Като системни администратори и разработчици, ние прекарваме много време в терминал. Така че докарахме ClusterControl в терминала с нашия инструмент за интерфейс на командния ред, наречен s9s. s9s предоставя лесен интерфейс към ClusterControl RPC v2 API. Ще го намерите много полезно, когато работите с широкомащабни внедрявания, тъй като CLI позволява ще ви позволи да проектирате по-сложни функции и работни потоци.
Тази публикация в блога показва как да използвате s9s за автоматизиране на управлението на Galera Cluster за MySQL или MariaDB, както и проста настройка за репликация главен-подчинен.
Настройка
Можете да намерите инструкции за инсталиране на вашата конкретна ОС в документацията. Това, което е важно да се отбележи, е, че ако случайно използвате най-новите s9s-инструменти от GitHub, има лека промяна в начина, по който създавате потребител. Следната команда ще работи добре:
s9s user --create --generate-key --controller="https://localhost:9501" dbaКато цяло са необходими две стъпки, ако искате да конфигурирате CLI локално на хоста ClusterControl. Първо, трябва да създадете потребител и след това да направите някои промени в конфигурационния файл - всички стъпки са включени в документацията.
Внедряване
След като CLI е конфигуриран правилно и има SSH достъп до вашите целеви хостове на база данни, можете да започнете процеса на внедряване. Към момента на писане можете да използвате CLI за разгръщане на MySQL, MariaDB и PostgreSQL клъстери. Нека започнем с пример как да внедрите Percona XtraDB Cluster 5.7. За това е необходима една команда.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitПоследната опция „--wait“ означава, че командата ще изчака, докато задачата приключи, показвайки нейния напредък. Можете да го пропуснете, ако желаете - в този случай командата s9s ще се върне незабавно в shell, след като регистрира ново задание в cmon. Това е напълно добре, тъй като cmon е процесът, който се справя със самата работа. Винаги можете да проверите напредъка на дадена задача отделно, като използвате:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Нека да разгледаме друг пример. Този път ще създадем нов клъстер, MySQL репликация:проста двойка главен - подчинен. Отново, една команда е достатъчна:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdВече можем да проверим дали и двата клъстера работят и работят:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Разбира се, всичко това се вижда и чрез GUI:
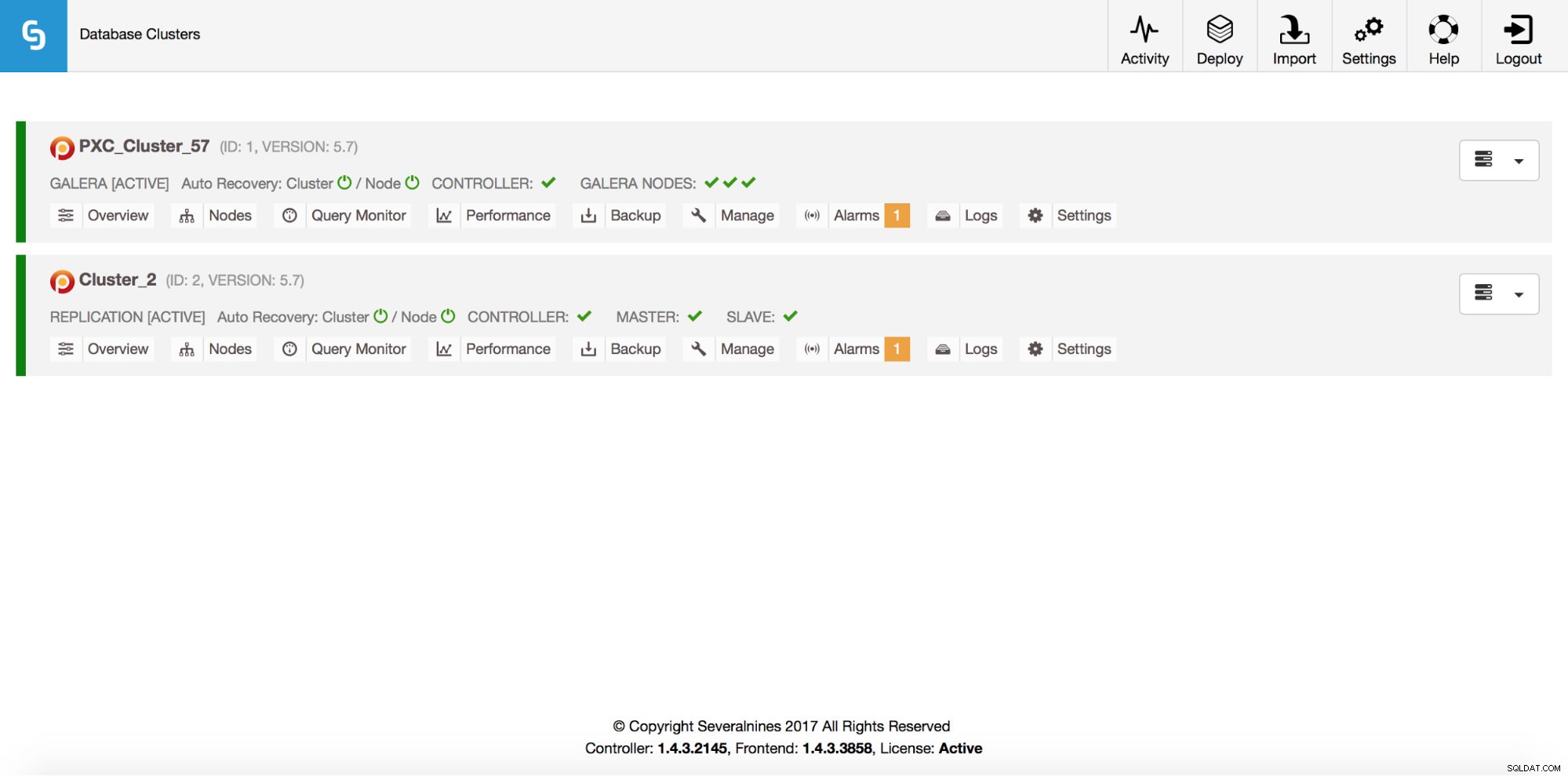
Сега нека добавим ProxySQL loadbalancer:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Този път не използвахме опцията „--wait“, така че, ако искаме да проверим напредъка, трябва да го направим сами. Моля, имайте предвид, че използваме идентификатор на задание, който беше върнат от предишната команда, така че ще получим информация само за тази конкретна работа:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Намаляване
