Продължавам серия от статии за основите на EXPLAIN в PostgreSQL, която представлява кратък преглед на Understanding EXPLAIN от Guillaume Lelarge.
За да разберете по-добре проблема, силно препоръчвам да прегледате оригиналното „Understanding EXPLAIN“ от Guillaume Lelarge и прочетете първата и втората ми статии.
ПОРЪЧАЙТЕ ОТ
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Първо изпълнявате последователно сканиране (Seq Scan) на таблицата foo и след това извършвате сортирането (Sort). Знакът -> на командата EXPLAIN показва йерархията на стъпките (възел). Колкото по-рано се изпълни стъпката, толкова по-голям е отстъпът.
Ключът за сортиране е условие за сортиране.
Метод на сортиране:външно обединяване Диск При сортиране се използва временен файл на диска с капацитет 4592 kB.
Проверете с опцията BUFFERS:
DROP INDEX foo_c1_idx; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;
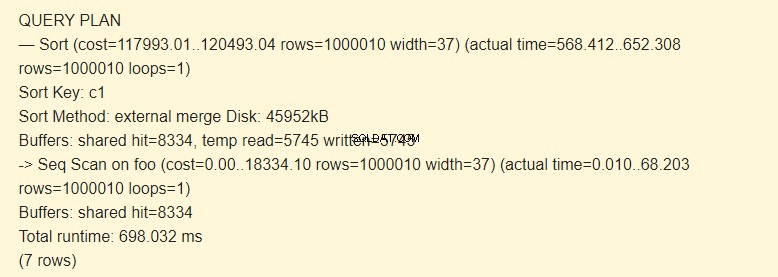
Действително, редът temp read=5745 write=5745 означава, че 45960Kb (5745 блока от 8 Kb всеки) са били съхранени и прочетени във временния файл. Операциите с 8334 блока бяха изпълнени в кеша.
Операциите с файловата система са по-бавни от операциите в RAM.
Нека се опитаме да увеличим капацитета на паметта на work_mem:
SET work_mem TO '200MB'; EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Метод на сортиране:quicksort Памет:102702kB – цялото сортиране е изпълнено в RAM.
Индексът е както следва:
CREATE INDEX ON foo(c1); EXPLAIN (ANALYZE) SELECT * FROM foo ORDER BY c1;

Остана ни само индексно сканиране, което значително повлия на скоростта на заявката.
LIMIT
Изтрийте предварително създадения индекс:
DROP INDEX foo_c2_idx1; EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%';
Както се очаква, се използват Seq Scan и Filter.
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo WHERE c2 LIKE 'ab%' LIMIT 10;

Seq Scan чете редове от таблицата и ги сравнява (Filter) с условието. Щом има 10 записа, които отговарят на условието, сканирането ще приключи. В нашия случай, за да получим 10 реда резултат, трябваше да прочетем само 3063 записа, а не цялата таблица. 3053 реда от този номер бяха отхвърлени (Редове, премахнати от филтър).
Същото се случва и с индексното сканиране.
Присъединете се
Създайте нова таблица и генерирайте статистически данни за нея:
CREATE TABLE bar (c1 integer, c2 boolean); INSERT INTO bar SELECT i, i%2=1 FROM generate_series(1, 500000) AS i; ANALYZE bar;
Заявката за две таблици е както следва:
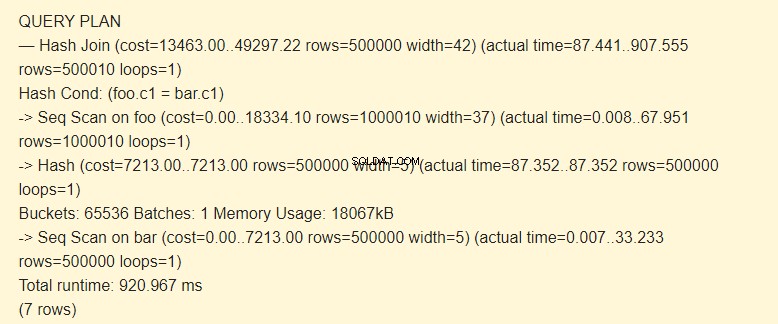
EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;
Първо, последователното сканиране (Seq Scan) чете бар таблицата. За всеки ред се изчислява хеш (Hash).
След това сканира foo таблицата и за всеки ред се изчислява хеш, който се сравнява (Hash Join) с хеша на таблицата на лентата от условието Hash Cond. Ако съвпадат, се извежда резултантният низ.
18067 kB памет се използва за съхраняване на хешове за лентата.
Добавете индекса:
CREATE INDEX ON bar(c1); EXPLAIN (ANALYZE) SELECT * FROM foo JOIN bar ON foo.c1=bar.c1;

Хешът вече не се използва. Сливането на присъединяване и индексно сканиране на индексите на двете таблици подобрява значително производителността.
ЛЯВО ПРИСЪЕДИНЯВАНЕ:
EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
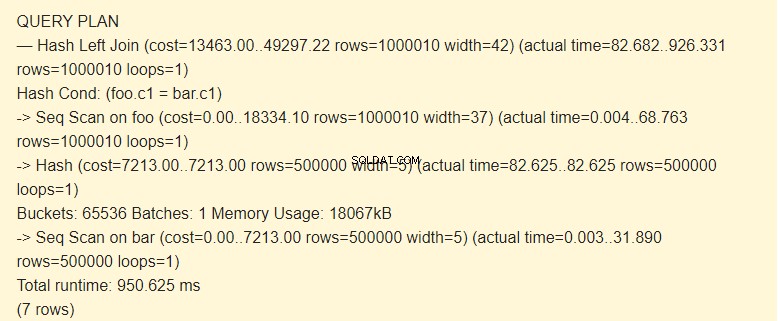
Seq Scan?
Нека видим какъв резултат ще имаме, ако деактивираме Seq Scan.
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Според планировчика използването на индекси е по-скъпо от използването на хешове. Това е възможно при достатъчно голямо количество разпределена памет. Спомняте ли си, че увеличавахме work_mem?
Ако обаче нямате достатъчно памет, планировчикът ще се държи по различен начин:
SET work_mem TO '15MB'; SET enable_seqscan TO ON; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;

Ако деактивираме индексното сканиране, какъв резултат ще се покаже EXPLAIN?
SET work_mem TO '15MB'; SET enable_indexscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo LEFT JOIN bar ON foo.c1=bar.c1;
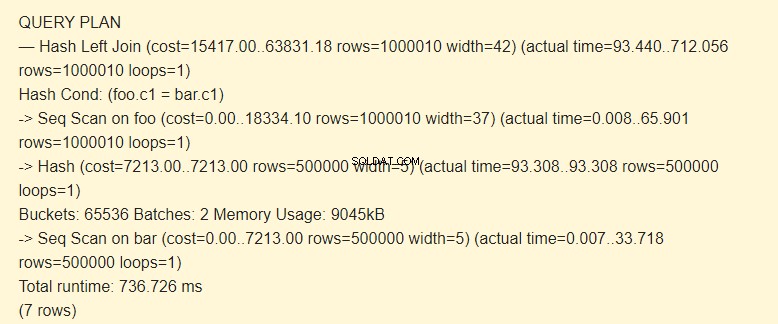
Партиди:2 са с повишена цена. Целият хеш не се побираше в паметта; трябваше да го разделим на два пакета от 9045 kB.
Благодаря ви, че четете моите статии! Надявам се да са били полезни. Ако имате коментари или отзиви, не се колебайте да ме уведомите.