Репликацията играе решаваща роля за поддържане на висока наличност. Сървърите може да се повредят, операционната система или софтуерът на базата данни може да се наложи да се надстроят. Това означава пренареждане на ролите на сървъра и преместване на връзките за репликация, като същевременно се поддържа последователност на данните във всички бази данни. Ще са необходими промени в топологията и има различни начини за извършването им.
Насърчаване на сървър в режим на готовност
Може да се каже, че това е най-честата операция, която ще трябва да извършите. Има няколко причини – например поддръжка на база данни на основния сървър, която би повлияла на натоварването по неприемлив начин. Възможно е да има планиран престой поради някои хардуерни операции. Сривът на основния сървър, който го прави недостъпен за приложението. Това са всички причини за извършване на отказ, независимо дали е планирано или не. Във всички случаи ще трябва да повишите един от резервните сървъри, за да стане нов основен сървър.
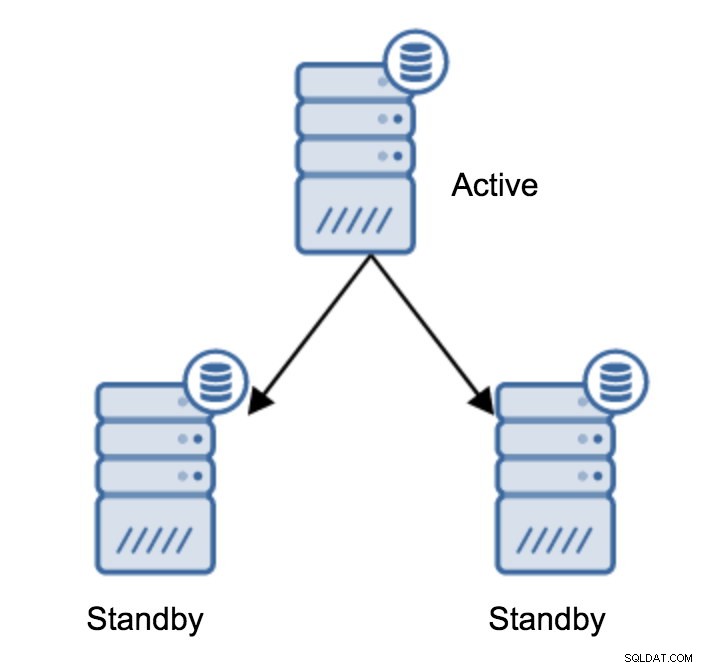
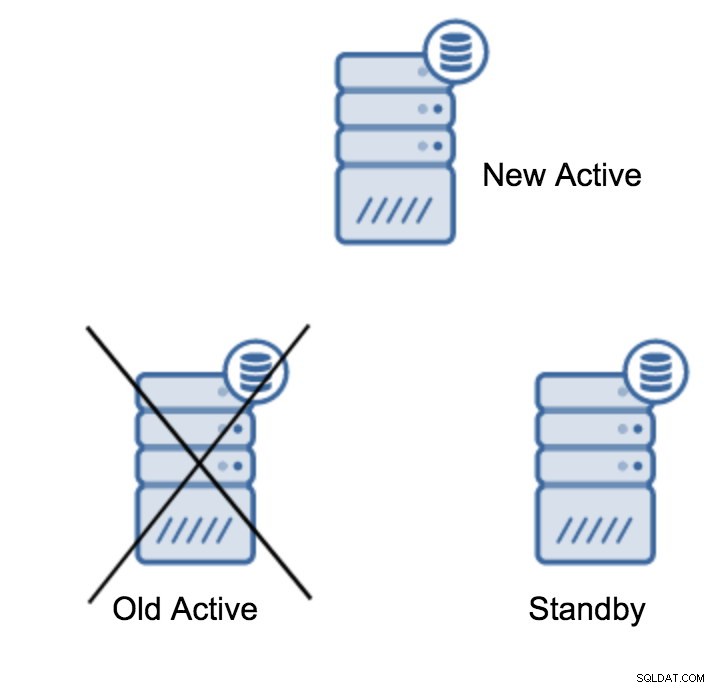
За да популяризирате сървър в режим на готовност, трябва да изпълните:
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_ctl promote -D /var/lib/postgresql/10/main/
waiting for server to promote.... done
server promotedЛесно е да изпълните тази команда, но първо се уверете, че избягвате загуба на данни. Ако говорим за сценарий за „изключване на първичния сървър“, може да нямате твърде много опции. Ако е планирана поддръжка, тогава е възможно да се подготвите за нея. Трябва да спрете трафика на основния сървър и след това да проверите дали сървърът в режим на готовност е получил и приложил всички данни. Това може да се направи на сървъра в режим на готовност, като се използва заявка, както следва:
postgres=# select pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn();
pg_last_wal_receive_lsn | pg_last_wal_replay_lsn
-------------------------+------------------------
1/AA2D2B08 | 1/AA2D2B08
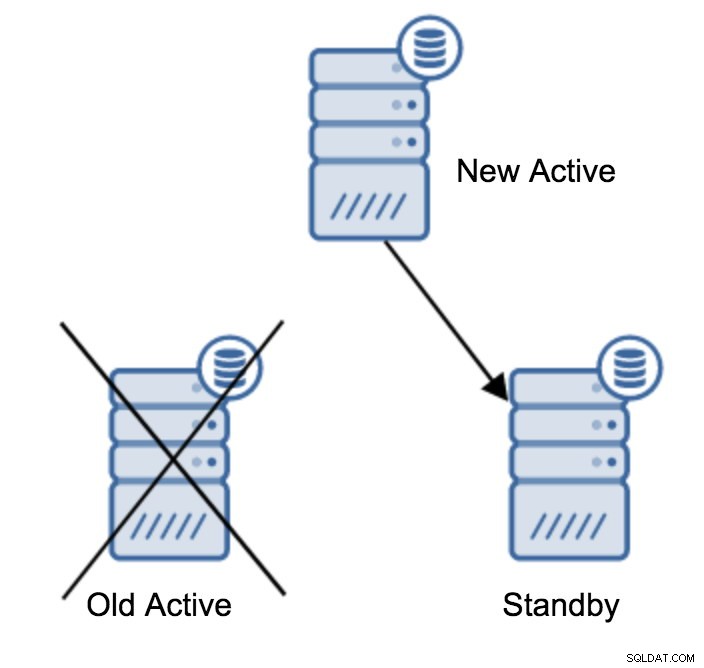
(1 row)След като всичко е наред, можете да спрете стария първичен сървър и да популяризирате резервния сървър.
