Galera Cluster, с неговата (практически) синхронна репликация, обикновено се използва в много различни видове среди. Мащабирането му чрез добавяне на нови възли не е трудно (или също толкова просто с няколко щраквания, когато използвате ClusterControl).
Основният проблем със синхронната репликация е синхронната част, която често води до това, че целият клъстер е толкова бърз, колкото най-бавния му възел. Всяка запис, извършена в клъстер, трябва да бъде репликирана на всички възли и сертифицирана върху тях. Ако по някаква причина този процес се забави, това може сериозно да повлияе на способността на клъстера да приема записи. След това ще започне контрол на потока, това е с цел да се гарантира, че най-бавният възел все още може да се справи с натоварването. Това го прави доста трудно за някои от често срещаните сценарии, които се случват в реална среда.
Първо, нека обсъдим географско разпределеното възстановяване при бедствия. Разбира се, можете да изпълнявате клъстери в широкообхватна мрежа, но увеличената латентност ще окаже значително влияние върху производителността на клъстера. Това сериозно ограничава възможността за използване на такава настройка, особено на по-дълги разстояния, когато латентността е по-голяма.
Друг доста често срещан случай на използване - тестова среда за надграждане на основна версия. Не е добра идея да смесвате различни версии на възлите на MariaDB Galera Cluster в един и същ клъстер, дори ако е възможно. От друга страна, миграцията към по-новата версия изисква подробни тестове. В идеалния случай и четенето, и записът биха били тествани. Един от начините да постигнете това е да създадете отделен клъстер на Galera и да стартирате тестовете, но бихте искали да стартирате тестове в среда, възможно най-близка до производствената. Веднъж осигурен, клъстерът може да се използва за тестове със заявки от реалния свят, но би било трудно да се генерира работно натоварване, което да е близко до това на производството. Не можете да преместите част от производствения трафик към такава тестова система, защото данните не са актуални.
И накрая, самата миграция. Отново, това, което казахме по-рано, дори ако е възможно да се смесват стари и нови версии на възлите на Galera в един и същ клъстер, това не е най-сигурният начин да го направите.
За щастие, най-простото решение за всичките тези три проблема би било свързването на отделни клъстери на Galera с асинхронна репликация. Какво го прави толкова добро решение? Е, той е асинхронен, което го прави да не засяга репликацията на Galera. Няма контрол на потока, така че производителността на „главния“ клъстер няма да бъде повлияна от производителността на „подчинения“ клъстер. Както при всяка асинхронна репликация, може да се появи забавяне, но докато остава в приемливи граници, може да работи перфектно. Също така трябва да имате предвид, че в днешно време асинхронната репликация може да бъде паралелизирана (множество нишки могат да работят заедно, за да увеличат честотната лента) и да намали забавянето на репликацията още повече.
В тази публикация в блога ще обсъдим какви са стъпките за разгръщане на асинхронна репликация между MariaDB Galera клъстери.
Как да конфигурирам асинхронна репликация между MariaDB Galera клъстери?
Първо трябва да разположим клъстер. За нашите цели настройваме клъстер с три възела. Ще сведем настройката до минимум, като по този начин няма да обсъждаме сложността на приложението и прокси слоя. Прокси слоят може да бъде много полезен за работа със задачи, за които искате да разгърнете асинхронна репликация - пренасочване на подмножество от трафика само за четене към тестовия клъстер, подпомагане в ситуацията за възстановяване при бедствие, когато "основният" клъстер не е наличен чрез пренасочване на трафик към клъстера DR. Има много прокси сървъри, които можете да опитате, в зависимост от вашите предпочитания – HAProxy, MaxScale или ProxySQL – всички могат да се използват в такива настройки и в зависимост от случая някои от тях може да са в състояние да ви помогнат да управлявате трафика си.
Конфигуриране на изходния клъстер
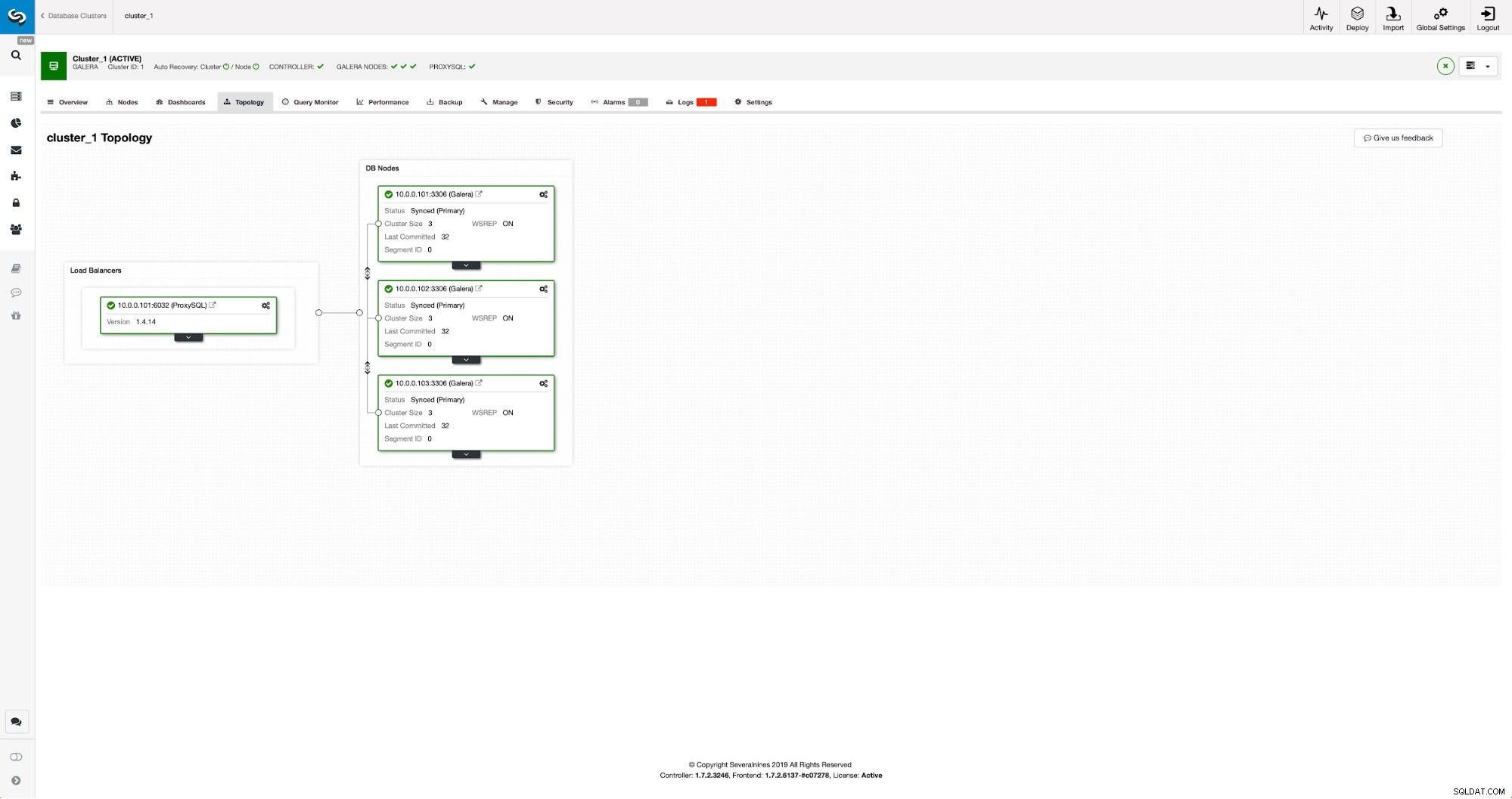
Нашият клъстер се състои от три възела MariaDB 10.3, ние също така внедрихме ProxySQL, за да направи разделянето на четене-запис и да разпредели трафика между всички възли в клъстера. Това не е внедряване от производствен клас, за това ще трябва да разположим повече ProxySQL възли и Keepalived върху тях. Все още е достатъчно за нашите цели. За да настроим асинхронна репликация, ще трябва да имаме активиран двоичен дневник в нашия клъстер. Поне един възел, но е по-добре да го запазите активиран на всички тях, в случай че единственият възел с активиран binlog изпадне – тогава искате да имате друг възел в клъстера да работи и да работи, който да можете да изключите.