Възлите могат да бъдат добавени към нашия клъстер Galera чрез една команда:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Нещо се обърка. Можем да проверим какво точно се е случило:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Да, този IP вече се използва за нашия сървър за репликация. Трябваше да използваме друг, безплатен IP. Нека опитаме това:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Управление
Да кажем, че искаме да направим резервно копие на нашия главен код за репликация. Можем да направим това от GUI, но понякога може да се наложи да го интегрираме с външни скриптове. ClusterControl CLI би бил идеален за такъв случай. Нека проверим какви клъстери имаме:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2След това нека проверим хостовете в нашия клъстер за репликация с идентификатор на клъстер 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningКакто виждаме, има три хоста, за които ClusterControl знае - два от тях са MySQL хостове (10.0.0.229 и 10.0.0.230), третият е самият екземпляр на ClusterControl. Нека отпечатаме само съответните MySQL хостове:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3В колоната „STAT“ можете да видите някои знаци там. За повече информация предлагаме да разгледате страницата с ръководството за s9s-nodes (man s9s-nodes). Тук просто ще обобщим най-важните части. Първият знак ни разказва за типа на възела:"s" означава, че това е обикновен MySQL възел, "c" - ClusterControl контролер. Вторият знак описва състоянието на възела:„o“ ни казва, че е онлайн. Трети знак - роля на възела. Тук “M” описва главен, а “S” - подчинен, докато “C” означава контролер. Последният, четвърти знак ни казва дали възелът е в режим на поддръжка. „-“ означава, че няма планирана поддръжка. В противен случай ще видим "M" тук. И така, от тези данни можем да видим, че нашият господар е хост с IP:10.0.0.229. Нека направим негово резервно копие и да го съхраним на контролера.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okСлед това можем да проверим дали наистина е приключило добре. Моля, обърнете внимание на опцията “--backup-format”, която ви позволява да дефинирате коя информация трябва да бъде отпечатана:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Наблюдение
Всички бази данни трябва да бъдат наблюдавани. ClusterControl използва съветници, за да наблюдава някои от показателите както на MySQL, така и на операционната система. Когато дадено условие е изпълнено, се изпраща уведомление. ClusterControl също така предоставя обширен набор от графики, както в реално време, така и исторически такива за планиране след смъртта или капацитет. Понякога би било чудесно да имате достъп до някои от тези показатели, без да се налага да преминавате през GUI. ClusterControl CLI го прави възможно чрез командата s9s-node. Информация как да направите това може да бъде намерена в страницата с ръководството на s9s-node. Ще покажем някои примери за това, което можете да правите с CLI.