Изтеглете Бялата книга днес Управление и автоматизация на PostgreSQL с ClusterControl Научете какво трябва да знаете, за да внедрите, наблюдавате, управлявате и мащабирате PostgreSQLD Изтеглете Бялата книгаПовторно свързване на сървър в режим на готовност от нов първичен сървър
Може да имате повече от един резервен сървър, подчинен на вашия основен сървър. В крайна сметка сървърите в режим на готовност са полезни за разтоварване на трафик само за четене. След като промотирате резервен сървър към нов първичен сървър, трябва да направите нещо за останалите резервни сървъри, които все още са свързани (или които се опитват да се свържат) със стария първичен сървър. За съжаление, не можете просто да промените recovery.conf и да ги свържете към новия основен сървър. За да ги свържете, първо трябва да ги възстановите. Има два метода, които можете да опитате тук:стандартно базово архивиране или pg_rewind.
Няма да навлизаме в подробности как да вземем базово архивиране - разгледахме го в предишната ни публикация в блога, която се фокусира върху вземането на резервни копия и възстановяването им в PostgreSQL. Ако случайно използвате ClusterControl, можете да го използвате и за създаване на основен архив:
От друга страна, нека кажем няколко думи за pg_rewind. Основната разлика между двата метода е, че базовото архивиране създава пълно копие на набора от данни. Ако говорим за малки набори от данни, може да е добре, но за набори от данни със стотици гигабайта по размер (или дори по-големи), това може бързо да се превърне в проблем. В крайна сметка искате вашите резервни сървъри да работят бързо - да разтоварите активния си сървър и да имате друг режим на готовност за превключване при отказ, ако възникне необходимост. Pg_rewind работи по различен начин - копира само онези блокове, които са били променени. Вместо да копира всичко, той копира само промените, ускорявайки значително процеса. Да предположим, че вашият нов главен има IP 10.0.0.103. Ето как можете да изпълните pg_rewind. Моля, имайте предвид, че трябва да спрете целевия сървър - PostgreSQL не може да работи там.