Когато активирате двоичен дневник, уверете се, че сте конфигурирали ротацията на двоичния дневник, така че старите регистрационни файлове да бъдат премахнати в даден момент. Ще използвате двоичен формат на дневника ROW. Трябва също така да се уверите, че имате конфигуриран и използван GTID - той ще ви бъде много удобен, когато трябва да подредите отново своя „подчинен“ клъстер или ако трябва да активирате многонишкова репликация. Тъй като това е клъстер на Galera, искате да имате конфигуриран „wsrep_gtid_domain_id“ и активиран „wsrep_gtid_mode“. Тези настройки ще гарантират, че GTID ще бъдат генерирани за трафика, идващ от клъстера Galera. Повече информация можете да намерите в документацията. След като всичко това е направено, можете да продължите с настройката на втория клъстер.
Настройване на целевия клъстер
Като се има предвид, че в момента няма целеви клъстер, трябва да започнем с внедряването му. Няма да разглеждаме тези стъпки подробно, можете да намерите инструкции в документацията. Най-общо казано процесът се състои от няколко стъпки:
- Конфигуриране на хранилища на MariaDB
- Инсталирайте пакети MariaDB 10.3
- Конфигуриране на възли за образуване на клъстер
В началото ще започнем само с един възел. Можете да настроите всички от тях да образуват клъстер, но тогава трябва да ги спрете и да използвате само един за следващата стъпка. Този един възел ще стане роб на оригиналния клъстер. Ще използваме mariabackup, за да го осигурим. След това ще конфигурираме репликацията.
Първо, трябва да създадем директория, където ще съхраняваме архива:
mkdir /mnt/mariabackupСлед това изпълняваме архива и го създаваме в директорията, подготвена в стъпката по-горе. Моля, уверете се, че използвате правилния потребител и парола, за да се свържете с базата данни:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/След това трябва да копираме архивните файлове в първия възел във втория клъстер. Използвахме scp за това, можете да използвате каквото искате - rsync, netcat, всичко, което ще работи.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/След като резервното копие бъде копирано, трябва да го подготвим, като приложим лог файловете:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!В случай на грешка може да се наложи да изпълните отново архивирането. Ако всичко е наред, можем да премахнем старите данни и да ги заменим с информацията за архивиране
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Също така искаме да зададем правилния собственик на файловете:
chown -R mysql.mysql /var/lib/mysql/Ще разчитаме на GTID, за да поддържаме репликацията последователна, така че трябва да видим кой беше последният приложен GTID в този архив. Тази информация може да бъде намерена във файла xtrabackup_info, който е част от архива:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Също така ще трябва да гарантираме, че подчинения възел има активирани двоични регистрационни файлове заедно с „log_slave_updates“. В идеалния случай това ще бъде активирано на всички възли във втория клъстер – само в случай, че „подчинения“ възел се провали и ще трябва да настроите репликацията, като използвате друг възел в подчинения клъстер.
Последният бит, който трябва да направим, преди да можем да настроим репликацията, е да създадем потребител, който ще използваме за стартиране на репликацията:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Това е всичко, от което се нуждаем. Сега можем да стартираме първия възел във втория клъстер, нашия бъдещ роб:
