Това се появи няколко пъти наскоро, както в SO, така и в пощенските списъци на PostgreSQL.
TL;DR за последните ви две точки:
(a) По-големите shared_buffers може да са причината TRUNCATE да е по-бавна на CI сървъра. Различната конфигурация на fsync или използването на ротационни носители вместо SSD също може да са виновни.
(b) TRUNCATE има фиксирана цена, но не непременно по-бавна от DELETE , освен това върши повече работа. Вижте подробното обяснение, което следва.
АКТУАЛИЗИРАНЕ: Значителна дискусия относно производителността на pgsql възникна от тази публикация. Вижте тази тема.
АКТУАЛИЗАЦИЯ 2: Към 9.2beta3 са добавени подобрения, които трябва да помогнат за това, вижте тази публикация.
Подробно обяснение на TRUNCATE срещу DELETE FROM :
Въпреки че не съм експерт по темата, разбирам, че TRUNCATE има почти фиксирана цена на таблица, докато DELETE е най-малко O(n) за n реда; по-лошо, ако има някакви външни ключове, препращащи таблицата, която се изтрива.
Винаги съм предполагал, че фиксираната цена на TRUNCATE беше по-ниска от цената на DELETE на почти празна маса, но това изобщо не е вярно.
TRUNCATE table; прави повече от DELETE FROM table;
Състоянието на базата данни след TRUNCATE table е почти същото, както ако вместо това стартирате:
DELETE FROM table;VACCUUM (FULL, ANALYZE) table;(само 9.0+, вижте бележката под линия)
... макар че разбира се TRUNCATE всъщност не постига ефектите си с DELETE и VACUUM .
Въпросът е, че DELETE и TRUNCATE правете различни неща, така че не просто сравнявате две команди с еднакви резултати.
A DELETE FROM table; позволява на мъртвите редове и раздуването да останат, позволява на индексите да пренасят мъртви записи, не актуализира статистическите данни на таблицата, използвани от планирането на заявки и т.н.
A TRUNCATE ви дава напълно нова таблица и индекси, сякаш са просто CREATE изд. Сякаш сте изтрили всички записи, преиндексирали сте таблицата и сте направили VACUUM FULL .
Ако не ви пука дали в таблицата е останало малко, защото ще отидете да я напълните отново, може би е по-добре да използвате DELETE FROM table; .
Тъй като не изпълнявате VACUUM ще откриете, че мъртвите редове и записи в индекса се натрупват като раздуване, което трябва да бъде сканирано и след това игнорирано; това забавя всичките ви заявки. Ако вашите тестове всъщност не създават и изтриват толкова много данни, може да не забележите или да не ви интересува, и винаги можете да направите VACUUM или две части от тестовия ви цикъл, ако го направите. По-добре, оставете агресивните настройки за автоматично вакуумиране да гарантират, че автоматичното вакуумиране го прави вместо вас на заден план.
Все още можете да TRUNCATE всичките ви таблици след цялото тестов пакет се изпълнява, за да се уверите, че няма натрупване на ефекти при много серии. На 9.0 и по-нови, VACUUM (FULL, ANALYZE); в световен мащаб на масата е поне толкова добър, ако не и по-добър, и е много по-лесно.
IIRC Pg има няколко оптимизации, които означават, че може да забележи, когато вашата транзакция е единствената, която може да види таблицата и веднага да маркира блоковете като безплатни. При тестване, когато исках да създам раздуване, трябваше да имам повече от една едновременна връзка, за да го направя. Аз обаче не бих разчитал на това.
DELETE FROM table; е много евтин за малки маси без f/k refsи
За DELETE всички записи от таблица без препратки към външни ключове към нея, всички Pg трябва да направят последователно сканиране на таблицата и да зададе xmax от срещнатите кортежи. Това е много евтина операция - основно линейно четене и полулинейно запис. AFAIK не е нужно да докосва индексите; те продължават да сочат към мъртвите кортежи, докато не бъдат почистени от по-късен VACUUM което също така маркира като свободни блокове в таблицата, съдържащи само мъртви кортежи.
DELETE става скъпо само ако има много на записи, ако има много препратки към външни ключове, които трябва да бъдат проверени, или ако преброите последващата таблица VACUUM (FULL, ANALYZE) table; необходимо да съответства на TRUNCATE ефектите на ' в рамките на цената на вашето DELETE .
В моите тестове тук, DELETE FROM table; обикновено беше 4 пъти по-бърз от TRUNCATE при 0,5 ms срещу 2 ms. Това е тестова БД на SSD, работеща с fsync=off защото не ме интересува дали ще загубя всички тези данни. Разбира се, DELETE FROM table; не върши една и съща работа и ако продължа с таблица VACUUM (FULL, ANALYZE) table; това е много по-скъпо от 21 мс, така че DELETE е само печалба, ако всъщност не се нуждая от чиста маса.
TRUNCATE table; извършва много повече работа и домакинство с фиксирани разходи от DELETE
За разлика от това, TRUNCATE трябва да свърши много работа. Той трябва да разпредели нови файлове за таблицата, нейната TOAST таблица, ако има такава, и всеки индекс, който таблицата има. Заглавките трябва да бъдат записани в тези файлове и системните каталози може също да се нуждаят от актуализиране (не съм сигурен в тази точка, не съм проверявал). След това трябва да замени старите файлове с новите или да премахне старите и трябва да гарантира, че файловата система е настигнала промените с операция за синхронизиране - fsync() или подобна - която обикновено изхвърля всички буфери на диска . Не съм сигурен дали синхронизирането е пропуснато, ако работите с опцията (изяждане на данни) fsync=off .
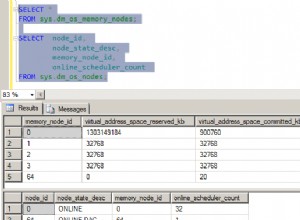
Наскоро научих, че TRUNCATE трябва също да изчисти всички буфери на PostgreSQL, свързани със старата таблица. Това може да отнеме нетривиално време с огромни shared_buffers . Подозирам, че това е причината да работи по-бавно на вашия CI сървър.
Баланс
Както и да е, можете да видите, че TRUNCATE на таблица, която има свързана TOAST таблица (повечето го правят) и няколко индекса може да отнеме няколко минути. Не е дълго, но по-дълго от DELETE от почти празна маса.
Следователно, може би е по-добре да направите DELETE FROM table; .
--
Забележка:на DBs преди 9.0, CLUSTER table_id_seq ON table; ANALYZE table; или VACUUM FULL ANALYZE table; REINDEX table; би било по-близък еквивалент на TRUNCATE . VACUUM FULL impl е променен на много по-добър в 9.0.