Въпреки че все още няма сканиране с пропускане на индекс в Postgres, емулирайте го:
WITH RECURSIVE cte AS (
( -- parentheses required
SELECT product_id
FROM tickers
ORDER BY 1
LIMIT 1
)
UNION ALL
SELECT l.*
FROM cte c
CROSS JOIN LATERAL (
SELECT product_id
FROM tickers t
WHERE t.product_id > c.product_id -- lateral reference
ORDER BY 1
LIMIT 1
) l
)
TABLE cte;
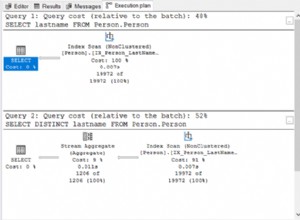
С индекс на (product_id) и само 40 уникални идентификатора на продукти в таблицата това трябва да е Бързо . С главно F .
Индексът на PK на (product_id, trade_id) е добре и за него!
Само с много няколко реда на product_id (обратно на разпределението на вашите данни), DISTINCT / DISTINCT ON ще бъде толкова бързо или по-бързо.
Работата по внедряване на сканиране при пропускане на индекси продължава.
Вижте:
- Изберете ли първия ред във всяка група GROUP BY?
- Оптимизирайте заявката GROUP BY, за да извлечете последния ред на потребител
- Съставният индекс добър ли е и за заявки в първото поле?