galera_new_clusterСлед като стартира, можем да влезем в MySQL CLI и да го конфигурираме да стане подчинен, използвайки позицията на GITD, която намерихме няколко стъпки по-рано:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)След като това стане, най-накрая можем да настроим репликацията и да я стартираме:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)В този момент имаме клъстер Galera, състоящ се от един възел. Този възел също е подчинен на оригиналния клъстер (по-специално, неговият главен е възел 10.0.0.101). За да се присъединим към други възли, ще използваме SST, но за да работи първо трябва да се уверим, че конфигурацията на SST е правилна - моля, имайте предвид, че току-що сме заменили всички потребители във втория ни клъстер със съдържанието на изходния клъстер. Това, което трябва да направите сега, е да се уверите, че конфигурацията „wsrep_sst_auth“ на втория клъстер съвпада с тази на първия клъстер. След като това стане, можете да започнете да оставате възли един по един и те трябва да се присъединят към съществуващия възел (10.0.0.104), да получат данните през SST и да образуват клъстера Galera. В крайна сметка трябва да се окажете с два клъстера, по три възела всеки, с асинхронна връзка за репликация между тях (от 10.0.0.101 до 10.0.0.104 в нашия пример). Можете да потвърдите, че репликацията работи, като проверите стойността на:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Как да конфигурирате асинхронна репликация между MariaDB Galera клъстери с помощта на ClusterControl?
Към момента на този блог ClusterControl няма функционалност за конфигуриране на асинхронна репликация в множество клъстери, ние работим по него, докато пиша това. Въпреки това ClusterControl може да бъде от голяма помощ в този процес – ние ще ви покажем как можете да ускорите трудоемките ръчни стъпки с помощта на автоматизация, предоставена от ClusterControl.
От това, което показахме по-рано, можем да заключим, че това са общите стъпки, които трябва да предприемете при настройването на репликация между два клъстера Galera:
- Внедряване на нов клъстер Galera
- Осигуряване на нов клъстер с помощта на данни от стария
- Конфигуриране на нов клъстер (SST конфигурация, двоични регистрационни файлове)
- Настройте репликацията между стария и новия клъстер
Първите три точки са нещо, което можете лесно да направите с помощта на ClusterControl дори сега. Ще ви покажем как да направите това.
Разгръщане и предоставяне на нов клъстер MariaDB Galera с помощта на ClusterControl
Първоначалната ситуация е подобна - имаме един клъстер и работи. Трябва да настроим втория. Една от най-новите функции на ClusterControl е опцията за разгръщане на нов клъстер и предоставянето му с помощта на данните от архивиране. Това е много полезно за създаване на тестови среди, също така е опция, която ще използваме, за да осигурим новия ни клъстер за настройката за репликация. Затова първата стъпка, която ще предприемем, е да създадем резервно копие с помощта на mariabackup:
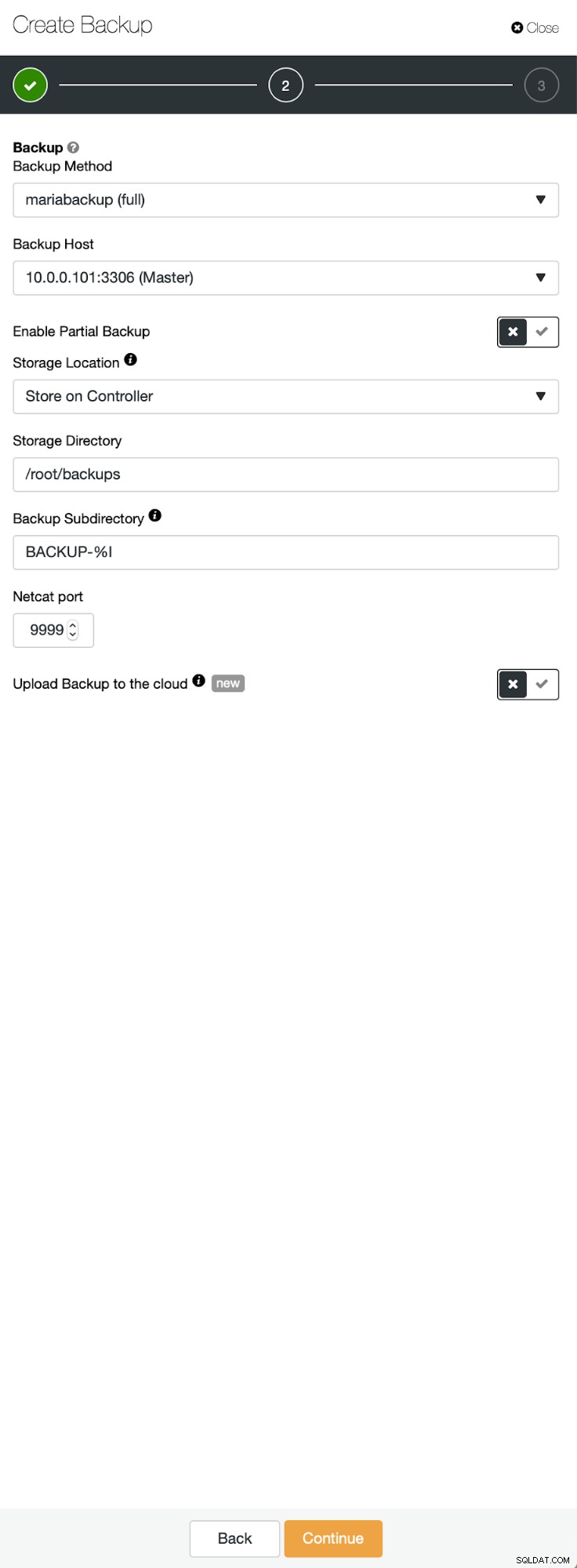
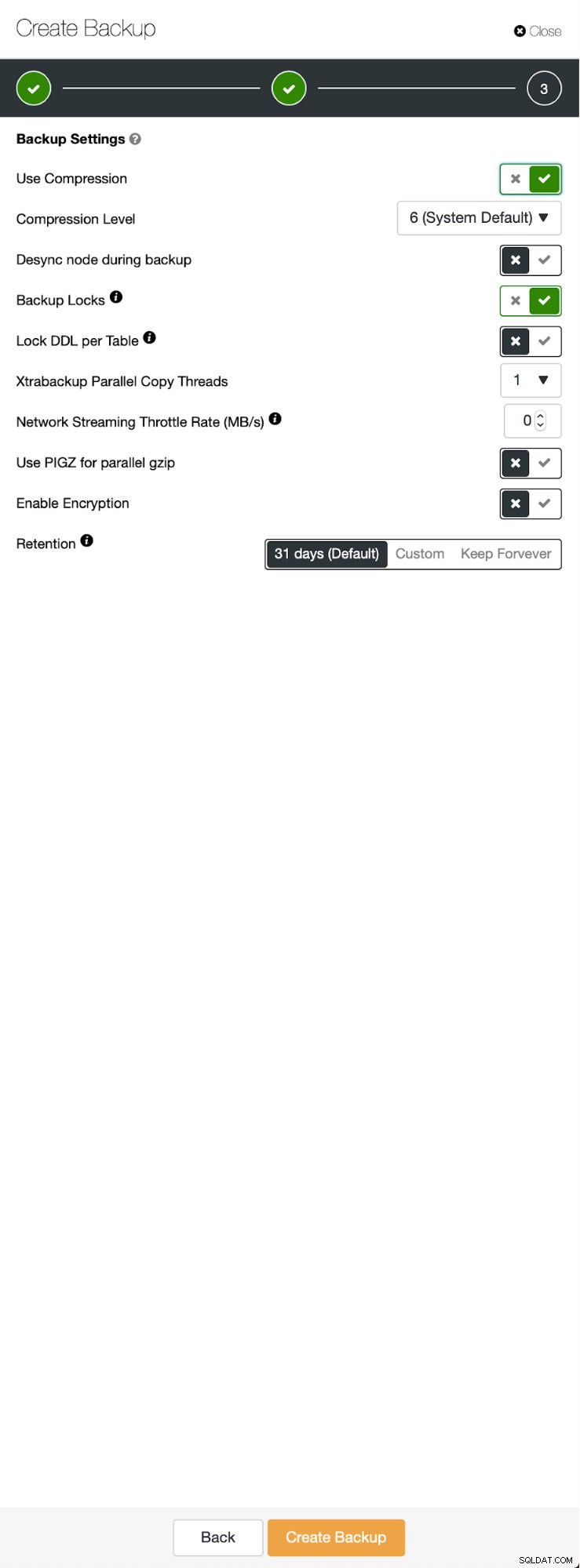
Три стъпки, в които избрахме възела, за да свалим резервното копие от него. Този възел (10.0.0.101) ще стане главен. Трябва да има активирани двоични регистрационни файлове. В нашия случай всички възли имат активиран binlog, но ако не са го направили, е много лесно да го активирате от ClusterControl - ще покажем стъпките по-късно, когато ще го направим за втория клъстер.
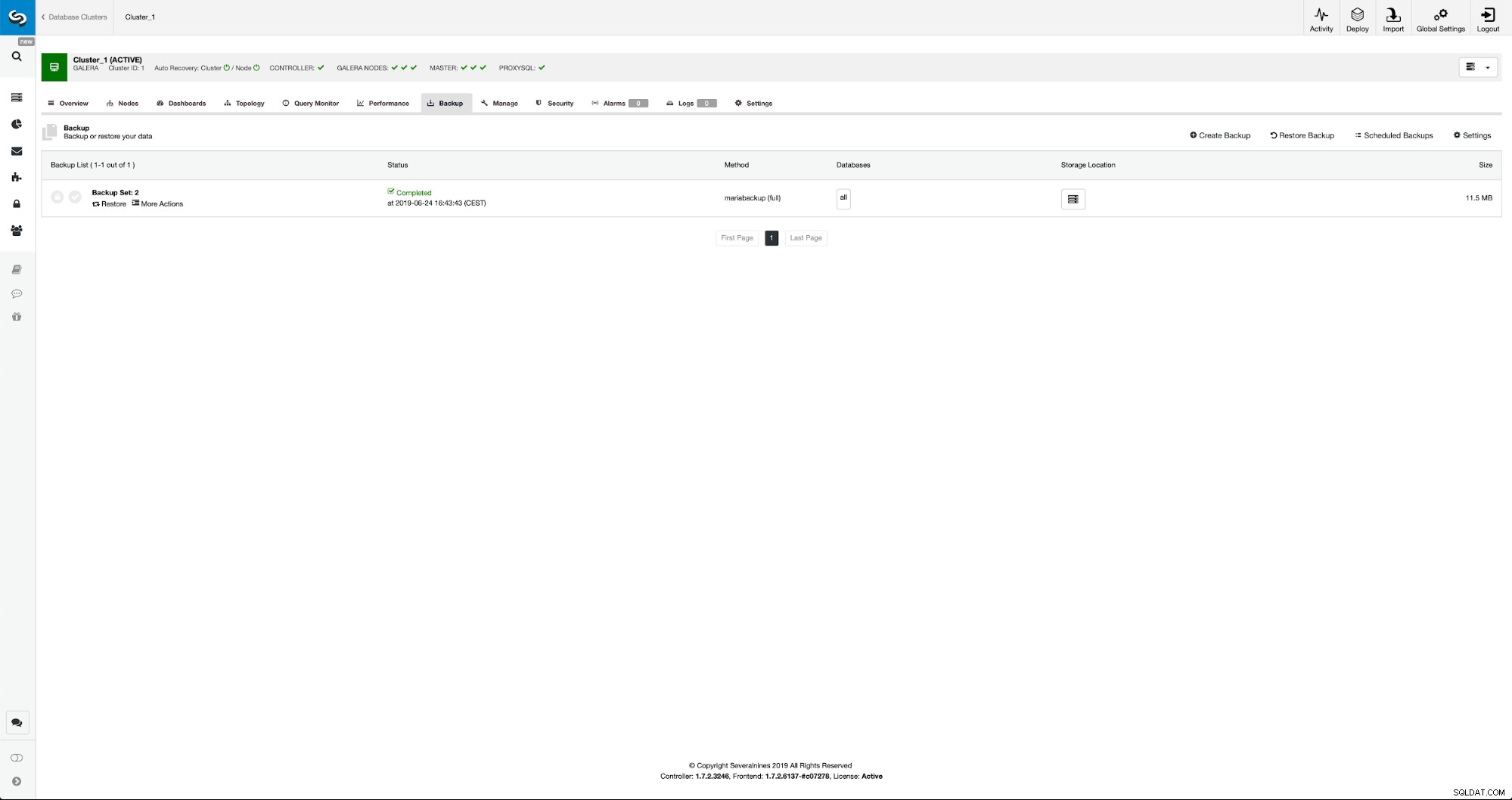
След като архивирането приключи, то ще стане видимо в списъка. След това можем да продължим и да го възстановим:

Ако искаме това, бихме могли дори да направим възстановяване по време на време, но в нашия случай това няма особено значение:след като репликацията бъде конфигурирана, всички необходими транзакции от binlogs ще бъдат приложени към новия клъстер.