example@sqldat.com:~$ /usr/lib/postgresql/10/bin/pg_rewind --source-server="user=myuser dbname=postgres host=10.0.0.103" --target-pgdata=/var/lib/postgresql/10/main --dry-run
servers diverged at WAL location 1/AA4F1160 on timeline 3
rewinding from last common checkpoint at 1/AA4F10F0 on timeline 3
Done!Това ще направи пропускане на сухо , тества процеса, но не прави никакви промени. Ако всичко е наред, всичко, което ще трябва да направите, е да го стартирате отново, този път без параметъра „--dry-run“. След като приключите, последната оставаща стъпка ще бъде да създадете файл recovery.conf, който ще сочи към новия главен файл. Може да изглежда така:
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.103 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'Сега сте готови да стартирате вашия резервен сървър и той ще се репликира от новия активен сървър.
Верижна репликация
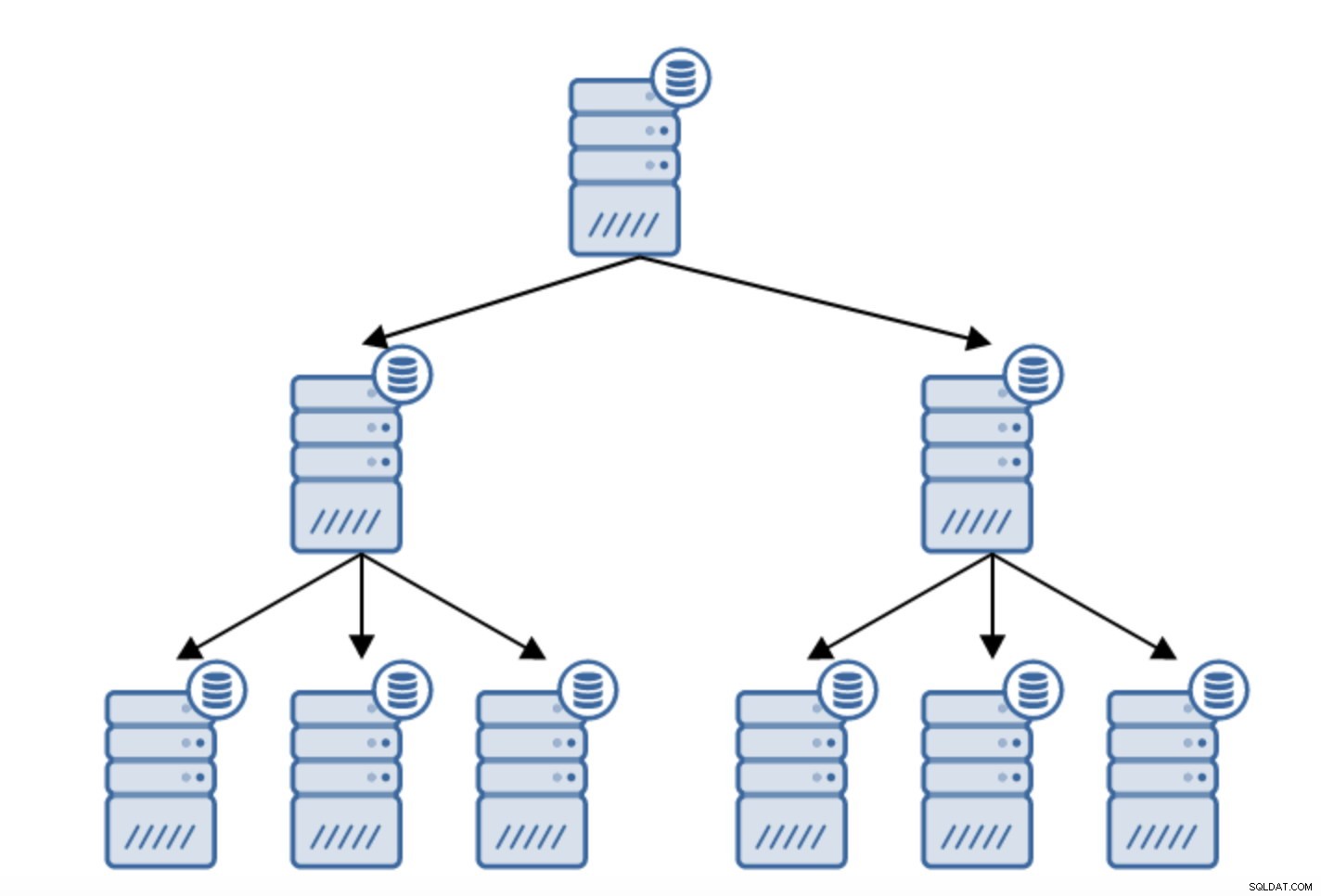
Има много причини, поради които може да искате да изградите верижна репликация, въпреки че обикновено се прави, за да се намали натоварването на основния сървър. Обслужването на WAL към сървъри в режим на готовност добавя някои допълнителни разходи. Не е голям проблем, ако имате готовност или два, но ако говорим за голям брой сървъри в режим на готовност, това може да се превърне в проблем. Например, можем да сведем до минимум броя на резервните сървъри, репликиращи директно от активния, като създадем топология, както е посочено по-долу:
Преминаването от топология на два резервни сървъра към верижна репликация е доста лесно.
