusterControl прави настройката на поточно репликация лесна и можете да го оцените безплатно за 30 дни.
Ако искате да научите повече за логическата репликация в PostgreSQL, не забравяйте да разгледате този преглед на логическата репликация и тази публикация за най-добрите практики за репликация на PostgreSQL.
За повече съвети и най-добри практики за управление на вашата база данни с отворен код, следвайте ни в Twitter и LinkedIn и се абонирайте за нашия бюлетин за редовни актуализации.