След това избираме опцията за създаване на клъстер от архива. Това отваря друг диалогов прозорец:
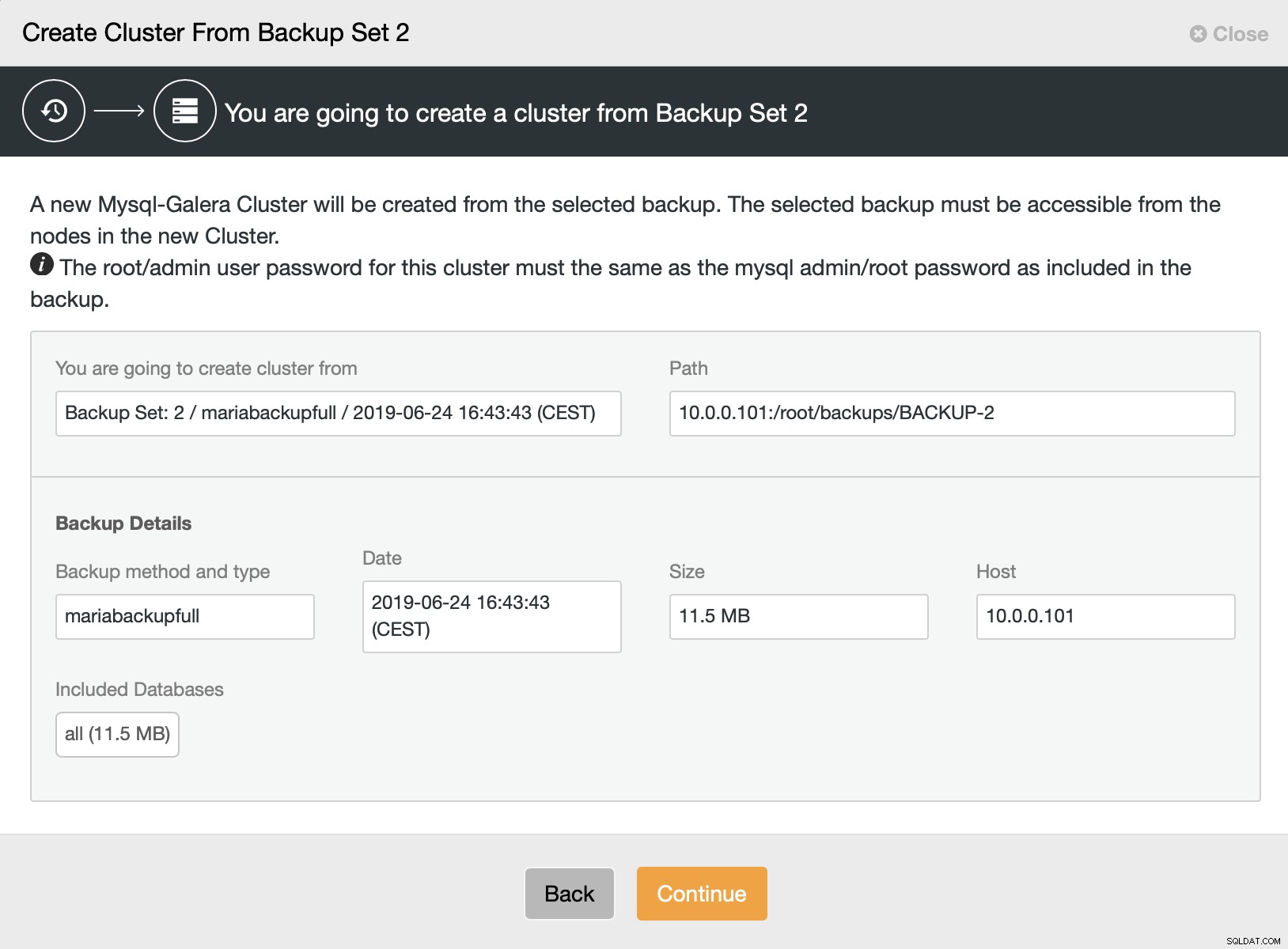
Това е потвърждение кой архив ще се използва, от кой хост е взето архивирането, какъв метод е използван за създаването му и някои метаданни, които да помогнат да се провери дали архивът изглежда здрав.
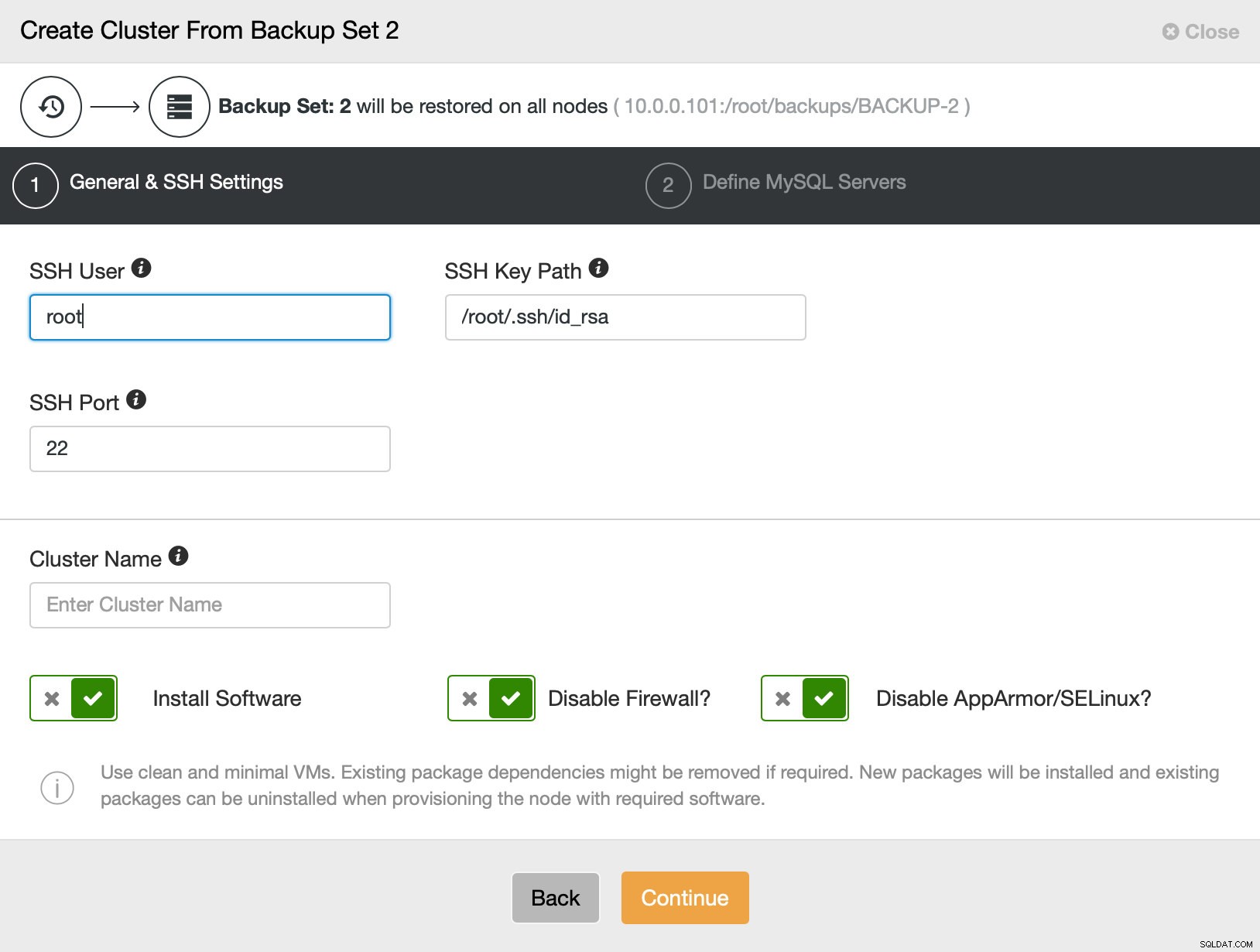
След това основно отиваме към обикновения съветник за внедряване, в който трябва да дефинираме SSH свързаност между хост ClusterControl и