Първо, нека да разгледаме опцията „--node-format“ към командата „s9s node“. Както можете да видите, има много опции за отпечатване на интересно съдържание.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningС това, което показахме тук, вероятно можете да си представите някои случаи за автоматизация. Например, можете да наблюдавате използването на процесора на възлите и ако достигне някакъв праг, можете да изпълните друга задача на s9s, за да завъртите нов възел в клъстера Galera. Можете също така например да наблюдавате използването на паметта и да изпращате сигнали, ако премине някакъв праг.
CLI може да направи повече от това. На първо място, възможно е да проверите графиките от командния ред. Разбира се, те не са толкова богати на функции, колкото графиките в графичния интерфейс, но понякога е достатъчно просто да видите графика, за да намерите неочакван модел и да решите дали си струва допълнително проучване.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231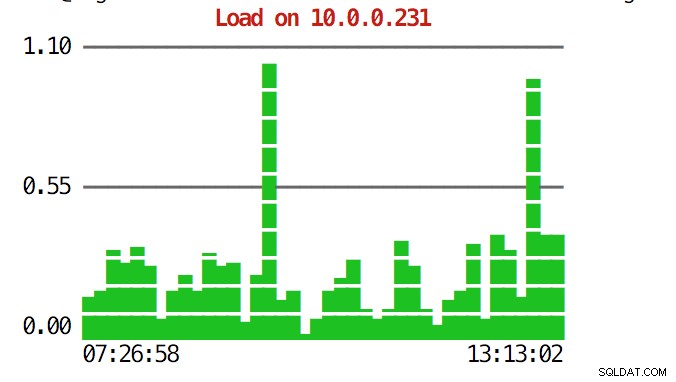
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231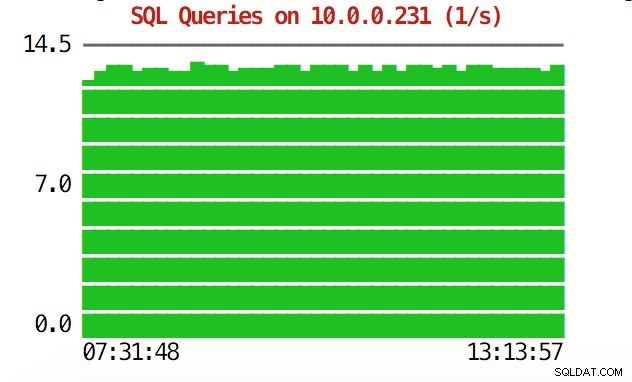
По време на извънредни ситуации може да искате да проверите използването на ресурсите в клъстера. Можете да създадете изход, подобен на върха, който комбинира данни от всички възли на клъстера:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HКогато погледнете горната част, ще видите статистически данни за процесора и паметта, обобщени в целия клъстер.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,По-долу можете да намерите списъка с процеси от всички възли в клъстера.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldТова може да бъде изключително полезно, ако трябва да разберете какво причинява натоварването и кой възел е най-засегнат.
Надяваме се, че CLI инструментът ви улеснява при интегрирането на ClusterControl с външни скриптове и инструменти за оркестриране на инфраструктурата. Надяваме се, че ще ви хареса да използвате този инструмент и ако имате някакви отзиви за това как да го подобрите, не се колебайте да ни уведомите.