В предишната ми статия започнахме да описваме основите на командата EXPLAIN и анализирахме какво се случва в PostgreSQL при изпълнение на заявка.
Ще продължа да пиша за основите на EXPLAIN в PostgreSQL. Информацията е кратък преглед на Understanding EXPLAIN от Гийом Леларж. Силно препоръчвам да прочетете оригинала, тъй като част от информацията е пропусната.
Кеш
Какво се случва на физическо ниво при изпълнение на нашата заявка? Нека го разберем. Разположих сървъра си на Ubuntu 13.10 и използвах дискови кешове на ниво OS.
Спирам PostgreSQL, извършвам промени във файловата система, изчиствам кеша и стартирам PostgreSQL:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Когато кешът се изчисти, изпълнете заявката с опцията BUFFERS
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Четем таблицата по блокове. Кешът е празен. Трябваше да получим достъп до 8334 блока, за да прочетем цялата таблица от диска.
Буфери:споделеното четене е броят на блоковете, които PostgreSQL чете от диска.
Изпълнете предишната заявка
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Буфери:споделеното попадение е броят на блоковете, извлечени от кеша на PostgreSQL.
С всяка заявка PostgreSQL взема все повече и повече данни от кеша, като по този начин попълва собствения си кеш.
Операциите за четене на кеш паметта са по-бързи от операциите за четене на диск. Можете да видите тази тенденция, като проследите общата стойност на времето на изпълнение.
Размерът на кеш паметта се определя от константата shared_buffers във файла postgresql.conf.
КЪДЕ
Добавете условието към заявката
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
В таблицата няма индекси. При изпълнение на заявката всеки запис на таблицата се сканира последователно (Seq Scan) и се сравнява с условието c1> 500. Ако условието е изпълнено, записът се добавя към резултата. В противен случай се изхвърля. Филтърът показва това поведение, както и увеличаването на стойността на разходите.
Прогнозният брой редове намалява.
Оригиналната статия обяснява защо разходите приемат тази стойност и как се изчислява прогнозният брой редове.
Време е за създаване на индекси.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Приблизителният брой редове е променен. Какво ще кажете за индекса?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Само 510 реда от повече от 1 милион са филтрирани. PostgreSQL трябваше да прочете повече от 99,9 % от таблицата.
Ще принудим да използваме индекса, като деактивираме Seq Scan:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

В Index Scan и Index Cond индексът foo_c1_idx се използва вместо Filter.
Когато избирате цялата таблица, използването на индекса ще увеличи разходите и времето за изпълнение на заявката.
Активиране на Seq Scan:
SET enable_seqscan TO on;
Променете заявката:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
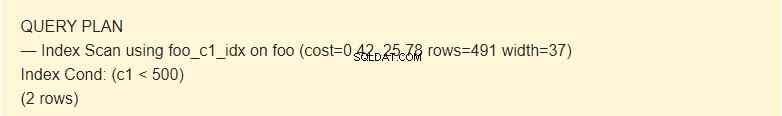
Тук плановникът използва индекса.
Сега нека усложним стойността, като добавим текстовото поле.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Както можете да видите, индексът foo_c1_idx се използва за c1 <500. За да изпълните c2 ~~ ‘abcd%’::text, използвайте филтъра.
Трябва да се отбележи, че POSIX форматът на оператора LIKE се използва в изхода на резултатите. Ако има само текстовото поле в условието:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Прилага се Seq Scan.
Изградете индекса от c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Индексът не се прилага, защото моята база данни за тестови полета използва UTF-8 кодиране.
При изграждане на индекса е необходимо да посочите класа на оператора text_pattern_ops:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Страхотен! Сработи!
Сканирането на индекс на растерни изображения използва индекса foo_c2_idx1, за да определи необходимите ни записи. След това PostgreSQL отива в таблицата (Bitmap Heap Scan), за да се увери, че тези записи действително съществуват. Това поведение се отнася до версията на PostgreSQL.
Ако изберете само полето, върху което е изграден индексът, вместо целия ред:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Само индексното сканиране ще се извърши по-бързо от индексното сканиране поради факта, че не е необходимо да се чете реда на таблицата:width=4.
Заключение
- Seq Scan чете цялата таблица
- Индексното сканиране използва индекса за изразите WHERE и чете таблицата при избор на редове
- Индексното сканиране на растерни изображения използва индексно сканиране и контрол на избора през таблицата. Ефективен за голям брой редове.
- Сканирането само с индекс е най-бързият блок, който чете само индекса.
Допълнително четене:
Оптимизация на заявки в PostgreSQL. EXPLAIN Basics – Част 3