възлите, на които да разгръщаме клъстера (изискването за ClusterControl) и във втората стъпка, доставчик, версия, парола и възли за разгръщане на:
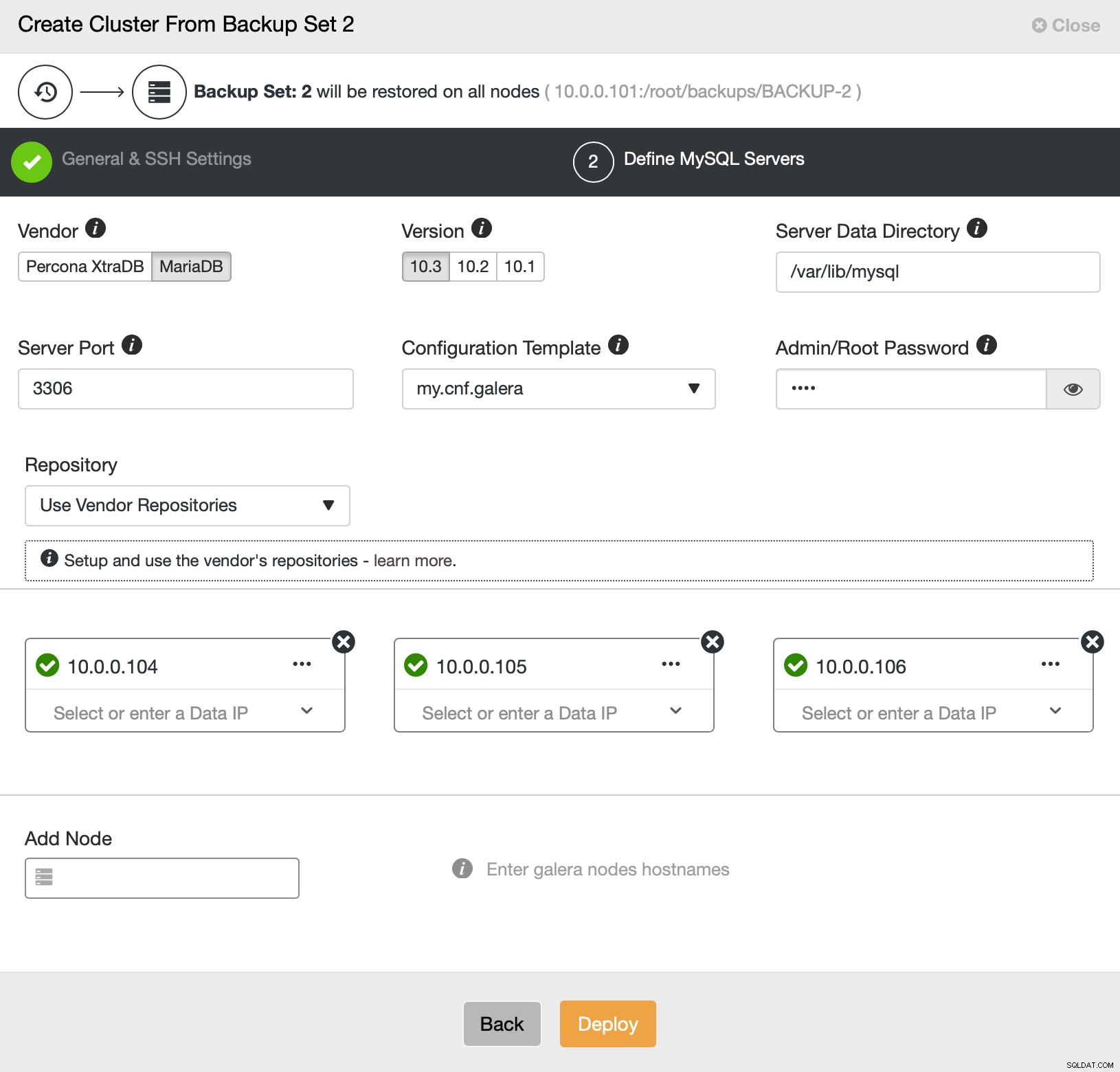
Това е всичко по отношение на разполагането и обезпечаването. ClusterControl ще настрои новия клъстер и ще го осигури, използвайки данните от стария.
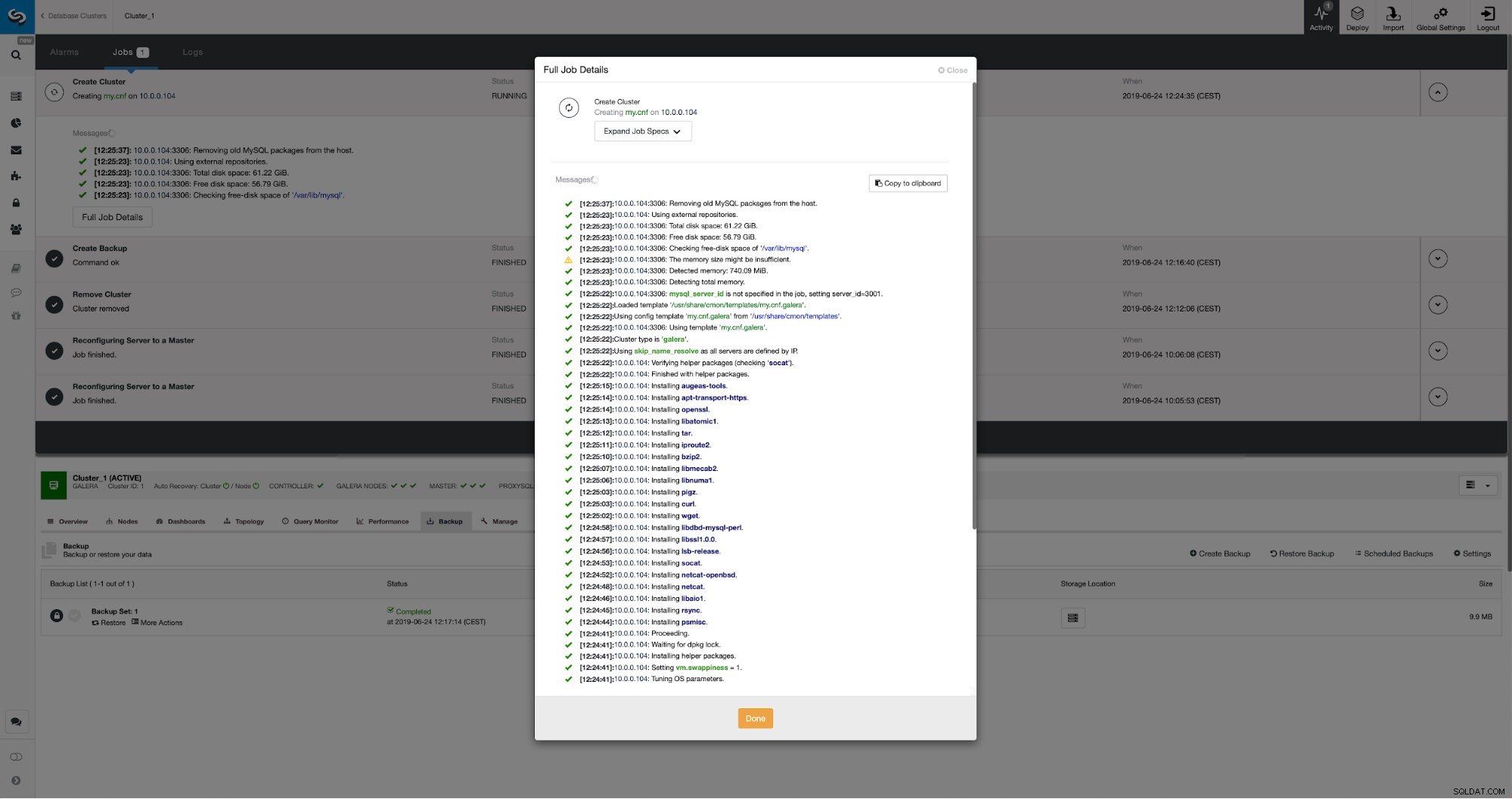
Можем да наблюдаваме напредъка в раздела активност. След като бъде завършен, вторият клъстер ще се покаже в списъка с клъстери в ClusterControl.