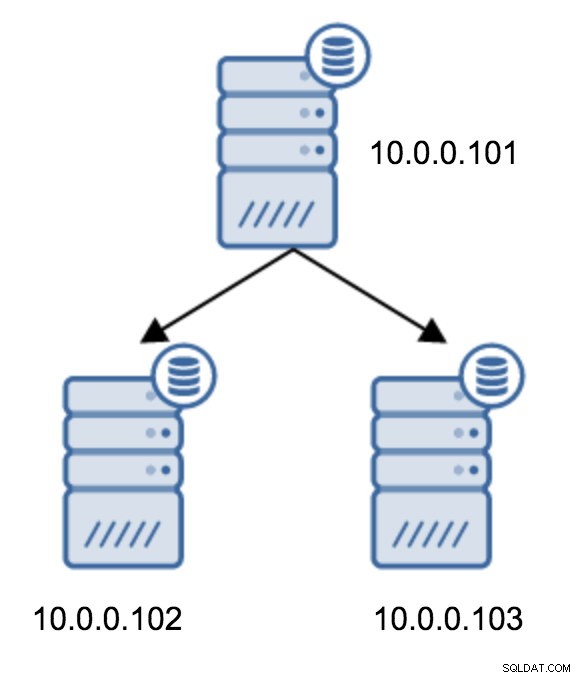
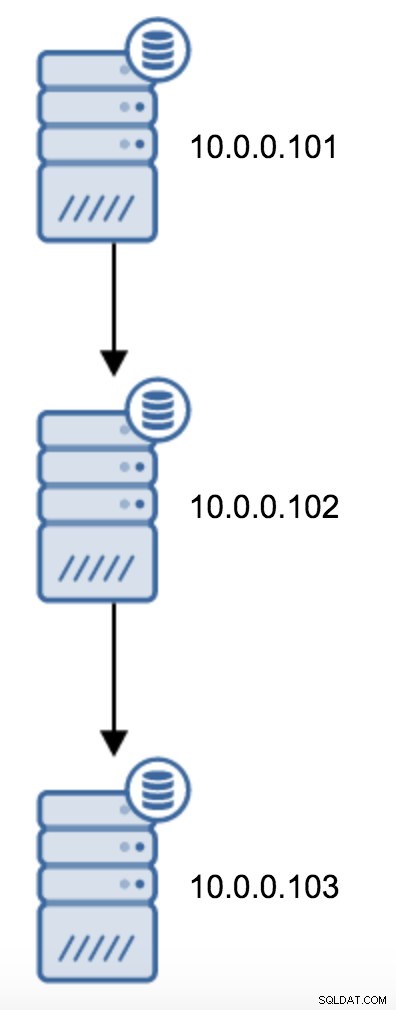
Ще трябва да промените recovery.conf на 10.0.0.103, да го насочите към 10.0.0.102 и след това да рестартирате PostgreSQL.
standby_mode = 'on'
primary_conninfo = 'application_name=pgsql_node_0 host=10.0.0.102 port=5432 user=replication_user password=replication_password'
recovery_target_timeline = 'latest'
trigger_file = '/tmp/failover.trigger'След рестартиране 10.0.0.103 трябва да започне да прилага актуализации на WAL.
Това са някои често срещани случаи на промени в топологията. Една тема, която не беше обсъждана, но която все още е важна, е въздействието на тези промени върху приложенията. Ще разгледаме това в отделна публикация, както и как да направим тези промени в топологията прозрачни за приложенията.