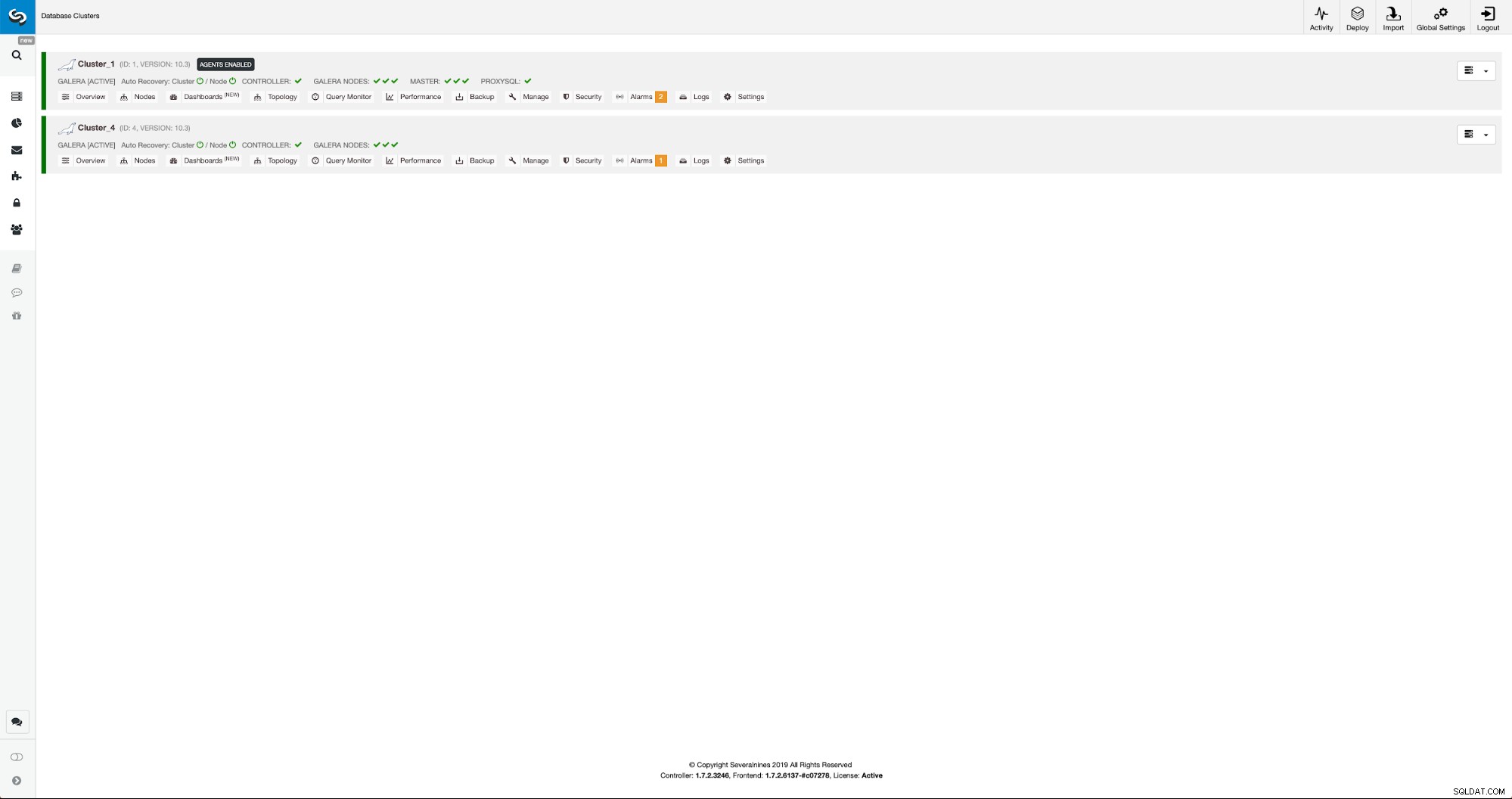
Преконфигуриране на новия клъстер с помощта на ClusterControl
Сега трябва да преконфигурираме клъстера - ще активираме двоични регистрационни файлове. В ръчния процес трябваше да направим промени в конфигурацията wsrep_sst_auth, както и в конфигурационните записи в секциите [mysqldump] и [xtrabackup] на конфигурацията. Тези настройки могат да бъдат намерени във файла secrets-backup.cnf. Този път не е необходимо, тъй като ClusterControl генерира нови пароли за клъстера и конфигурира файловете правилно. Това, което е важно да имате предвид обаче, ако промените паролата на потребителя 'backupuser'@'127.0.0.1' в оригиналния клъстер, ще трябва да направите промени в конфигурацията и във втория клъстер, за да отразите това като промени в първият клъстер ще се репликира във втория клъстер.
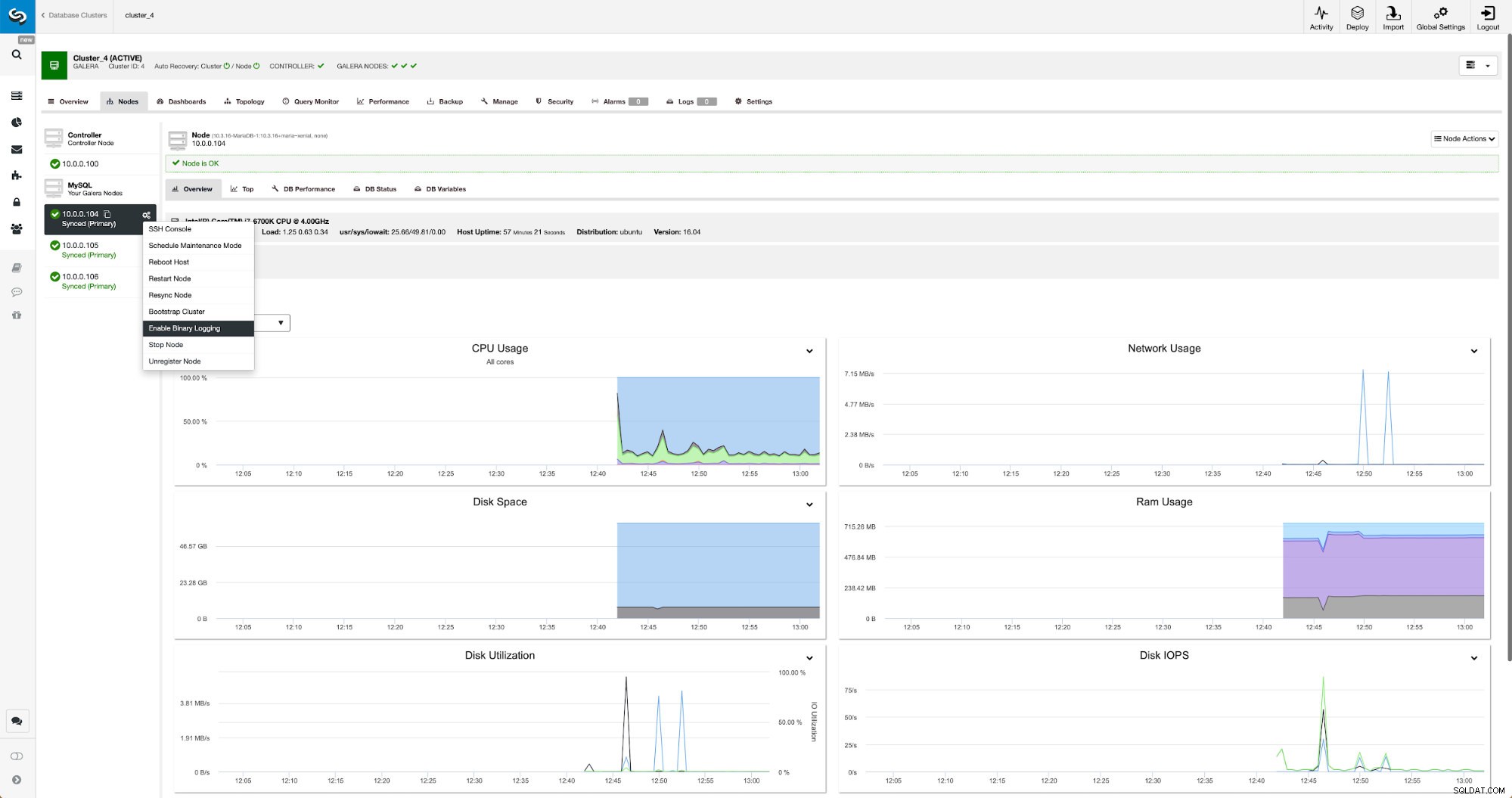
Двоичните регистрационни файлове могат да бъдат активирани от секцията Възли. Трябва да изберете възел по възел и да стартирате задание „Активиране на двоично регистриране“. Ще ви бъде представен диалогов прозорец:
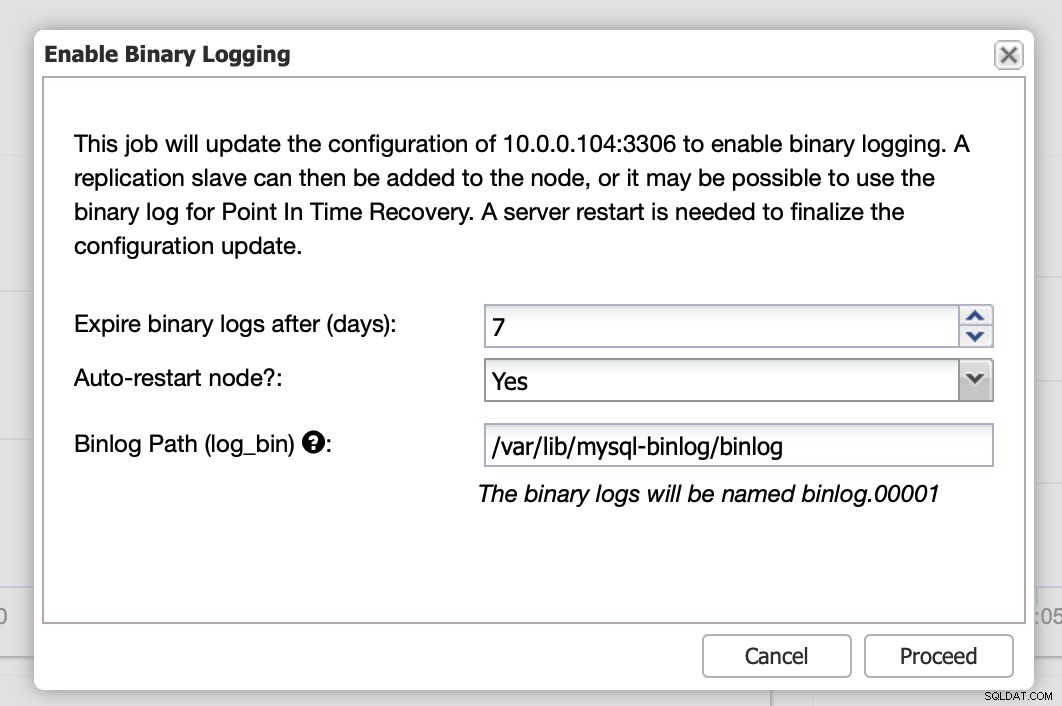
Тук можете да дефинирате колко дълго искате да съхранявате регистрационните файлове, къде трябва да се съхраняват и ако ClusterControl трябва да рестартира възела, за да приложите промените - конфигурацията на двоичния дневник не е динамична и MariaDB трябва да се рестартира, за да приложи тези промени.
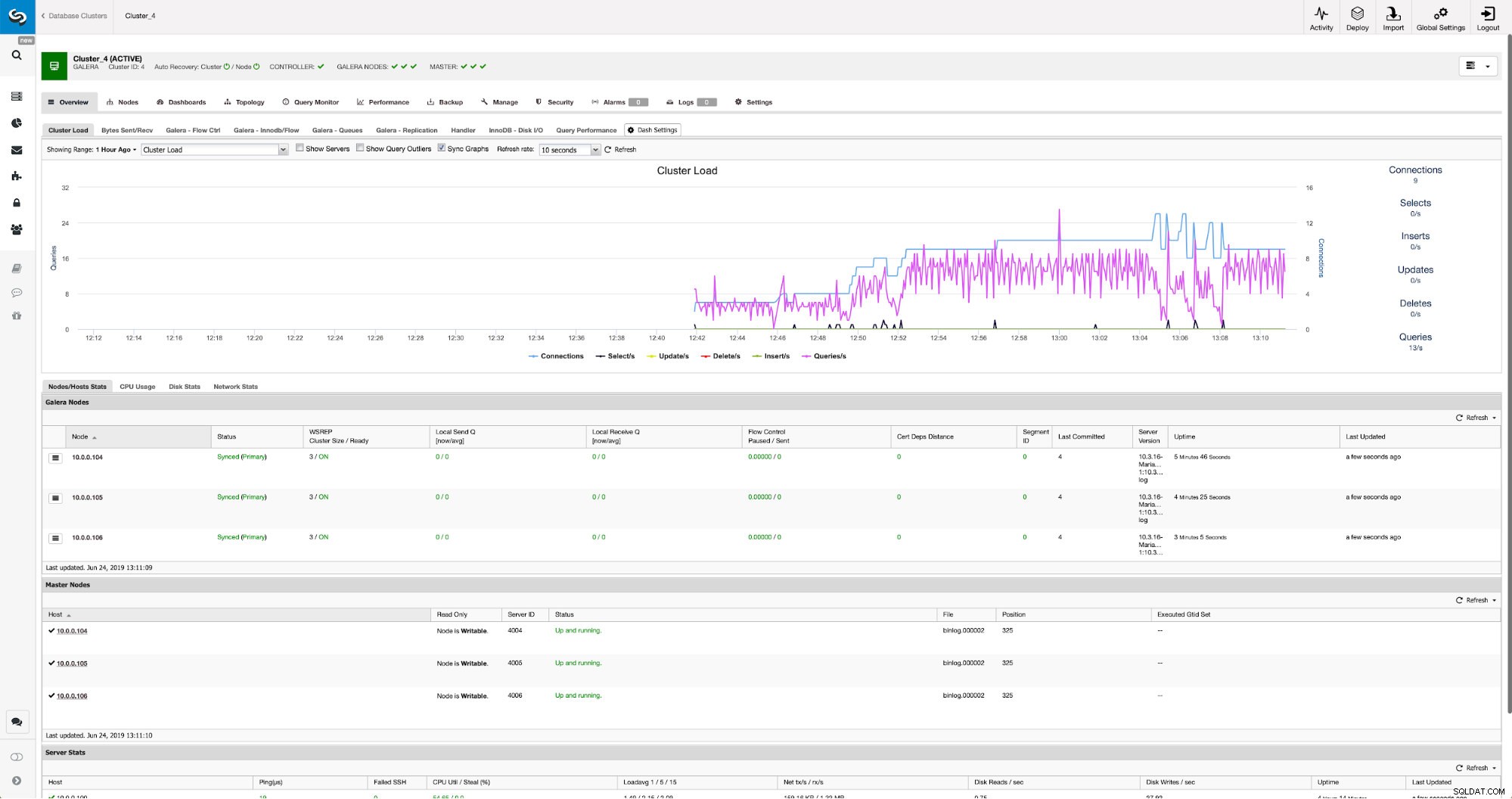
Когато промените завършат, ще видите всички възли, маркирани като „главни“, което означава, че тези възли имат активиран двоичен журнал и могат да действат като главен.
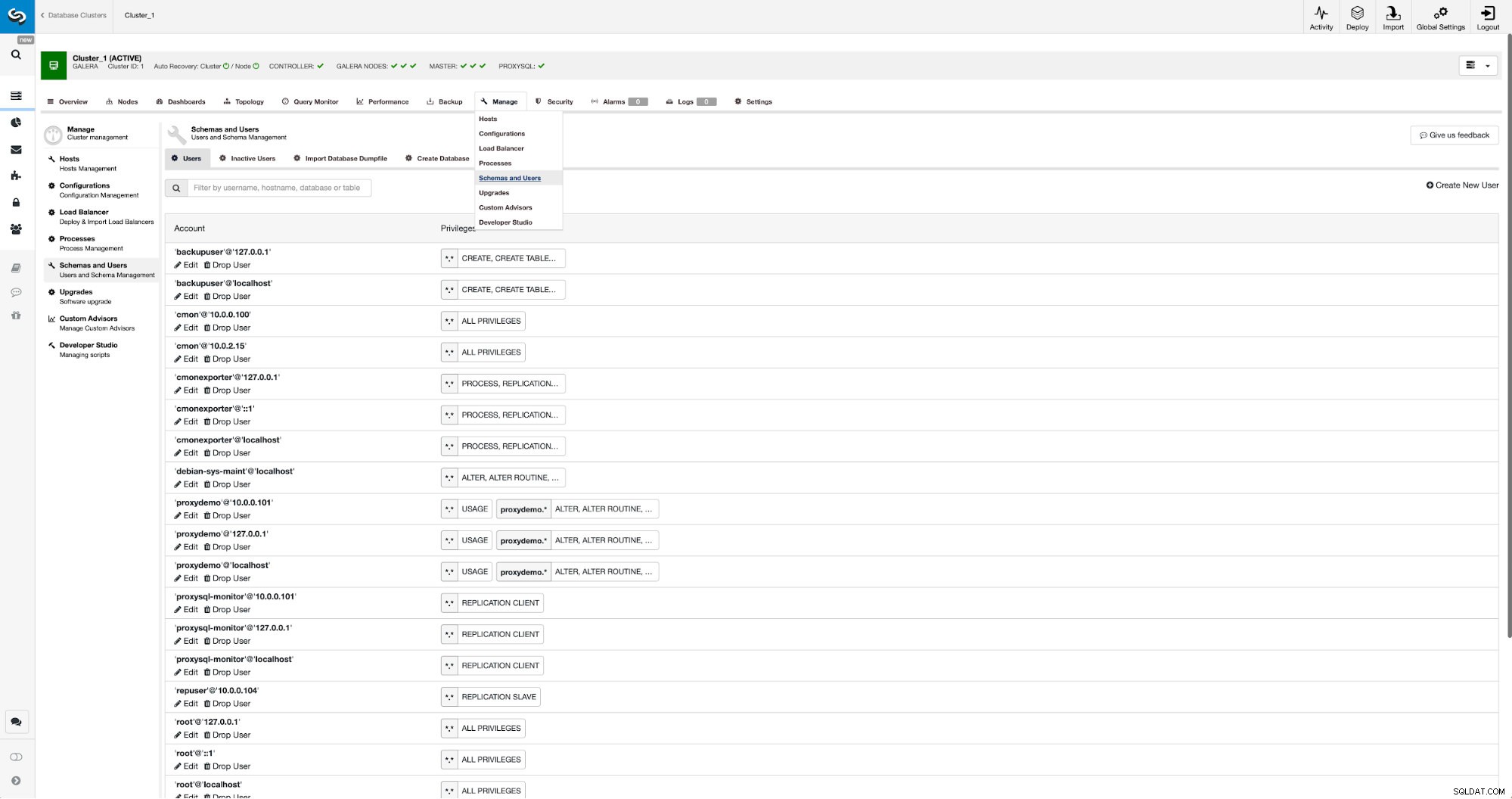
Ако вече нямаме създаден потребител за репликация, трябва да го направим. В първия клъстер трябва да отидем на Управление -> Схеми и потребители:
От дясната страна имаме опция за създаване на нов потребител:
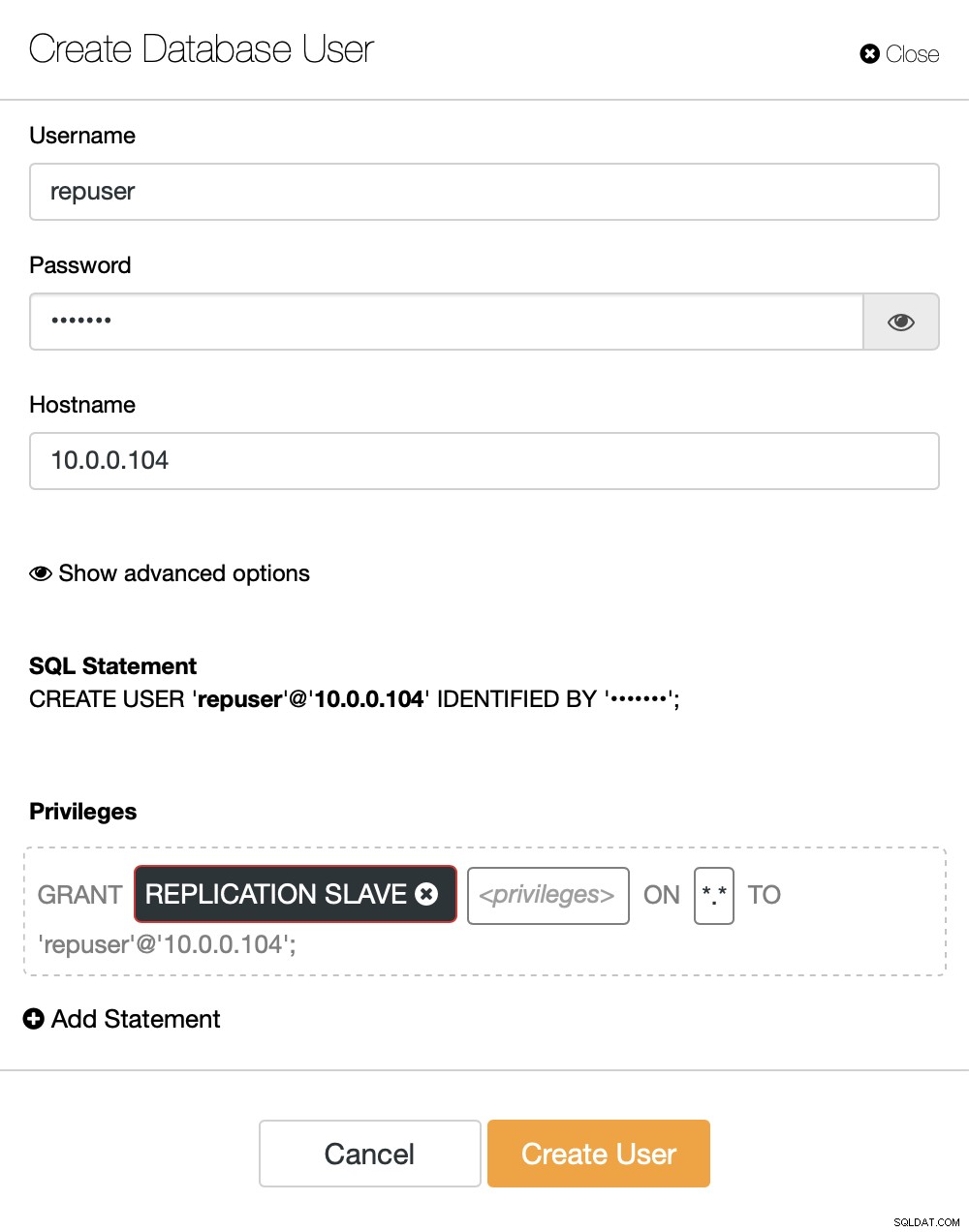
Това приключва конфигурацията, необходима за настройка на репликацията.
Настройване на репликация между клъстери с помощта на ClusterControl
Както казахме, работим по автоматизирането на тази част. В момента това трябва да се направи ръчно. Както може би си спомняте, имаме нужда от GITD позиция на нашия архив и след това да изпълним няколко команди с помощта на MySQL CLI. Данните за GTID са налични в архива. ClusterControl създава архивиране с помощта на xbstream/mbstream и го компресира след това. Нашето резервно копие се съхранява на хоста ClusterControl, където нямаме достъп до двоичен файл mbstream. Можете да опитате да го инсталирате или можете да копирате архивния файл на местоположението, където е наличен такъв двоичен файл:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/След като това стане, на 10.0.0.104 искаме да проверим съдържанието на файла xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Накрая конфигурираме репликацията и я стартираме:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Това е всичко - току-що конфигурирахме асинхронна репликация между два клъстера MariaDB Galera с помощта на ClusterControl. Както можете да видите, ClusterControl успя да автоматизира повечето от стъпките, които трябваше да предприемем, за да настроим тази среда.